Bootstrapping a Proportion
It’s another installment in Data Q&A: Answering the real questions with Python. Previous installments are available from the Data Q&A landing page.
Here’s a question from the Reddit statistics forum.
How do I use bootstrapping to generate confidence intervals for a proportion/ratio? The situation is this:
I obtain samples of text with differing numbers of lines. From several tens to over a million. I have no control over how many lines there are in any given sample. Each line of each sample may or may not contain a string S. Counting lines according to S presence or S absence generates a ratio of S to S’ for that sample. I want to use bootstrapping to calculate confidence intervals for the found ratio (which of course will vary with sample size).
To do this I could either:
A. Literally resample (10,000 times) of size (say) 1,000 from the original sample (with replacement) then categorise S (and S’), and then calculate the ratio for each resample, and finally identify highest and lowest 2.5% (for 95% CI), or
B. Generate 10,000 samples of 1,000 random numbers between 0 and 1, scoring each stochastically as above or below original sample ratio (equivalent to S or S’). Then calculate CI as in A.
Programmatically A is slow and B is very fast. Is there anything wrong with doing B? The confidence intervals generated by each are almost identical.
The answer to the immediate question is that A and B are equivalent, so there’s nothing wrong with B. But in follow-up responses, a few related questions were raised:
- Is resampling a good choice for this problem?
- What size should the resamplings be?
- How many resamplings do we need?
I don’t think resampling is really necessary here, and I’ll show some alternatives. And I’ll answer the other questions along the way.
Click here to run this notebook on Colab.
I’ll download a utilities module with some of my frequently-used functions, and then import the usual libraries.
Pallor and Probability
As an example, let’s use one of the exercises from Think Python:
The Count of Monte Cristo is a novel by Alexandre Dumas that is considered a classic. Nevertheless, in the introduction of an English translation of the book, the writer Umberto Eco confesses that he found the book to be “one of the most badly written novels of all time”.
In particular, he says it is “shameless in its repetition of the same adjective,” and mentions in particular the number of times “its characters either shudder or turn pale.”
To see whether his objection is valid, let’s count the number number of lines that contain the word pale in any form, including pale, pales, paled, and paleness, as well as the related word pallor. Use a single regular expression that matches all of these words and no others.
The following cell downloads the text of the book from Project Gutenberg.
download('https://www.gutenberg.org/cache/epub/1184/pg1184.txt');
We’ll use the following functions to remove the additional material that appears before and after the text of the book.
def is_special_line(line):
return line.startswith('*** ')
def clean_file(input_file, output_file):
reader = open(input_file)
writer = open(output_file, 'w')
for line in reader:
if is_special_line(line):
break
for line in reader:
if is_special_line(line):
break
writer.write(line)
reader.close()
writer.close()
clean_file('pg1184.txt', 'pg1184_cleaned.txt')
And we’ll use the following function to count the number of lines that contain a particular pattern of characters.
import re
def count_matches(lines, pattern):
count = 0
for line in lines:
result = re.search(pattern, line)
if result:
count += 1
return count
readlines reads the file and creates a list of strings, one for each line.
lines = open('pg1184_cleaned.txt').readlines()
n = len(lines)
n
61310
There are about 61,000 lines in the file.
The following pattern matches “pale” and several related words.
pattern = r'\b(pale|pales|paled|paleness|pallor)\b' k = count_matches(lines, pattern) k
223
These words appear in 223 lines of the file.
p_est = k / n p_est
0.0036372533028869677
So the estimated proportion is about 0.0036. To quantify the precision of that estimate, we’ll compute a confidence interval.
Resampling
First we’ll use the method OP called A – literally resampling the lines of the file. The following function takes a list of lines and selects a sample, with replacement, that has the same size.
def resample(lines):
return np.random.choice(lines, len(lines), replace=True)
In a resampled list, the same line can appear more than once, and some lines might not appear at all. So in any resampling, the forbidden words might appear more times than in the original text, or fewer. Here’s an example.
np.random.seed(1) count_matches(resample(lines), pattern)
201
In this resampling, the words appear in 201 lines, fewer than in the original (223).
