Cancer Survival Rates Are Misleading
UPDATE: I submitted a more formal version of this article to the UMAP Journal (Undergraduate Mathematics and Its Applications), which publishes articles that use mathematical modeling for real-world problems, often with a pedagogical or expository angle. A preprint is available on arXiv at: https://arxiv.org/abs/2603.19945
Five-year survival might be the most misleading statistic in medicine. For example, suppose 5-year survival for a hypothetical cancer is
- 91% among patients diagnosed early, while the tumor is localized at the primary site,
- 74% among patients diagnosed later, when the tumor has spread regionally to nearby lymph nodes or adjacent organs, and
- 16% among patients diagnosed late, when the tumor has spread to distant organs or lymph nodes.
What can we infer from these statistics?
- If a patient is diagnosed early, it is tempting to think the probability is 91% that they will survive five years after diagnosis.
- Looking at the difference in survival between early and late detection, it is tempting to conclude that more screening would save lives.
- In a case where a patient is diagnosed late and dies of cancer, it is tempting to say that they would have survived if their cancer had been caught early.
- And if 5-year survival increases over time, it is tempting to conclude that treatment has improved.
In fact, none of these inferences are correct.
Let’s take them one at a time.
Particularization
Here’s the first incorrect inference:
If a patient is diagnosed early, and 5-year survival is 91%, it is tempting to think the probability is 91% that they will survive five years after diagnosis.
This is almost correct in the sense that it applies to the past cases that were used to estimate the survival rate – of all patients in the dataset who were diagnosed early, 91% of them survived at least five years.
But it is misleading for two reasons:
- Because it is based on past cases, it doesn’t apply to present cases if (1) the effectiveness of treatment has changed or – often more importantly – (2) diagnostic practices have changed.
- Also, before interpreting a probability like this, which applies in general, it is important to particularize it for a specific case.
Factors that should be taken into account include the general health of the patient, their age, and the mode of detection. Some factors are causal – for example, general health directly improves the chance of survival. Other factors are less obvious because they are informational – for example, the mode of detection can make a big difference:
- If a tumor is discovered because it is causing symptoms, it is more likely to be larger, more aggressive, and relatively late for a given stage – and all of those implications decrease the chance of survival.
- If a tumor is not symptomatic, but discovered during a physical exam, it is probably larger, later, and more likely to cause mortality, compared to one discovered by high resolution imaging or a sensitive chemical test.
- Conversely, tumors detected by screening are more likely to be slow-growing because of length-biased sampling – the probability of detection depends on the time between when a tumor is detectable and when it causes symptoms.
Taking age into account is complicated because it might be both causal and informational, with opposite implications. A young patient might be more robust and able to tolerate treatment, but a tumor detectable in a younger person is likely to have progressed more quickly than one that could only be discovered after more years of life. So the implication of age might be negative among the youngest and oldest patients, and positive in the middle-aged.
For some cancers, the magnitude of these implications is large, so the probability of 5-year survival for a particular patient might be higher than 91% or much lower.
Is More Screening Better?
Now let’s consider the second incorrect inference.
If 5-year survival is high when a cancer is detected early and much lower when it is detected late, it is tempting to conclude that more screening would save lives.
For example, in a recent video, Nassim Taleb and Emi Gal discuss the pros and cons of cancer screening, especially full-body MRIs for people who have no symptoms. At one point they consider this table of survival rates based on stage at diagnosis:

They note that survival is highest if a tumor is detected while localized at the primary site, lower if it has spread regionally, and often much lower if it has spread distantly.
They take this as evidence that screening for these cancers is beneficial. For example, at one point Taleb says, “Look at the payoff for pancreatic cancer – 10 times the survival rate.”
And Gal adds, “Colon cancer, it’s like seven times… The overarching insight is that you want to find cancer early… This table makes the case for the importance of finding cancer early.”
Taleb agrees, but this inference is incorrect: This table does not make the case that it is better to catch cancer early.
Catching cancer early is beneficial only if (1) the cancers we catch would otherwise cause disease and death, and (2) we have treatments that prevent those outcomes, and (3) these benefits outweigh the costs of additional screening. This table does not show that any of those things is true.
In fact, it is possible for a cancer to reproduce any row in this table, even if we have no treatment and detection has no effect on outcomes. To demonstrate, I’ll use a model of tumor progression to show that a hypothetical cancer could have the same survival rates as colon cancer – even if there is no effective treatment at all.
To be clear, I’m not saying that cancer treatment is not effective – in many cases we know that it is. I’m saying that we can’t tell, just looking at a survival rates, whether early detection has any benefit at all.
