I have temperatures reading over times (2 secs interval) in a computer that is control by an automatic fan. The temperature fluctuate between 55 to 65 in approximately sine wave fashion. I wish to find out the average time between each cycle of the wave (time between 55 to 65 then 55 again the average over the entire data sets which includes many of those cycles) . What sort of statistical analysis do I use?
[The following] is one of my data set represents one of the system configuration. Temperature reading are taken every 2 seconds. Please show me how you guys do it and which software. I would hope for something low tech like libreoffice or excel. Hopefully nothing too fancy is needed.
A few people recommended using FFT, and I agreed, but I also suggested two other options:
And then another person suggested autocorrelation.
I ran some experiments to see what each of these solutions looks like and what works best. If you are too busy for the details, I think the best option is computing the distance between zero crossings using a spline fitted to the smoothed data.
For a long time I have recommended using CDFs to compare distributions. If you are comparing an empirical distribution to a model, the CDF gives you the best view of any differences between the data and the model.
Now I want to amend my advice. CDFs give you a good view of the distribution between the 5th and 95th percentiles, but they are not as good for the tails.
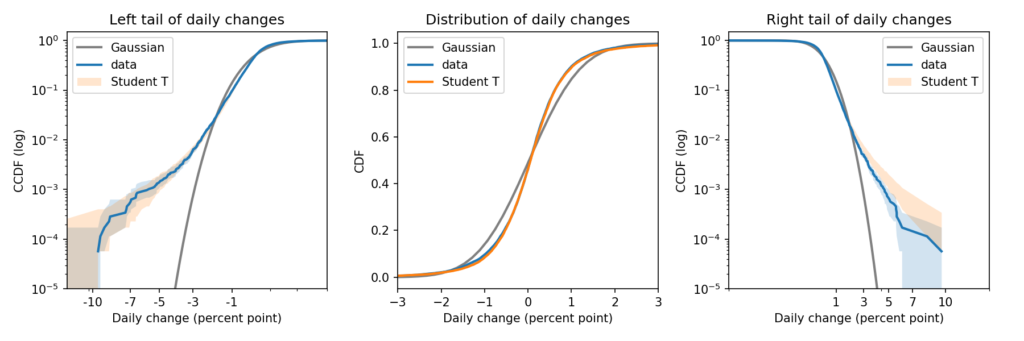
To compare both tails, as well as the “bulk” of the distribution, I recommend a triptych that looks like this:
There’s a lot of information in that figure. So let me explain.
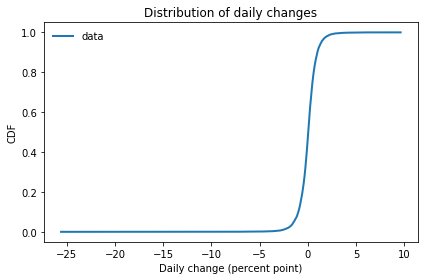
Suppose you observe a random process, like daily changes in the S&P 500. And suppose you have collected historical data in the form of percent changes from one day to the next. The distribution of those changes might look like this:
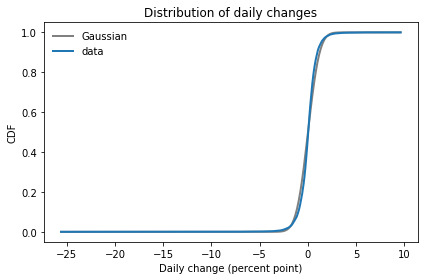
If you fit a Gaussian model to this data, it looks like this:
It looks like there are small discrepancies between the model and the data, but if you follow my previous advice, you might look at these CDFs and conclude that the Gaussian model is pretty good.
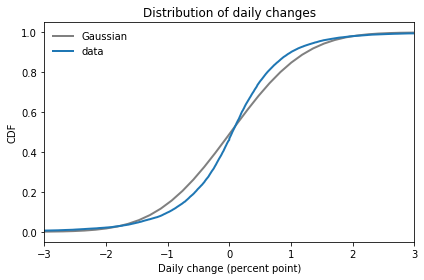
If we zoom in on the middle of the distribution, we can see the discrepancies more clearly:
In this figure it is clearer that the Gaussian model does not fit the data particularly well. And, as we’ll see, the tails are even worse.