If we repeat this process many times, we can compute a sample of possible values of k. Because this method is slow, we’ll only repeat it 101 times.
ks_resampling = [count_matches(resample(lines), pattern) for i in range(101)]
With these different values of k, we can divide by n to get the corresponding values of p.
ps_resampling = np.array(ks_resampling) / n
To see what the distribution of those values looks like, we’ll plot the CDF.
from empiricaldist import Cdf Cdf.from_seq(ps_resampling).plot(label='resampling') decorate(xlabel='Resampled proportion', ylabel='Density')
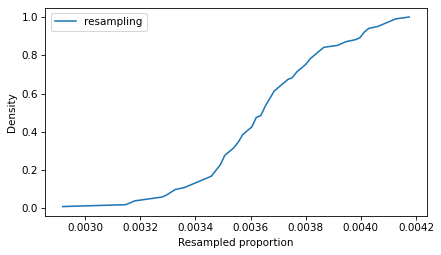
So that’s the slow way to compute the sampling distribution of the proportion. The method OP calls B is to simulate a Bernoulli trial with size n and probability of success p_est. One way to do that is to draw random numbers from 0 to 1 and count how many are less than p_est.
(np.random.random(n) < p_est).sum()
229
Equivalently, we can draw a sample from a Bernoulli distribution and add it up.
from scipy.stats import bernoulli bernoulli(p_est).rvs(n).sum()
232
These values follow a binomial distribution with parameters n and p_est. So we can simulate a large number of trials quickly by drawing values from a binomial distribution.
from scipy.stats import binom ks_binom = binom(n, p_est).rvs(10001)
Dividing by n, we can compute the corresponding sample of proportions.
ps_binom = np.array(ks_binom) / n
Because this method is so much faster, we can generate a large number of values, which means we get a more precise picture of the sampling distribution.
The following figure compares the CDFs of the values we got by resampling and the values we got from the binomial distribution.
Cdf.from_seq(ps_resampling).plot(label='resampling') Cdf.from_seq(ps_binom).plot(label='binomial') decorate(xlabel='Resampled proportion', ylabel='CDF')
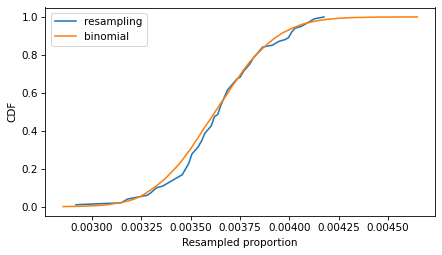
If we run the resampling method longer, these CDFs converge, so the two methods are equivalent.
To compute a 90% confidence interval, we can use the values we sampled from the binomial distribution.
np.percentile(ps_binom, [5, 95])
array([0.0032458 , 0.00404502])
Or we can use the inverse CDF of the binomial distribution, which is even faster than drawing a sample. And it’s deterministic – that is, we get the same result every time, with no randomness.
binom(n, p_est).ppf([0.05, 0.95]) / n
array([0.0032458 , 0.00404502])
Using the inverse CDF of the binomial distribution is a good way to compute confidence intervals. But before we get to that, let’s see how resampling behaves as we increase the sample size and the number of iterations.
Sample Size
In the example, the sample size is more than 60,000, so the CI is very small. The following figure shows what it looks like for more moderate sample sizes, using p=0.1 as an example.
p = 0.1
ns = [50, 500, 5000]
ci_df = pd.DataFrame(index=ns, columns=['low', 'high'])
for n in ns:
ks = binom(n, p).rvs(10001)
ps = ks / n
Cdf.from_seq(ps).plot(label=f"n = {n}")
ci_df.loc[n] = np.percentile(ps, [5, 95])
decorate(xlabel='Proportion', ylabel='CDF')
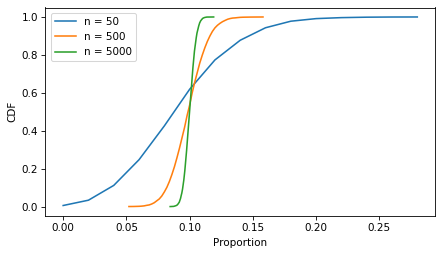
As the sample size increases, the spread of the sampling distribution gets smaller, and so does the width of the confidence interval.
ci_df['width'] = ci_df['high'] - ci_df['low'] ci_df
| low | high | width | |
|---|---|---|---|
| 50 | 0.04 | 0.18 | 0.14 |
| 500 | 0.078 | 0.122 | 0.044 |
| 5000 | 0.0932 | 0.1072 | 0.014 |
With resampling methods, it is important to draw samples with the same size as the original dataset – otherwise the result is wrong.