Markov Model
The details of the model are here and you can click here to run my analysis in a Jupyter notebook on Colab.
We’ll model tumor progression using a Markov chain with these states:
U1,U2, andU3represent tumors that are undetected at each stage: local, regional, and distant.D1,D2,D3represent tumors that were detected/diagnosed at each stage.- And
Mrepresents mortality.
The following figure shows the states and transition rates of the model.
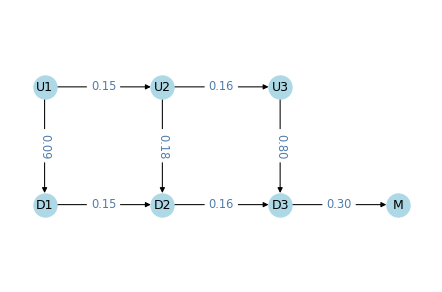
The transition probabilities are:
lams, two values that represent transition rates between stages,kappas, three values that represent detection rates at each state,muthe mortality rate fromD3,gammathe effectiveness of treatment.
If gamma > 0, the treatment is effective by decreasing the probability of progression to the next stage. In the models we’ll run for this example, gamma=0, which means that detection has no effect on progression.
Overall, these values are within the range we observe in real cancers.
- The transition rates are close to 1/6, which means the average time at each stage is 6 simulated years.
- The detection rate is low at the first stage, higher at the second, and much higher at the third.
- The mortality rate is close to 1/3, so the average survival after diagnosis at the third stage is about 3 years.
In this model, death occurs only after a cancer has progressed to the third stage and been detected. That’s not realistic – in reality deaths can occur at any stage, due to cancer or other causes.
But adding more transitions would not make make the model better. The purpose of the model is to show that we can reproduce the survival rates we see in reality, even if there are no effective treatments. Making the model more realistic would increase the number of parameters, which would make it easier to reproduce the data, but that would not make the conclusion stronger. More realistic models are not necessarily better.
Results
We can simulate this model to compute survival rates and the distribution of stage at diagnosis
- In the model, survival rates are 95% if localized, 72% if spread regionally, and 17% if spread distantly. For colon cancer, the rates from the SEER data are are 91%, 74%, and 16%. So the simulation results are not exactly the same, but they are close.
- In the model, 38% of tumors are localized when diagnosed, 33% have spread regionally, and 29% have spread distantly. The actual distribution for colon cancer is 38%, 38%, and 24%. Again, the simulation results are not exactly the same, but close.
With more trial and error, I could probably find parameters that reproduce the results exactly. That would not be surprising, because even though the model is meant to be parsimonious, it has seven parameters and we are matching observations with only five degrees of freedom.
That might seem unfair, but it makes the point that there is not enough information in the survival table – even if we also consider the distribution of stages – to estimate the parameters of the model precisely. The data don’t exclude the possibility that treatment is ineffective, so they don’t prove that early detection is beneficial.
Again, it might be better to find cancer early, if the benefit of treatment outweighs the costs of false discovery and overdiagnosis – but that’s a different analysis, and 5-year survival rates aren’t part of it.
That’s why this editorial concludes, “Only reduced mortality rates can prove that screening saves lives… journal editors should no longer allow misleading statistics such as five year survival to be reported as evidence for screening.”
Counterfactuals
Now let’s consider the third incorrect inference.
In a case where a patient is diagnosed late and dies of cancer, it is tempting to say that they would have survived if their cancer had been caught early.
For example, later in the previous video, Taleb says, “Your mother, had she had a colonoscopy, she would be alive today… she’s no longer with us because it was detected when it was stage IV, right?” And Gal agrees.
That might be true, if treatment would have prevented the cancer from progressing. But this conclusion is not supported by the data in the survival table.
If someone is diagnosed late and dies, it is tempting to look at the survival table and think there’s a 91% chance they would have survived if they had been diagnosed earlier. But that’s not accurate – and it might not even be close.
First, remember what 91% survival means: among people diagnosed early, 91% survived five years after diagnosis. But among those survivors, an unknown proportion had tumors that would not have been fatal, even without treatment. Some might be non-progressive, or progress so slowly that they never cause disease or death. But in a case where the patient dies of cancer, we know their tumor was not one of those.
As a simplified example, suppose that of all tumors that are caught early, 50% would cause death within five years, if untreated, and 50% would not. Now imagine 100 people, all detected early and all treated: 50 would survive with or without treatment; out of the other 50, 41 survive with treatment – so overall survival is 91%. But if we know someone is in the second group, their chance of survival is 41/50, which is 82%.