Survival on a log-log scale
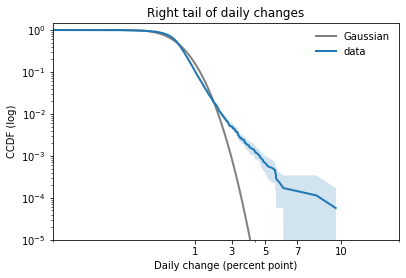
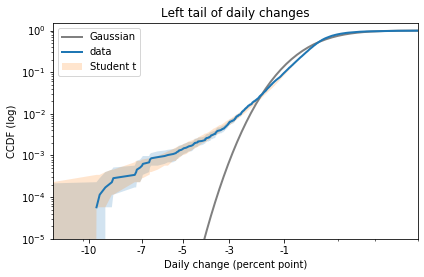
In my opinion, the best way to compare tails is to plot the survival curve (which is the complementary CDF) on a log-log scale.
In this case, because the dataset includes positive and negative values, I shift them right to view the right tail, and left to view the left tail.
Here’s what the right tail looks like:
This view is like a microscope for looking at tail behavior; it compresses the bulk of the distribution and expands the tail. In this case we can see a small discrepancy between the data and the model around 1 percentage point. And we can see a substantial discrepancy above 3 percentage points.
The Gaussian distribution has “thin tails”; that is, the probabilities it assigns to extreme events drop off very quickly. In the dataset, extreme values are much more common than the model predicts.
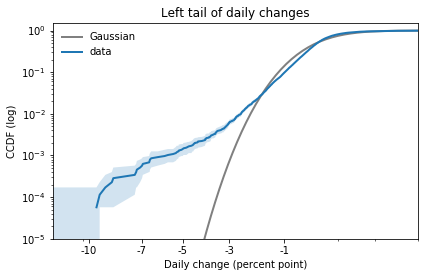
The results for the left tail are similar:
Again, there is a small discrepancy near -1 percentage points, as we saw when we zoomed in on the CDF. And there is a substantial discrepancy in the leftmost tail.
Student’s t-distribution
Now let’s try the same exercise with Student’s t-distribution. There are two ways I suggest you think about this distribution:
1) Student’s t is similar to a Gaussian distribution in the middle, but it has heavier tails. The heaviness of the tails is controlled by a third parameter, ν.
2) Also, Student’s t is a mixture of Gaussian distributions with different variances. The tail parameter, ν, is related to the variance of the variances.
I used PyMC to estimate the parameters of a Student’s t model and generate a posterior predictive distribution. You can see the details in this Jupyter notebook.
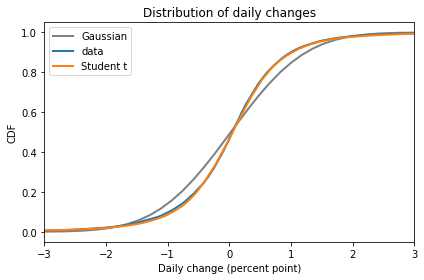
Here is the CDF of the Student t model compared to the data and the Gaussian model:
In the bulk of the distribution, Student’s t-distribution is clearly a better fit.
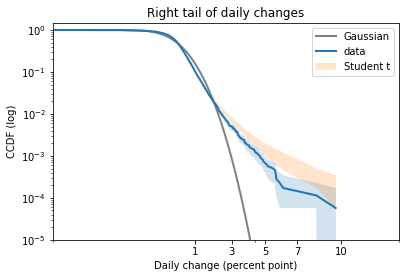
Now here’s the right tail, again comparing survival curves on a log-log scale:
Student’s t-distribution is a better fit than the Gaussian model, but it overestimates the probability of extreme values. The problem is that the left tail of the empirical distribution is heavier than the right. But the model is symmetric, so it can only match one tail or the other, not both.
Here is the left tail:
The model fits the left tail about as well as possible.
If you are primarily worried about predicting extreme losses, this model would be a good choice. But if you need to model both tails well, you could try one of the asymmetric generalizations of Student’s t.
