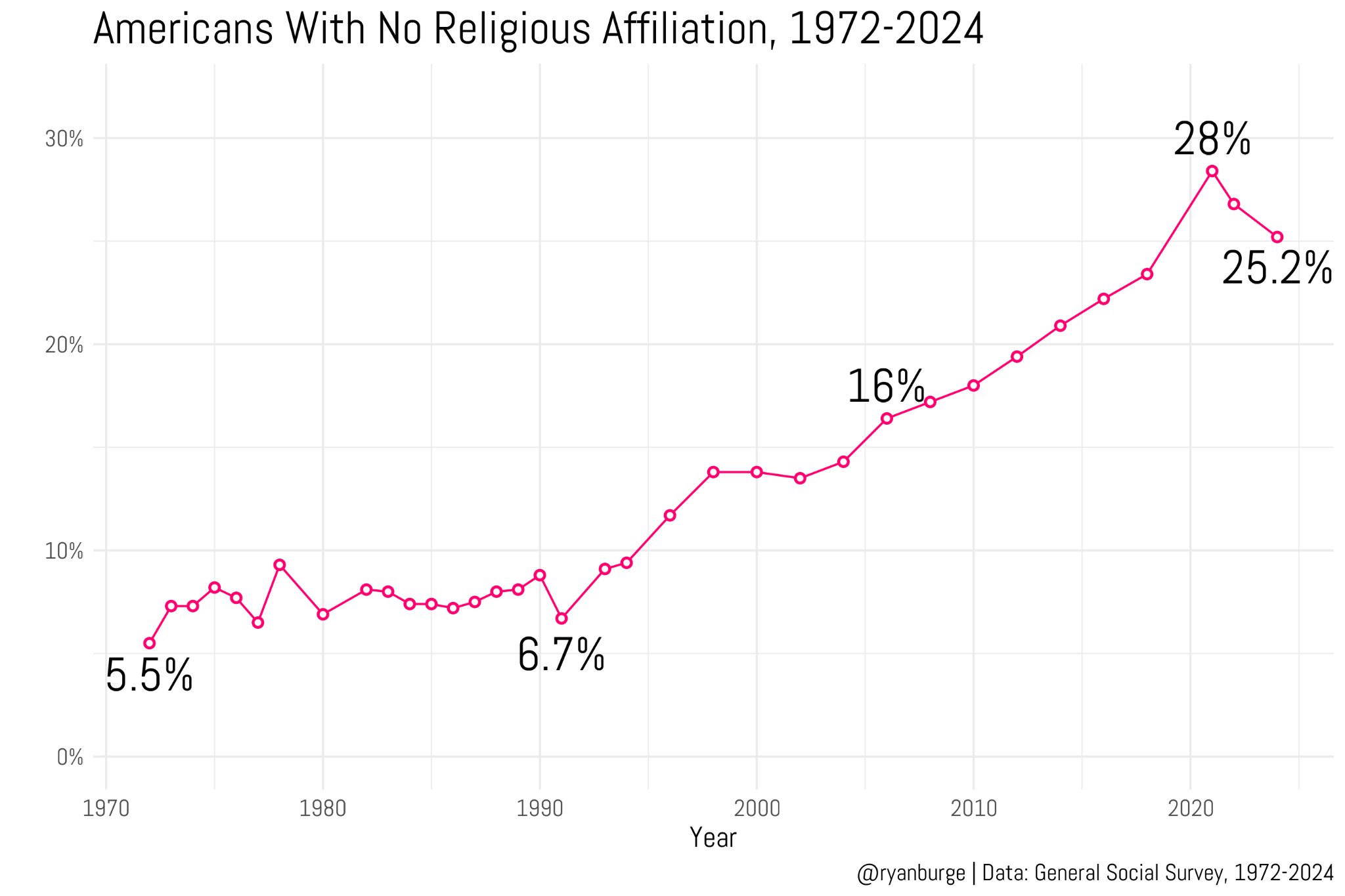
Trust and Well-Being
In a previous article, I claimed that Young adults are not very happy. Now the World Happiness Report 2026 has confirmed that young people in North America and Western Europe are less happy than they were fifteen years ago, and less happy than previous generations.
In this article, we’ll look at results from three related questions in the General Social Survey (GSS):
- Trust: “Generally speaking, would you say that most people can be trusted or that you can’t be too careful in dealing with people?”
- Fair: “Do you think most people would try to take advantage of you if they got a chance, or would they try to be fair?”
- Helpful: “Would you say that most of the time people try to be helpful, or that they are mostly just looking out for themselves?”
As we’ll see, young adults in the United States have a more negative outlook than previous generations: they are less likely to say that people can be trusted, that they are fair, or that they are helpful. And we’ll consider connections between this bleak outlook and unhappiness.
Trust
Using the same model from the previous articles, I estimated the percentage who say people can be trusted, following each birth year over time.