But the number of iterations doesn’t matter as much. The following figure shows the sampling distribution if we run the sampling process 101, 1001, and 10,001 times.
p = 0.1
n = 100
iter_seq = [101, 1001, 100001]
for iters in iter_seq:
ks = binom(n, p).rvs(iters)
ps = ks / n
Cdf.from_seq(ps).plot(label=f"iters = {iters}")
decorate()
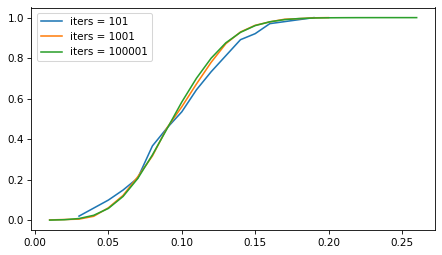
The sampling distribution is the same, regardless of how many iterations we run. But with more iterations, we get a better picture of the distribution and a more precise estimate of the confidence interval. For most problems, 1001 iterations is enough, but if you can generate larger samples fast enough, more is better.
However, for this problem, resampling isn’t really necessary. As we’ve seen, we can use the binomial distribution to compute a CI without drawing a random sample at all. And for this problem, there are approximations that are even easier to compute – although they come with some caveats.
Approximations
If n is large and p is not too close to 0 or 1, the sampling distribution of a proportion is well modeled by a normal distribution, and we can approximate a confidence interval with just a few calculations.
For a given confidence level, we can use the inverse CDF of the normal distribution to compute a
score, which is the number of standard deviations the CI should span – above and below the observed value of p – in order to include the given confidence.
from scipy.stats import norm confidence = 0.9 z = norm.ppf(1 - (1 - confidence) / 2) z
1.6448536269514722
A 90% confidence interval spans about 1.64 standard deviations.
Now we can use the following function, which uses p, n, and this z score to compute the confidence interval.
def confidence_interval_normal_approx(k, n, z):
p = k / n
margin_of_error = z * np.sqrt(p * (1 - p) / n)
lower_bound = p - margin_of_error
upper_bound = p + margin_of_error
return lower_bound, upper_bound
To test it, we’ll compute n and k for the example again.
n = len(lines) k = count_matches(lines, pattern) n, k
(61310, 223)
Here’s the confidence interval based on the normal approximation.
ci_normal = confidence_interval_normal_approx(k, n, z) ci_normal
(0.003237348046298746, 0.00403715855947519)
In the example, n is large, which is good for the normal approximation, but p is small, which is bad. So it’s not obvious whether we can trust the approximation.
An alternative that’s more robust is the Wilson score interval, which is reliable for values of p close to 0 and 1, and sample sizes bigger than about 5.
def confidence_interval_wilson_score(k, n, z):
p = k / n
factor = z**2 / n
denominator = 1 + factor
center = p + factor / 2
half_width = z * np.sqrt((p * (1 - p) + factor / 4) / n)
lower_bound = (center - half_width) / denominator
upper_bound = (center + half_width) / denominator
return lower_bound, upper_bound
Here’s the 90% CI based on Wilson scores.
ci_wilson = confidence_interval_wilson_score(k, n, z) ci_wilson
(0.003258660468175958, 0.00405965209814987)
Another option is the Clopper-Pearson interval, which is what we computed earlier with the inverse CDF of the binomial distribution. Here’s a function that computes it.
from scipy.stats import binom
def confidence_interval_exact_binomial(k, n, confidence=0.9):
alpha = 1 - confidence
p = k / n
lower_bound = binom.ppf(alpha / 2, n, p) / n if k > 0 else 0
upper_bound = binom.ppf(1 - alpha / 2, n, p) / n if k < n else 1
return lower_bound, upper_bound
And here’s the interval we get.
ci_binomial = confidence_interval_exact_binomial(k, n) ci_binomial
(0.003245800032621106, 0.0040450171260805745)
A final alternative is the Jeffreys interval, which is derived from Bayes’s Theorem. If we start with a Jeffreys prior and observe k successes out of n attempts, the posterior distribution of p is a beta distribution with parameters a = k + 1/2 and b = n - k + 1/2. So we can use the inverse CDF of the beta distribution to compute a CI.