The old six sigma
The tail behavior of the Gaussian distribution is the key to understanding “six sigma events”.
“Six sigma means six standard deviations away from the mean of a probability distribution, sigma (σ) being the common notation for a standard deviation. Moreover, the underlying distribution is implicitly a normal (Gaussian) distribution; people don’t commonly talk about ‘six sigma’ in the context of other distributions.”
This is important. John also explains:
“A six-sigma event isn’t that rare unless your probability distribution is normal… The rarity of six-sigma events comes from the assumption of a normal distribution more than from the number of sigmas per se.”
So, if you see a six-sigma event, you should probably not think, “That was extremely rare, according to my Gaussian model.” Instead, you should think, “Maybe my Gaussian model is not a good choice”.
In the first article in this series, I looked at data from the General Social Survey (GSS) to see how political alignment in the U.S. has changed, on the axis from conservative to liberal, over the last 50 years.
In the second article, I suggested that self-reported political alignment could be misleading.
Do you think most people would try to take advantage of you if they got a chance, or would they try to be fair?
And generated seven “headlines” to describe the results.
In this article, we’ll use resampling to see how much the results depend on random sampling. And we’ll see which headlines hold up and which might be overinterpretation of noise.
Overall trends
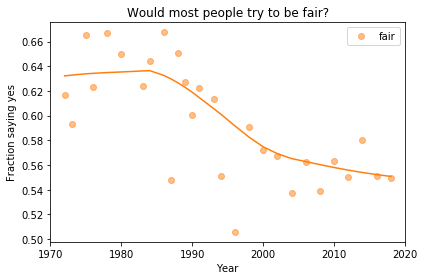
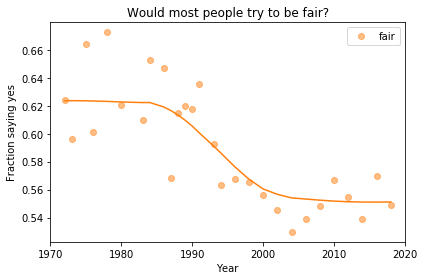
In the previous article we looked at this figure, which was generated by resampling the GSS data and computing a smooth curve through the annual averages.
If we run the resampling process two more times, we get somewhat different results:
Now, let’s review the headlines from the previous article. Looking at different versions of the figure, which conclusions do you think are reliable?
Absolute value: “Most respondents think people try to be fair.”
Rate of change: “Belief in fairness is falling.”
Change in rate: “Belief in fairness is falling, but might be leveling off.”
In my opinion, the three figures are qualitatively similar. The shapes of the curves are somewhat different, but the headlines we wrote could apply to any of them.
Even the tentative conclusion, “might be leveling off”, holds up to varying degrees in all three.
Grouped by political alignment
When we group by political alignment, we have fewer samples in each group, so the results are noisier and our headlines are more tentative.
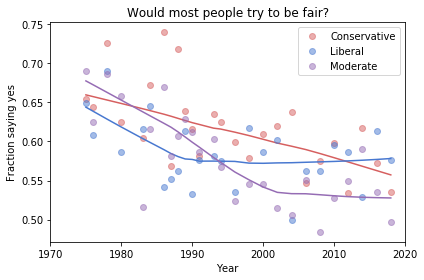
Here’s the figure from the previous article:
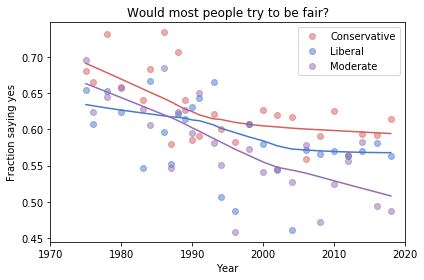
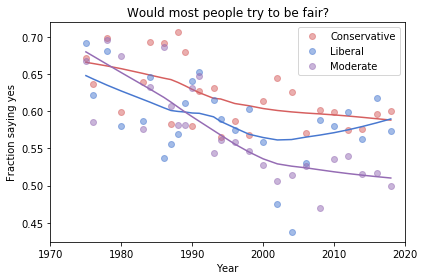
And here are two more figures generated by random resampling:
Now we see more qualitative differences between the figures. Let’s review the headlines again:
Absolute value: “Moderates have the bleakest outlook; Conservatives and Liberals are more optimistic.” This seems to be true in all three figures, although the size of the gap varies substantially.