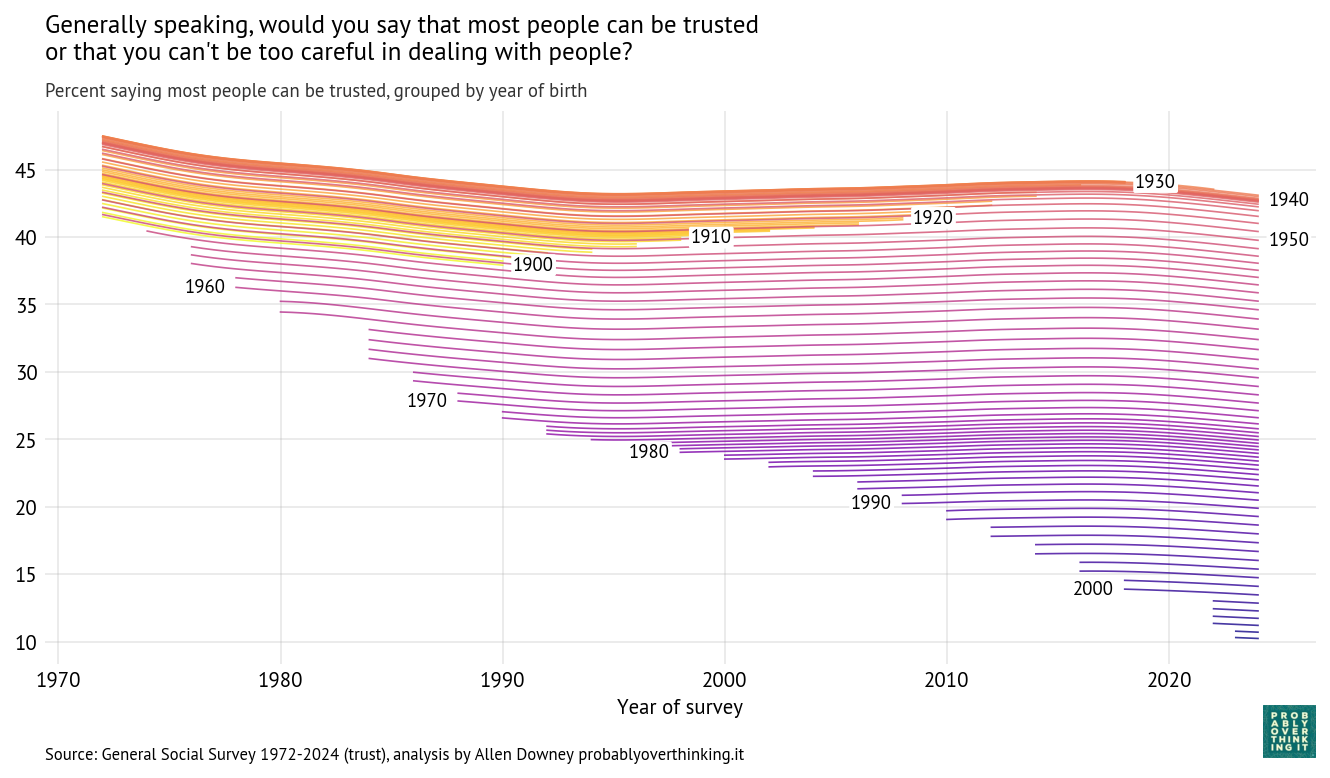
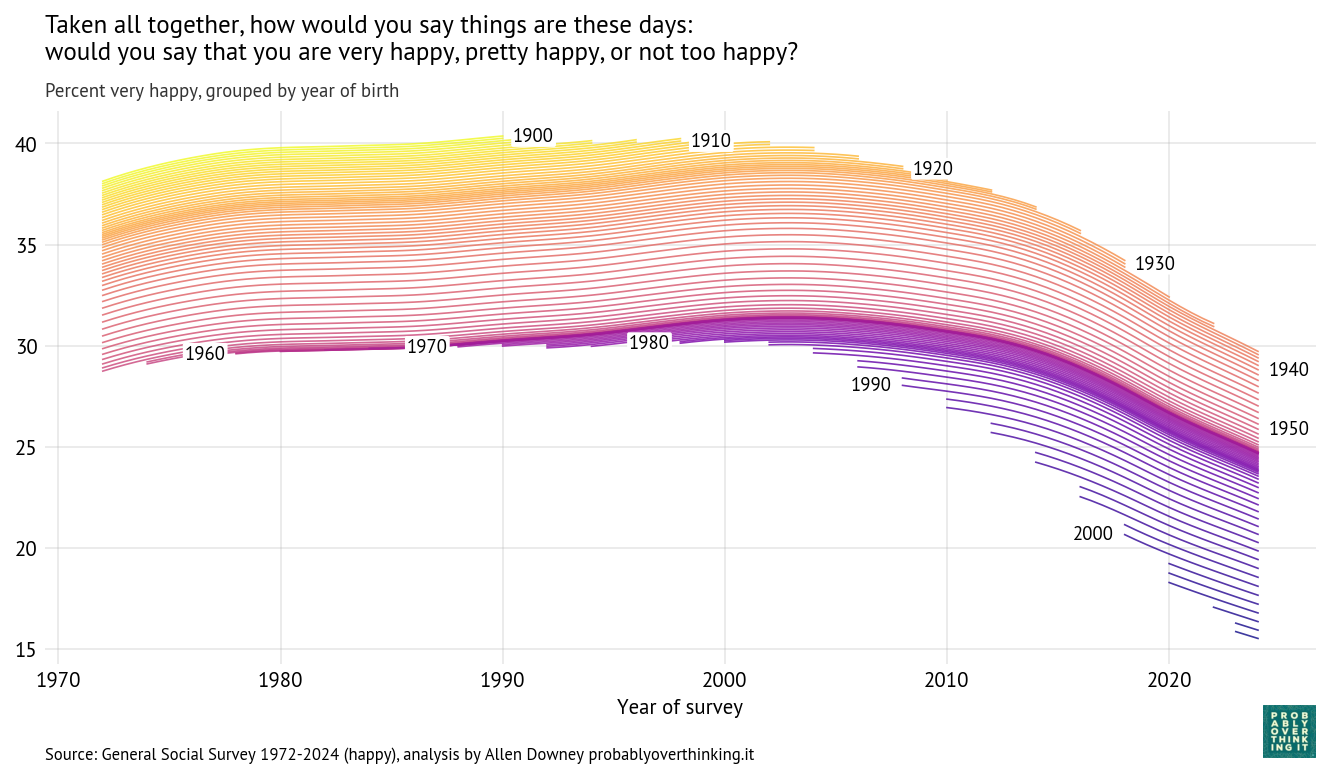
Cohort trajectories, percent saying most people can be trusted
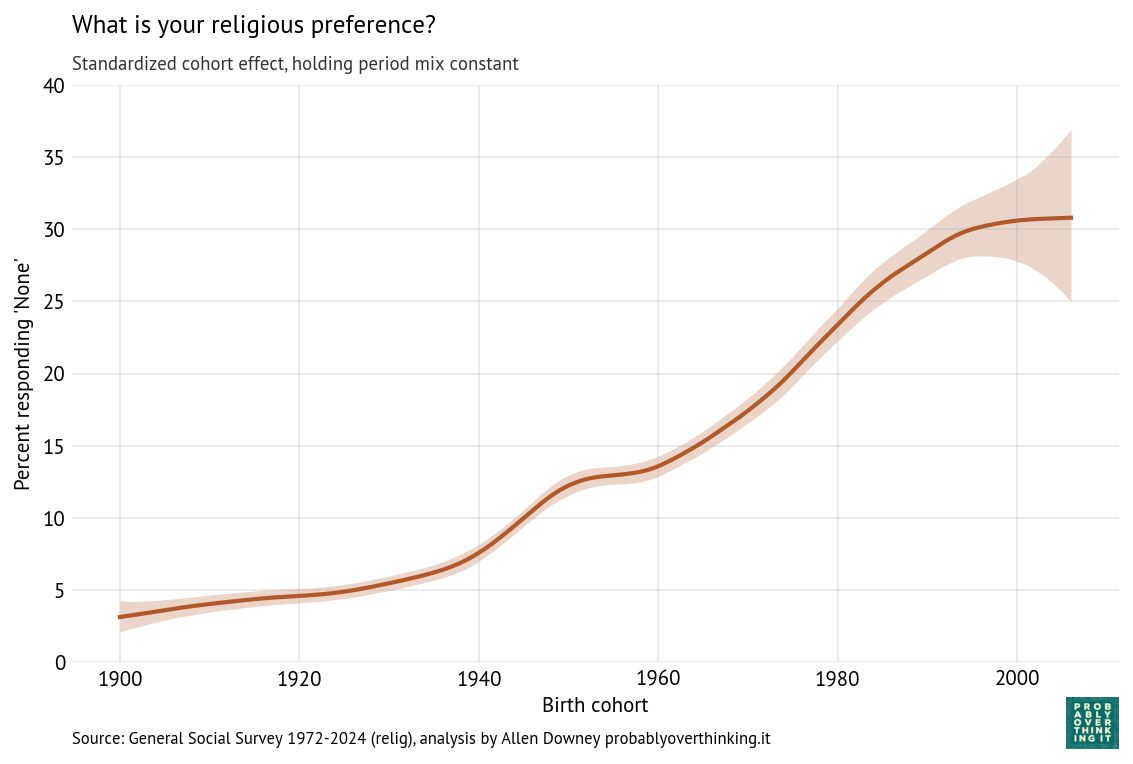