And if the percentage of non-progressive cancers is higher than 50%, the survival rate for progressive cancers is even lower, holding overall survival constant. So that’s one reason the inference is incorrect.
To see the other reason, let’s be precise about the counterfactual scenario. Suppose someone was diagnosed in 2020 with a tumor that had spread distantly, and they died in 2022. Would they be alive in 2025 if they had been diagnosed earlier?
That depends on when the hypothetical diagnosis happens – if we imagine they were diagnosed in 2020, five year survival might apply (except for the previous point). But if it had spread distantly in 2020, we have to go farther back in time to catch it early. For example, if it took 10 years to progress, catching it early means catching it in 2010. In that case, being “alive today” would depend on 15-year survival, not 5-year.
It’s a Different Question
The five-year survival rate answers the question, “Of all people diagnosed early, how many survive five years?” That is a straightforward statistic to compute.
But the hypothetical asks a different question: “Of all people who died [during a particular interval] after being diagnosed late, how many would be alive [at some later point] if the tumor had been detected early?” That is a much harder question to answer – and five-year survival provides little or no help.
In general, we don’t know the probability that someone would be alive today, if they had been diagnosed earlier. Among other things, it depends on progression rates with and without treatment.
- If many of the tumors caught early would not have progressed or caused death, even without treatment, the counterfactual probability would be low.
- In any case, if treatment is ineffective, as in the hypothetical cancer we simulated, the counterfactual probability is zero.
- At the other extreme, if treatment is perfectly effective, the probability is 100%.
It might be frustrating that we can’t be more specific about the probability of the counterfactual, but if someone you know was diagnosed late and died, and it bothers you to think they would have lived if they had been diagnosed earlier, it might be some comfort to realize that we don’t know that – and it could be unlikely.
Comparing Survival Rates
Now let’s consider the last incorrect inference.
If 5-year survival increases over time, it is tempting to conclude that treatment has improved.
This conclusion is appealing because if cancer treatment improves, survival rates improve, other things being equal. But if we do more screening and catch more cancers early, survival rates improve even if treatment is no more effective. And if screening becomes more sensitive, and detects smaller tumors, survival rates also improve.
For many cancers, all three factors have changed over time: improved treatment, more screening, and more sensitive screening. Looking only at survival rates, we can’t tell how much change in survival we should attribute to each.
And the answer is different for different sites. For example, this paper concludes:
In some cases, increased survival was accompanied by decreased burden of disease, reflecting true progress. For example, from 1975 to 2010, five-year survival for colon cancer patients improved … while cancer burden fell: Fewer cases … and fewer deaths …, a pattern explained by both increased early detection (with removal of cancer precursors) and more effective treatment. In other cases, however, increased survival did not reflect true progress. In melanoma, kidney, and thyroid cancer, five-year survival increased but incidence increased with no change in mortality. This pattern suggests overdiagnosis from increased early detection, an increase in cancer burden.
And this paper explains:
Screening detects abnormalities that meet the pathological definition of cancer but that will never progress to cause symptoms or death (non-progressive or slow growing cancers). The higher the number of overdiagnosed patients, the higher the survival rate.
It concludes that “Although 5-year survival is a valid measure for comparing cancer therapies in a randomized trial, our analysis shows that changes in 5-year survival over time bear little relationship to changes in cancer mortality. Instead, they appear primarily related to changing patterns of diagnosis.”
That conclusion might be stated too strongly. This response paper concludes “While the change in the 5-year survival rate is not a perfect measure of progress against cancer […] it does contain useful information; its critics may have been unduly harsh. Part of the long-run increase in 5-year cancer survival rates is due to improved […] therapy.”
But they acknowledge that with survival rates alone, we can’t say what part – and in some cases we have evidence that it is small.
Summary
Survival statistics are misleading because they suggest inferences they do not actually support.
- Survival rates from the past might not apply to the present, and for a particular patient, the probability of survival depends on (1) causal factors like general health, and (2) informational factors like the mode of discovery (screening vs symptomatic presentation).
- If survival rates are higher when tumors are discovered early, that doesn’t mean that more screening would be better.
- And if a cancer is diagnosed late, and the patient dies, that doesn’t mean that if it had been diagnosed early, they would have lived.
- Finally, if survival rates improve over time (or they are different in different places) that doesn’t mean treatment is more effective.
To be clear, all of these conclusions can be true, and in some cases we know they are true, at least in part. For some cancers, treatments have improved, and for some, additional screening would save lives. But to support these conclusions, we need other methods and metrics – notably randomized controlled trials that compare mortality. Survival rates alone provide little or no information, and they are more likely to mislead than inform.

{kind=link}