Rate of change: “Belief in fairness is declining in all groups, but Conservatives are declining fastest.” This headline is more questionable. In one version of the figure, belief is increasing among Liberals. And it’s not at all clear the the decline is fastest among Conservatives.
Change in rate: “The Liberal outlook was declining, but it leveled off in 1990.” The Liberal outlook might have leveled off, or even turned around, but we could not say with any confidence that 1990 was a turning point.
Change in rate: “Liberals, who had the bleakest outlook in the 1980s, are now the most optimistic”. It’s not clear whether Liberals have the most optimistic outlook in the most recent data.
As we should expect, conclusions based on smaller sample sizes are less reliable.
Also, conclusions about absolute values are more reliable than conclusions about rates, which are more reliable than conclusions about changes in rates.
In the first article in this series, I looked at data from the General Social Survey (GSS) to see how political alignment in the U.S. has changed, on the axis from conservative to liberal, over the last 50 years.
In the second article, I suggested that self-reported political alignment could be misleading.
In this article we’ll look at results from questions related to “outlook”, that is, how the respondents see the world and people in it.
Specifically, the questions are:
fair: Do you think most people would try to take advantage of you if they got a chance, or would they try to be fair?
trust: Generally speaking, would you say that most people can be trusted or that you can’t be too careful in dealing with people?
helpful: Would you say that most of the time people try to be helpful, or that they are mostly just looking out for themselves?
Do people try to be fair?
Let’s start with fair. The responses are coded like this:
1 Take advantage
2 Fair
3 Depends
To put them on a numerical scale, I recoded them like this:
1 Fair
0.5 Depends
0 Take advantage
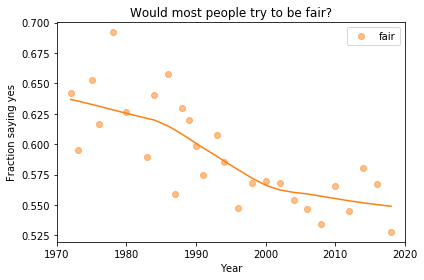
I flipped the axis so the more positive answer is higher, and put “Depends” in the middle. Now we can plot the mean response by year, like this:
Looking at a figure like this, there are three levels we might describe:
Absolute value: “Most respondents think people try to be fair.”
Rate of change: “Belief in fairness is falling.”
Change in rate: “Belief in fairness is falling, but might be leveling off.”
For any of these qualitative descriptions, we could add quantitative estimates. For example, “About 55% of U.S. residents think people try to be fair”, or “Belief in fairness has dropped 10 percentage points since 1970”.
Statistically, the estimates of absolute value are probably reliable, but we should be more cautious estimating rates of change, and substantially more cautious talking about changes in rates. We’ll come back to this issue, but first let’s look at breakdowns by group.
Outlook and political alignment
In the previous article I grouped respondents by self-reported political alignment: Conservative, Moderate, or Liberal.
We can use these groups to see the relationship between outlook and political alignment. For example, the following figure shows the average response to the fairness question, grouped by political alignment and plotted over time:
Results like these invite comparisons between groups, and we can make those comparisons at several levels. Here are some potential headlines for this figure:
Absolute value: “Moderates have the bleakest outlook; Conservatives and Liberals are more optimistic.”
Rate of change: “Belief in fairness is declining in all groups, but Conservatives are declining fastest.”
Change in rate: “The Liberal outlook was declining, but it leveled off in 1990.” or “Liberals, who had the bleakest outlook in the 1980s, are now the most optimistic”.
Because we divided the respondents into three groups, the sample size in each group is smaller. Statistically, we need to be more skeptical about our estimates of absolute level, even more skeptical about rates of change, and extremely skeptical about changes in rates.
In the next article, I’ll use resampling to quantify the uncertainly of these estimates, and we’ll see how many of these headlines hold up.