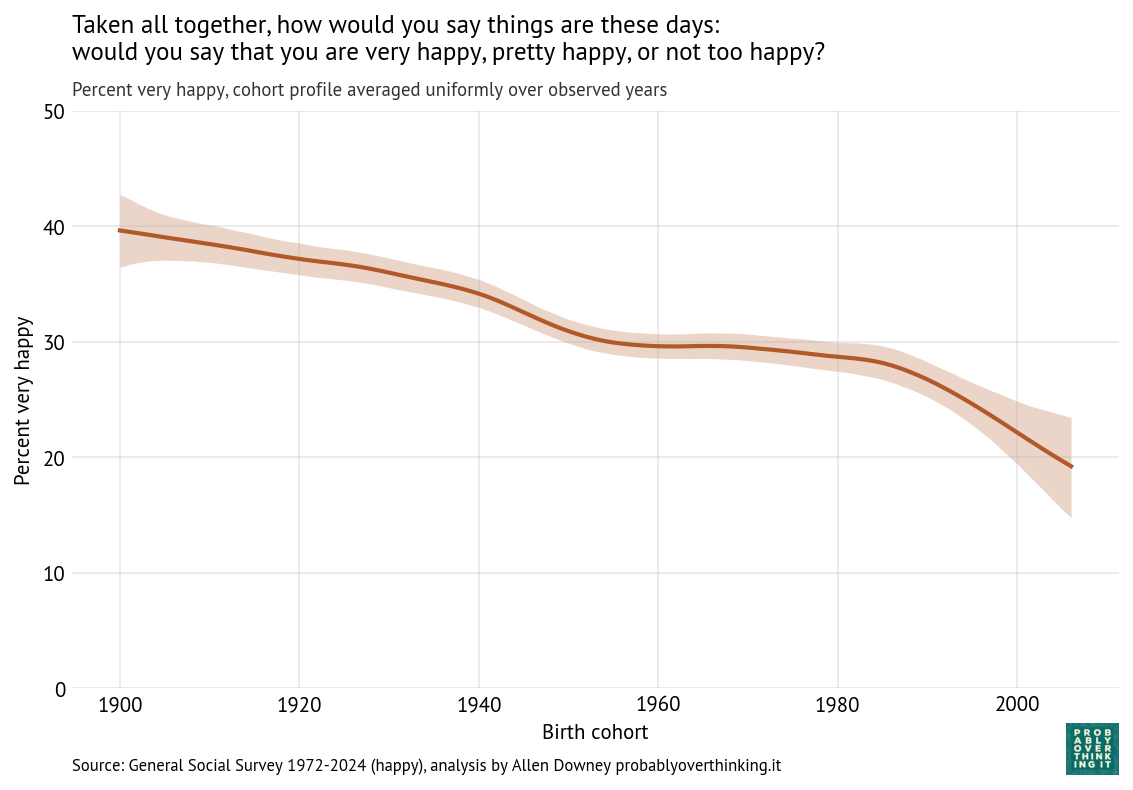
With these trajectories, we can decompose the cohort and period effects. The following figure shows the cohort effect, standardized by holding the period effect constant.