from scipy.stats import beta
def bayesian_confidence_interval_beta(k, n, confidence=0.9):
alpha = 1 - confidence
a, b = k + 1/2, n - k + 1/2
lower_bound = beta.ppf(alpha / 2, a, b)
upper_bound = beta.ppf(1 - alpha / 2, a, b)
return lower_bound, upper_bound
And here’s the interval we get.
ci_beta = bayesian_confidence_interval_beta(k, n) ci_beta
(0.003254420914221609, 0.004054683138668112)
The following figure shows the four intervals we just computed graphically.
intervals = {
'Normal Approximation': ci_normal,
'Wilson Score': ci_wilson,
'Clopper-Pearson': ci_binomial,
'Jeffreys': ci_beta
}
y_pos = np.arange(len(intervals))
for i, (label, (lower, upper)) in enumerate(intervals.items()):
middle = (lower + upper) / 2
xerr = [[(middle - lower)], [(upper - middle)]]
plt.errorbar(x=middle, y=i-0.2, xerr=xerr, fmt='o', capsize=5)
plt.text(middle, i, label, ha='center', va='top')
decorate(xlabel='Proportion', ylim=[3.5, -0.8], yticks=[])
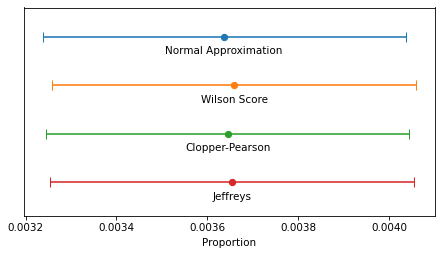
In this example, because n is so large, the intervals are all similar – the differences are too small to matter in practice. For smaller values of n, the normal approximation becomes unreliable, and for very small values, none of them are reliable.
The normal approximation and Wilson score interval are easy and fast to compute. On my old laptop, they take 1-2 microseconds.
%timeit confidence_interval_normal_approx(k, n, z)
1.04 µs ± 4.04 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
%timeit confidence_interval_wilson_score(k, n, z)
1.64 µs ± 28.6 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
Evaluating the inverse CDF of the binomial and beta distributions are more complex computations – they take about 100 times longer.
%timeit confidence_interval_exact_binomial(k, n)
195 µs ± 7.53 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%timeit bayesian_confidence_interval_beta(k, n)
269 µs ± 4.6 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
But they still take less than 300 microseconds, so unless you need to compute millions of confidence intervals per second, the difference in computation time doesn’t matter.
Discussion
If you took a statistics class and learned one of these methods, you probably learned the normal approximation. That’s because it is easy to explain and, because it is based on a form of the Central Limit Theorem, it helps to justify time spent learning about the CLT. But in my opinion it should never be used in practice because it is dominated by the Wilson score interval – that is, it is worse than Wilson in at least one way and better in none.
I think the Clopper-Pearson interval is equally easy to explain, but when n is small, there are few possible values of k, and therefore few possible values of p – and the interval can be wider than it needs to be.
The Jeffreys interval is based on Bayesian statistics, so it takes a little more explaining, but it behaves well for all values of n and p. And when n is small, it can be extended to take advantage of background information about likely values of p.
For these reasons, the Jeffreys interval is my usual choice, but in a computational environment that doesn’t provide the inverse CDF of the beta distribution, I would use a Wilson score interval.
OP is working in LiveCode, which doesn’t provide a lot of math and statistics libraries, so Wilson might be a good choice. Here’s a LiveCode implementation generated by ChatGPT.
-- Function to calculate the z-score for a 95% confidence level (z ≈ 1.96)
function zScore
return 1.96
end zScore
-- Function to calculate the Wilson Score Interval with distinct bounds
function wilsonScoreInterval k n
-- Calculate proportion of successes
put k / n into p
put zScore() into z
-- Common term for the interval calculation
put (z^2 / n) into factor
put (p + factor / 2) / (1 + factor) into adjustedCenter
-- Asymmetric bounds
put sqrt(p * (1 - p) / n + factor / 4) into sqrtTerm
-- Lower bound calculation
put adjustedCenter - (z * sqrtTerm / (1 + factor)) into lowerBound
-- Upper bound calculation
put adjustedCenter + (z * sqrtTerm / (1 + factor)) into upperBound
return lowerBound & comma & upperBound
end wilsonScoreInterval
Data Q&A: Answering the real questions with Python
Copyright 2024 Allen B. Downey