The Frog Puzzle
Here’s a probability puzzle from a TED-Ed video called Can you solve the frog riddle? by Derek Abbott. It came up recently in this Reddit thread:
You’re stranded in a rainforest after accidentally eating a poisonous mushroom. To survive the poison, you need to lick a certain species of frog. Only female frogs produce the antidote. Male and female frogs occur in equal numbers and look identical, but male frogs have a distinctive croak.
You see one frog alone on a tree stump. In another direction, you hear the croak of a male frog coming from a clearing with two frogs. You can’t tell which one made the sound.
You only have time to go to one place. What are your chances of survival if you go to the clearing and lick both frogs? What if you go to the lone frog?
The second question is relatively easy: if we assume that you are equally likely to see a male or female frog, the probability is 50% that the lone frog is female.
The first question depends on how we interpret the puzzle. In particular, it hinges on the word “distinctive” – does that mean:
- Only male frogs croak, and the sound is distinguishable from background noises, or
- Both male and female frogs croak, but the male croak is distinguishable from the female croak.
Based on the answer presented in the video, the first meaning is intended. So we’ll start by solving that version.
But the second meaning makes the problem a little harder, so we’ll solve that one, too.
Only Male Frogs Croak
To solve the intended version of the puzzle, we’ll assume
- Only male frogs croak, and
- When two frogs appear together, their sexes are independent.
So we’ll start with a prior where all two-frog combinations are equally likely.
from sympy import Rational hypo = ['FF', 'FM', 'MF', 'MM'] prior = Rational(1)
Now let’s think about the likelihood of the data under each scenario. In the video, the solution is based on these assumptions:
- If both frogs are female, the probability of hearing the male croak is 0.
- If either frog is male, the probability that one of them croaks is 1.
likelihood = [0, 1, 1, 1]
I’ll use a BayesTable to compute the posterior probability for each scenario.
import pandas as pd
import numpy as np
class BayesTable(pd.DataFrame):
def __init__(self, hypo, prior=1, **options):
columns = ['prior', 'likelihood', 'unnorm', 'posterior']
super().__init__(index=hypo, columns=columns, **options)
self.prior = prior
def update(self, likelihood):
self.likelihood = likelihood
self.unnorm = self.prior * self.likelihood
nc = self.unnorm.sum()
self.posterior = self.unnorm / nc
table = BayesTable(hypo, prior) table.update(likelihood) table
| prior | likelihood | unnorm | posterior | |
|---|---|---|---|---|
| FF | 1 | 0 | 0 | 0 |
| FM | 1 | 1 | 1 | 1/3 |
| MF | 1 | 1 | 1 | 1/3 |
| MM | 1 | 1 | 1 | 1/3 |
From the table, we can extract the posterior probability that both frogs are male.
from sympy import init_printing init_printing(use_latex=False)
table.posterior['MM']
1/3
With these assumptions, the probability 1/3 that both frogs are male (and you die), so the probability is 2/3 that at least one is female (and you live).
And that’s the answer in the video.
Poisson (not Poison) Frogs
But is that the right likelihood? Suppose frogs are equally likely to croak at any instant in time, so their croaks follow a Poisson process. If we assume that these croaking processes are independent, two frogs would be more likely to croak, during a given interval, than one.
If the interval is much longer than the average time between croaks, the probability that either frog croaks approaches 1, which is consistent with the previous solution.
But if the interval is short – as it might be if you were deciding whether to approach the first frog – the probability of hearing a croak would be double if there are two male frogs rather than one.
In that case, the likelihood of the data would be:
half = Rational(1, 2) likelihood = [0, half, half, 1]
And here are the posterior probabilities:
table = BayesTable(hypo, prior) table.update(likelihood) table
| prior | likelihood | unnorm | posterior | |
|---|---|---|---|---|
| FF | 1 | 0 | 0 | 0 |
| FM | 1 | 1/2 | 1/2 | 1/4 |
| MF | 1 | 1/2 | 1/2 | 1/4 |
| MM | 1 | 1 | 1 | 1/2 |
With Poisson frogs and a short interval, the probability of two male frogs is 1/2, so it doesn’t matter whether you approach the lone frog or the pair of frogs.
Female Frogs Croak, Too
Now let’s think about the other interpretation of the puzzle: suppose both male and female frogs croak, but we can distinguish one from the other. And suppose male and female frogs croak at different rates, but they are still independent.
Assume that male frogs croak at a rate of 1 per time unit, and female frogs at a rate of r per time unit. In that case, if we start listening at a random time, the probability that we hear a male frog first is 1 / (r+1) if there’s only one male frog, and 1 if there are two male frogs.