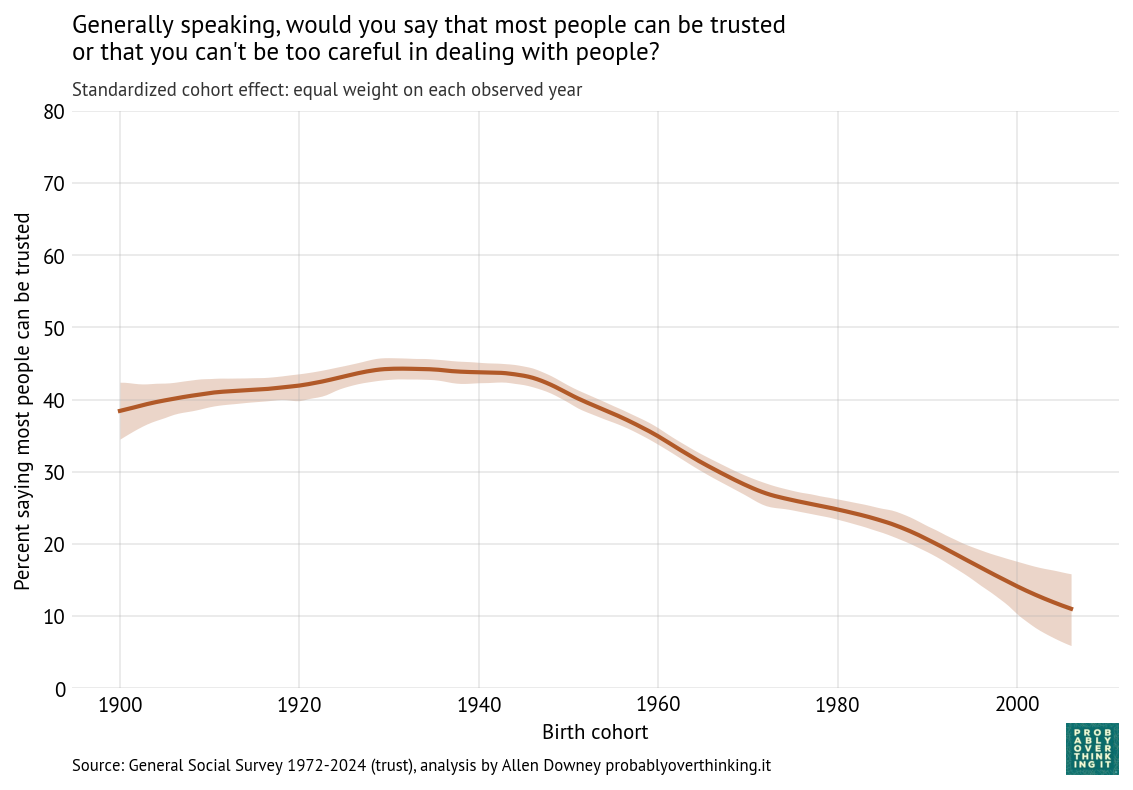
Standardized cohort effect with fixed time mix, percent saying most people can be trusted
The level of trust increased between the cohorts born in the 1900s through the 1940s, and then started a steep decline. This is a large cohort effect, dropping about 30 percentage points over 60 years.
