The Poincaré Problem
Selection bias is the hardest problem in statistics because it’s almost unavoidable in practice, and once the data have been collected, it’s usually not possible to quantify the effect of selection or recover an unbiased estimate of what you are trying to measure.
And because the effect is systematic, not random, it doesn’t help to collect more data. In fact, larger sample sizes make the problem worse, because they give the false impression of precision.
But sometimes, if we are willing to make assumptions about the data generating process, we can use Bayesian methods to infer the effect of selection bias and produce an unbiased estimate.
Click here to run this notebook on Colab.
Poincaré and the Baker
As an example, let’s solve an exercise from Chapter 7 of Think Bayes. It’s based on a fictional anecdote about the mathematician Henri Poincaré:
Supposedly Poincaré suspected that his local bakery was selling loaves of bread that were lighter than the advertised weight of 1 kg, so every day for a year he bought a loaf of bread, brought it home and weighed it. At the end of the year, he plotted the distribution of his measurements and showed that it fit a normal distribution with mean 950 g and standard deviation 50 g. He brought this evidence to the bread police, who gave the baker a warning.
For the next year, Poincaré continued to weigh his bread every day. At the end of the year, he found that the average weight was 1000 g, just as it should be, but again he complained to the bread police, and this time they fined the baker.
Why? Because the shape of the new distribution was asymmetric. Unlike the normal distribution, it was skewed to the right, which is consistent with the hypothesis that the baker was still making 950 g loaves, but deliberately giving Poincaré the heavier ones.
To see whether this anecdote is plausible, let’s suppose that when the baker sees Poincaré coming, he hefts
kloaves of bread and gives Poincaré the heaviest one. How many loaves would the baker have to heft to make the average of the maximum 1000 g?
How Many Loaves?
Here are distributions with the same underlying normal distribution and different values of k.
mu_true, sigma_true = 950, 50
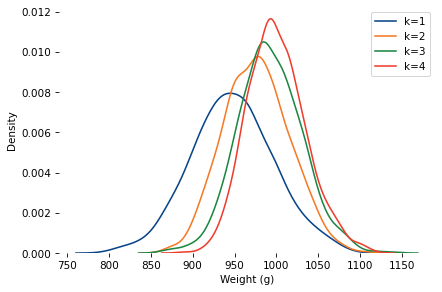
As k increases, the mean increases and the standard deviation decreases.
When k=4, the mean is close to 1000. So let’s assume the baker hefted four loaves and gave the heaviest to Poincaré.
At the end of one year, can we tell the difference between the following possibilities?
- Innocent: The baker actually increased the mean to 1000, and
k=1. - Shenanigans: The mean was still 950, but the baker selected with
k=4.
Here’s a sample under the k=4 scenario, compared to 10 samples with the same mean and standard deviation, and k=1.
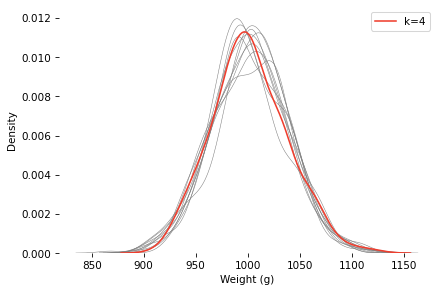
The k=4 distribution falls mostly within the range of variation we’d expect from the k=1 distribution (with the same mean and standard deviation). If you were on the jury and saw this evidence, would you convict the baker?
Ask a Bayesian
As a Bayesian approach to this problem, let’s see if we can use this data to estimate k and the parameters of the underlying distribution. Here’s a PyMC model that
- Defines prior distributions for
mu,sigma, andk, and - Uses a custom distribution that computes the likelihood of the data for a hypothetical set of parameters (see the notebook for details).
def make_model(sample):
with pm.Model() as model:
mu = pm.Normal("mu", mu=950, sigma=30)
sigma = pm.HalfNormal("sigma", sigma=30)
k = pm.Uniform("k", lower=0.5, upper=15)
obs = pm.CustomDist(
"obs",
mu, sigma, k,
logp=max_normal_logp,
observed=sample,
)
return model
Notice that we treat k as continuous. That’s because continuous parameters are much easier to sample (and the log PDF function allows non-integer values of k). But it also make sense in the context of the problem – for example, if the baker sometimes hefts three loaves and sometimes four, we can approximate the distribution of the maximum with k=3.5.
The model runs quickly and the diagnostics look good. Here are the posterior distributions of the parameters compared to their known values.
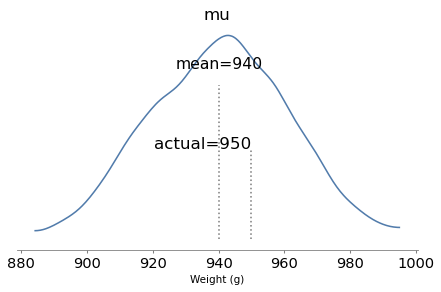
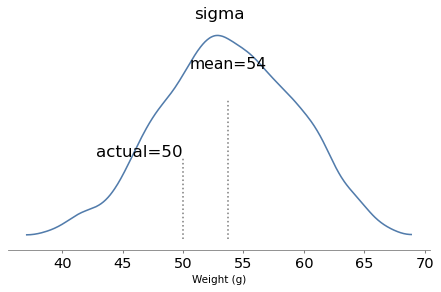
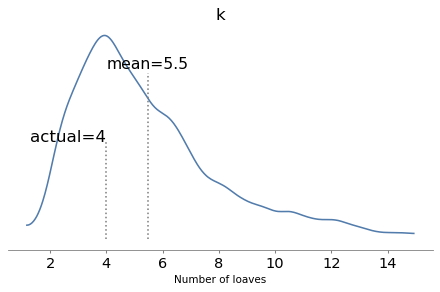
With one year of data, we can recover the parameters pretty well. The true values fall comfortably inside the posterior distributions, and the posterior mode of k is close to the true value, 4.
But the posterior distributions are still quite wide. There is even some possibility that the baker is innocent, although it is small.
Conclusion
This example shows that we can use the shape of an observed distribution to estimate the effect of selection bias and recover the unbiased latent distribution. But we might need a lot of data, and the inference depends on strong assumptions about the data generating process.
Credits: I don’t remember where I got this example from (maybe here?), but it appears in Leonard Mlodinov, The Drunkard’s Walk (2008). Mlodinov credits Bart Holland, What Are the Chances? (2002). The ultimate source seems to be George Gamow and Marvin Stern, Puzzle Math (1958) – but their version is about a German professor, not Poincaré.
You can order print and ebook versions of Think Bayes 2e from Bookshop.org and Amazon.