So the likelihood in this case is:
from sympy import symbols
r = symbols('r')
likelihood = [0, 1 / (r+1), 1 / (r+1), 1]
And here are the posteriors
table = BayesTable(hypo, prior) table.update(likelihood) table
| prior | likelihood | unnorm | posterior | |
|---|---|---|---|---|
| FF | 1 | 0 | 0 | 0 |
| FM | 1 | 1/(r + 1) | 1/(r + 1) | 1/((1 + 2/(r + 1))*(r + 1)) |
| MF | 1 | 1/(r + 1) | 1/(r + 1) | 1/((1 + 2/(r + 1))*(r + 1)) |
| MM | 1 | 1 | 1 | 1/(1 + 2/(r + 1)) |
In this scenario, here’s the probability you die.
prob_die = table.posterior['MM'] prob_die.simplify()
r + 1 ───── r + 3
If female frogs don’t croak, we get the same answer as in the first scenario.
prob_die.subs({r: 0})
1/3
If male and female frogs croak at the same rate, the probability that both frogs are male is 1/2.
prob_die.subs({r: 1})
1/2
But if female frogs croak much more often, the fact that a male croaked first is strong evidence that both are male, so the posterior probability is close to 1.
prob_die.subs({r: 1000}).evalf()
0.998005982053839
Assortative Mating
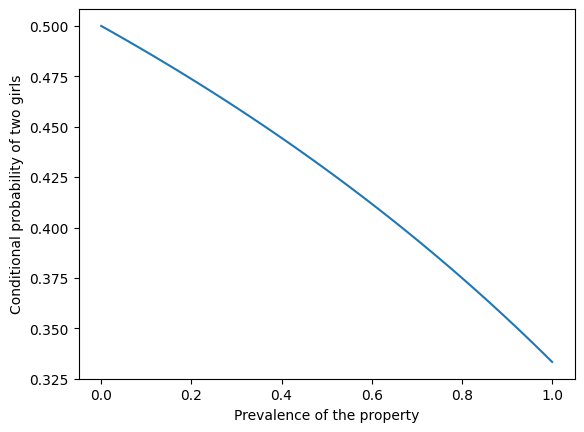
Now suppose that when we see two frogs together, their sexes are not independent; specifically, let’s assume that the probability of a same-sex pair is p, so the probability of a mixed-sex pair is 1-p. In this scenario, the priors (before we hear the croak) are not equal.
p = symbols('p')
prior = [p, 1-p, 1-p, p]
Here are the posterior probabilities, assuming again that both male and female frogs, possibly at different rates.
likelihood = [0, 1 / (r+1), 1 / (r+1), 1] table = BayesTable(hypo, prior) table.update(likelihood) table
| prior | likelihood | unnorm | posterior | |
|---|---|---|---|---|
| FF | p | 0 | 0 | 0 |
| FM | 1 – p | 1/(r + 1) | (1 – p)/(r + 1) | (1 – p)/((p + 2*(1 – p)/(r + 1))*(r + 1)) |
| MF | 1 – p | 1/(r + 1) | (1 – p)/(r + 1) | (1 – p)/((p + 2*(1 – p)/(r + 1))*(r + 1)) |
| MM | p | 1 | p | p/(p + 2*(1 – p)/(r + 1)) |
table.posterior['MM'].simplify()
p⋅(r + 1) ─────────── p⋅r - p + 2
If p=1/2, this simplifies to the previous scenario.
table.posterior['MM'].subs({p: half}).simplify()
r + 1 ───── r + 3
And if r=0 (female frogs don’t croak), we get the answer presented in the video.
table.posterior['MM'].subs({p: half, r: 0}).simplify()
1/3
But depending on the assumptions, the probability can be as low as 0
table.posterior['MM'].subs({p: 0, r: 1}).simplify()
0
Or as high as 1.
table.posterior['MM'].subs({p: 1, r: 0}).simplify()
1
Or anything in between. As is often the case with problems like these, the answer depends on a precise specification of the data-generating process.
Discussion
If all of this seems like more trouble than it’s worth, let me suggest a metacognitive shortcut for solving puzzles like this.
- Notice that in all probability puzzles, the answer is either 1/2 or 1/3.
- Also, the answer is always counterintuitive; otherwise it wouldn’t be a puzzle.
- Therefore, if your intuition says the answer is 1/2, it’s actually 1/3, and vice versa.
That might save you some time.
This notebook uses methods and materials from Think Bayes, second edition. If you like this sort of thing, you can read the whole book, and more examples, at allendowney.github.io/ThinkBayes2/.