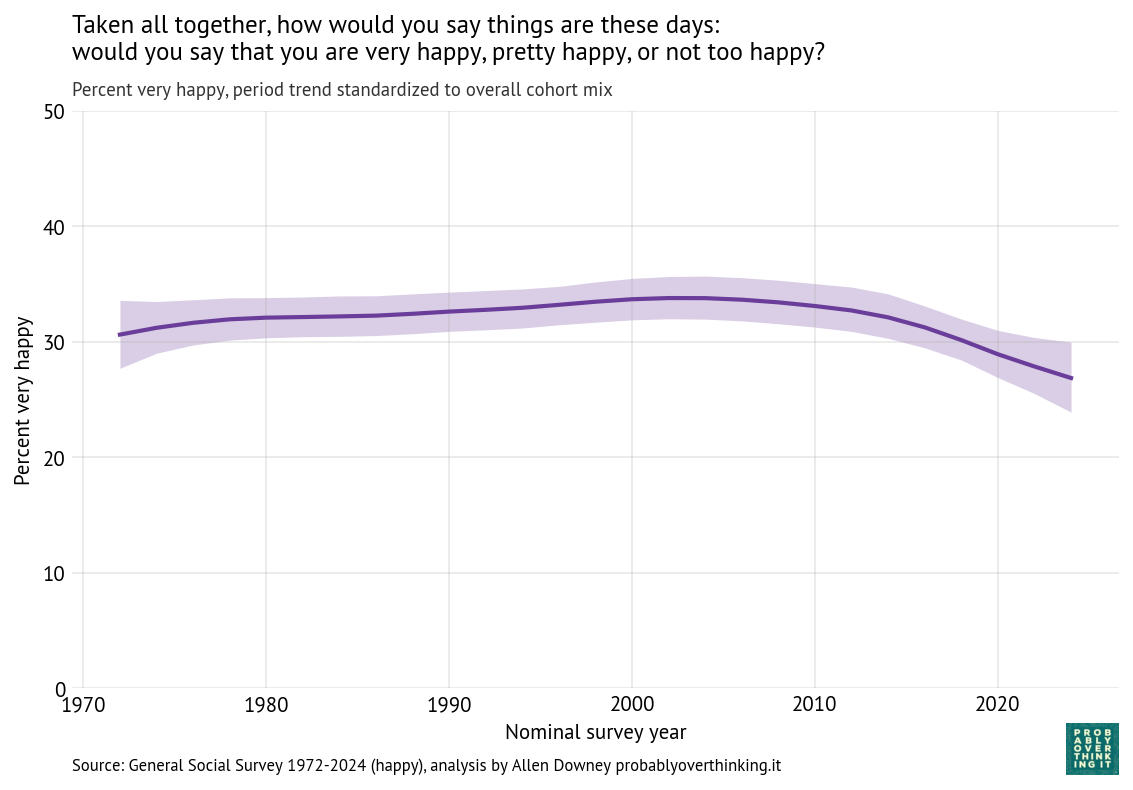
The following figure shows the period effect, standardized by holding the cohort mix constant.
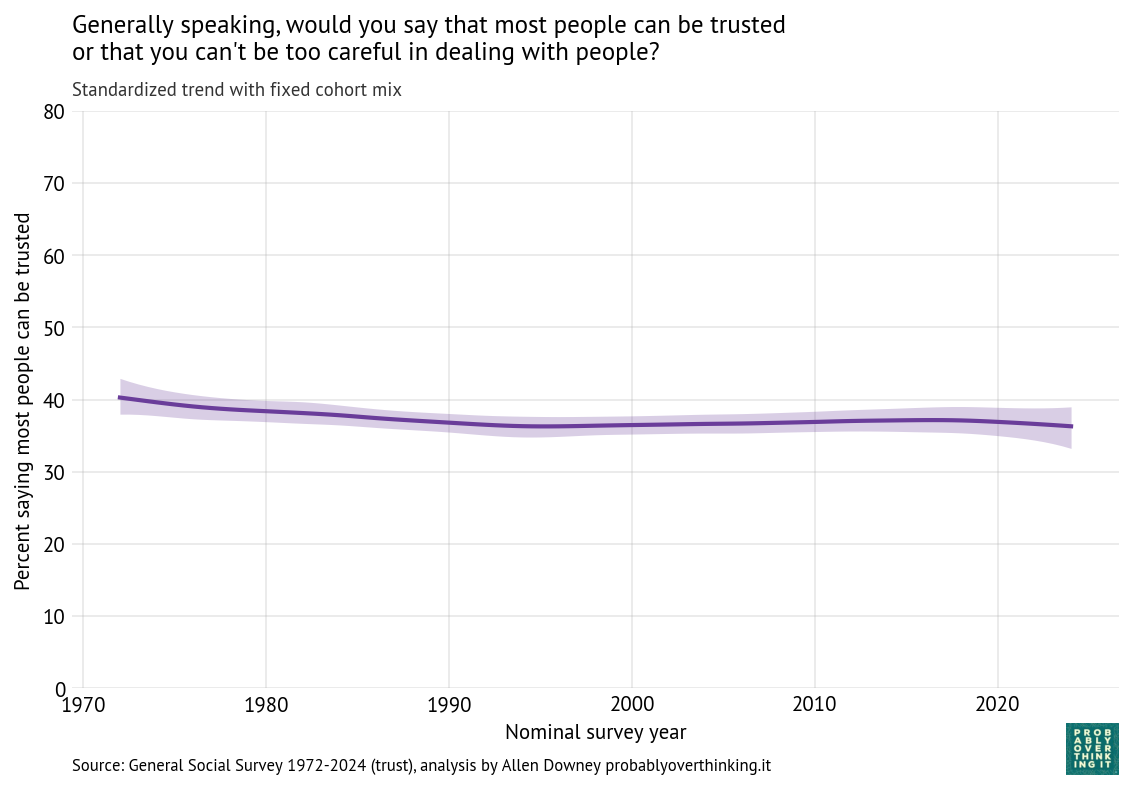
Standardized time trend with fixed cohort mix, percent saying most people can be trusted
In contrast, there is almost no period effect.
The conjecture part
About my previous article, one of my former colleagues said he appreciated my attempt to offer explanations, but reminded me that with this kind of data alone, it is hard to say what causes what with any confidence. That’s true, and it’s a good reminder — but we can get some clues:
- When we see a strong cohort effect and almost no period effect, that’s evidence that we’re seeing patterns set in childhood.
- When we see period effects, we should look for events that affected all cohorts at the same time.
So let’s think about what was happening in the formative years of these cohorts, starting with the 1940 cohort, which was the high point in trust, before the decline:
- Cohort 1940 (childhood: 1940–1960): dense local communities, strong civic and religious institutions, frequent face-to-face interaction, and shared media environment.
- Cohort 1950 (1950–1970): suburbanization expands, some weakening of community density, television becomes widespread but still shared.
- Cohort 1960 (1960–1980): civil rights conflict, Vietnam War, Watergate scandal, rising crime.
- Cohort 1970 (1970–1990): reduced civic participation, rising inequality, more cautious parenting, less unstructured social interaction.
- Cohort 1980 (1980–2000): increasing inequality, more segregation by class and education, early internet exposure, continued decline in shared institutions.
At this point a multi-generational effect comes into play — the parents of Cohort 1980, born in the 1950s and 1960s, were less trusting than previous generations of parents.
- Cohort 1990 (1990–2010): widespread internet use, early social media, more structured childhood, increasing awareness of global risks.
- Cohort 2000 (2000–2020): smartphones and social media throughout formative years, algorithmic content, reduced in-person interaction.
If trust is largely set early in life, then differences between cohorts reflect the environments they experienced during their first two decades.
In addition to this question about trust, the GSS includes related questions about fairness and mutual assistance.
Fair
Do you think most people would try to take advantage of you if they got a chance, or would they try to be fair? The following figure shows the percentage who thought people would be fair.
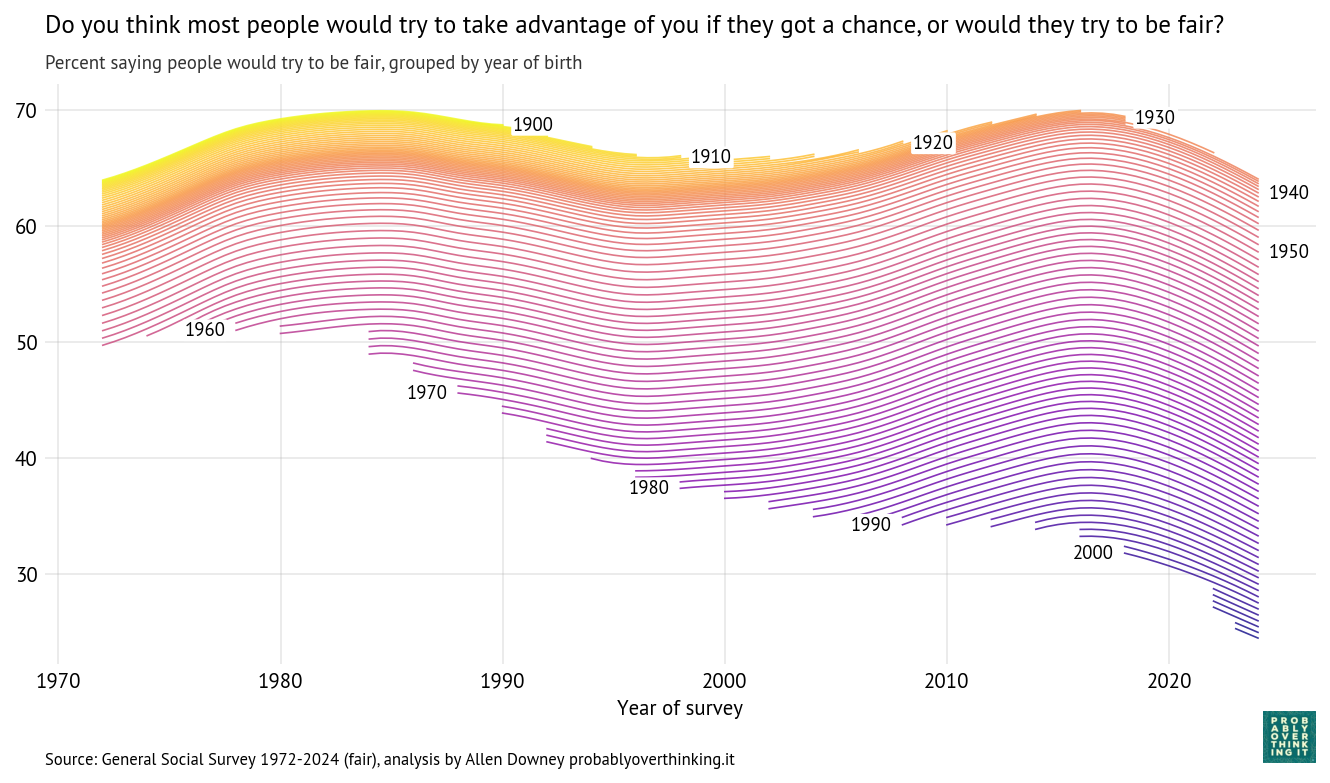
Cohort trajectories, percent saying people would try to be fair
And here’s the cohort effect.
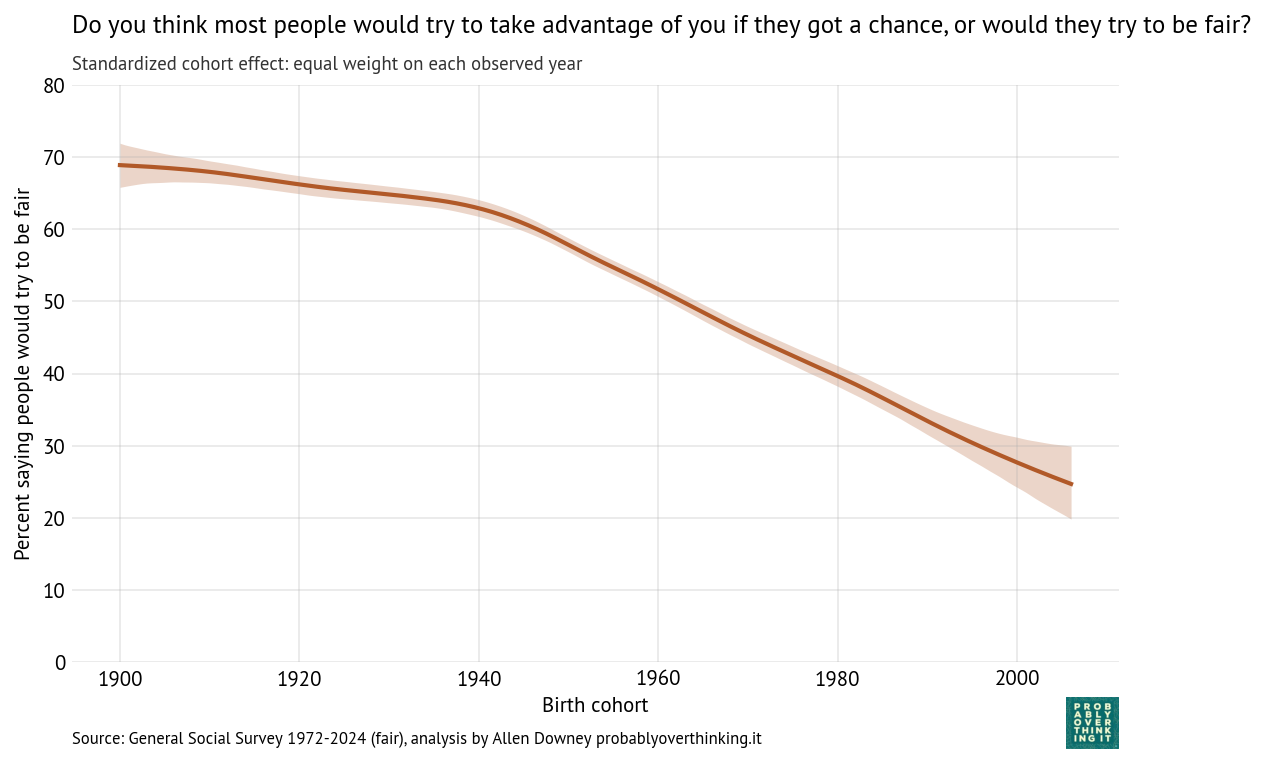
Standardized cohort effect with fixed time mix, percent saying people would try to be fair
And the period effect.
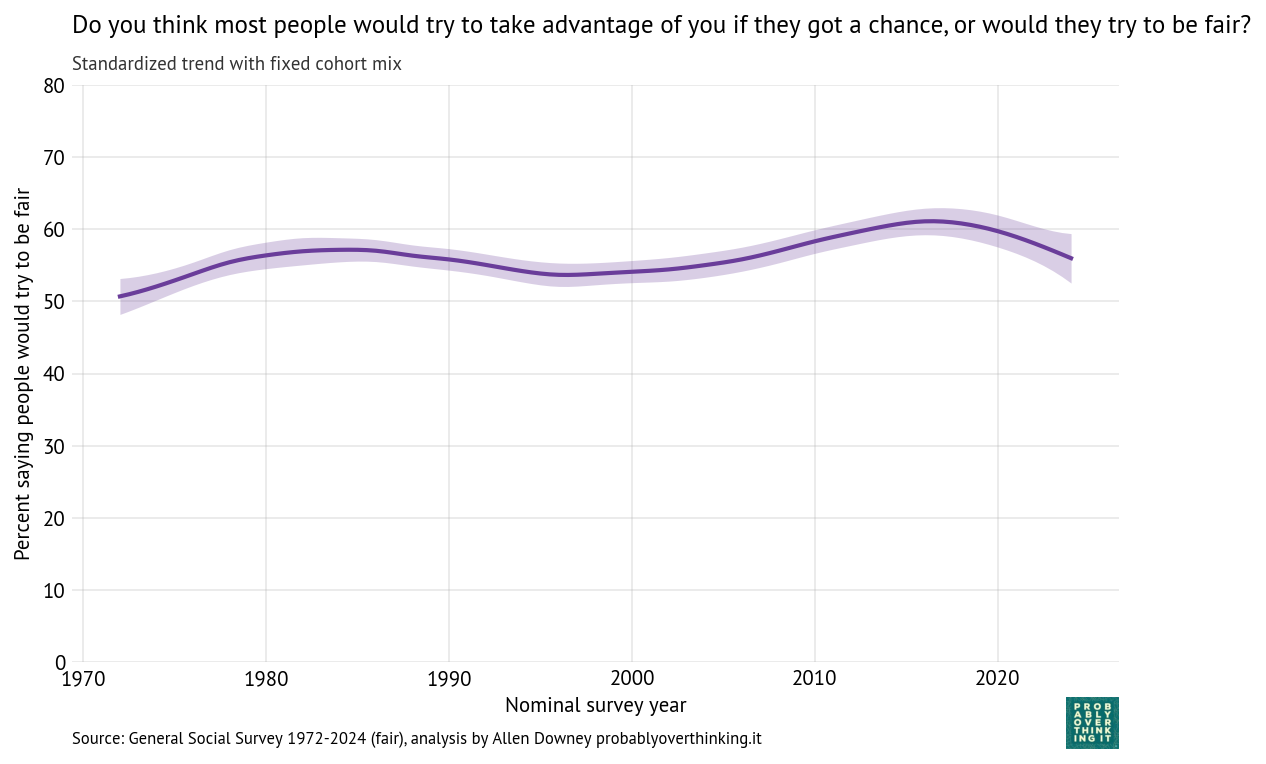
Standardized time trend with fixed cohort mix, percent saying people would try to be fair
The cohort pattern is similar to what we saw in trust: small changes between the 1900s and 1940s cohorts, and then a steep decline — almost 40 percentage points over 60 years.
The period effect is relatively small, varying by only 10 percentage points from lowest to highest point, but it was generally positive until about 2015 (the onset of the Trump Era?).
Helpful
Would you say that most of the time people try to be helpful, or that they are mostly just looking out for themselves?
Here is a period–cohort fingerprint of the responses, showing the percentage who thought people try to be helpful.
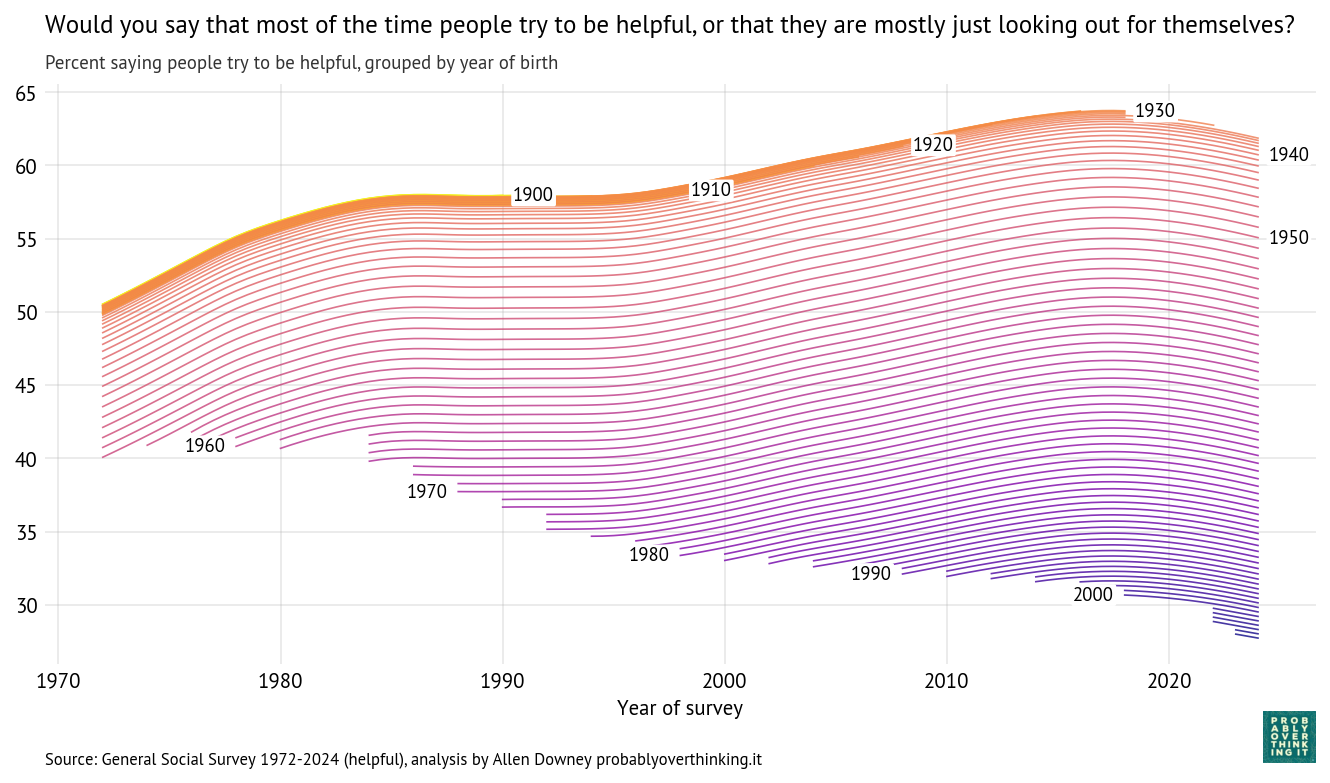
Cohort trajectories, percent saying people try to be helpful
Here’s the cohort effect:
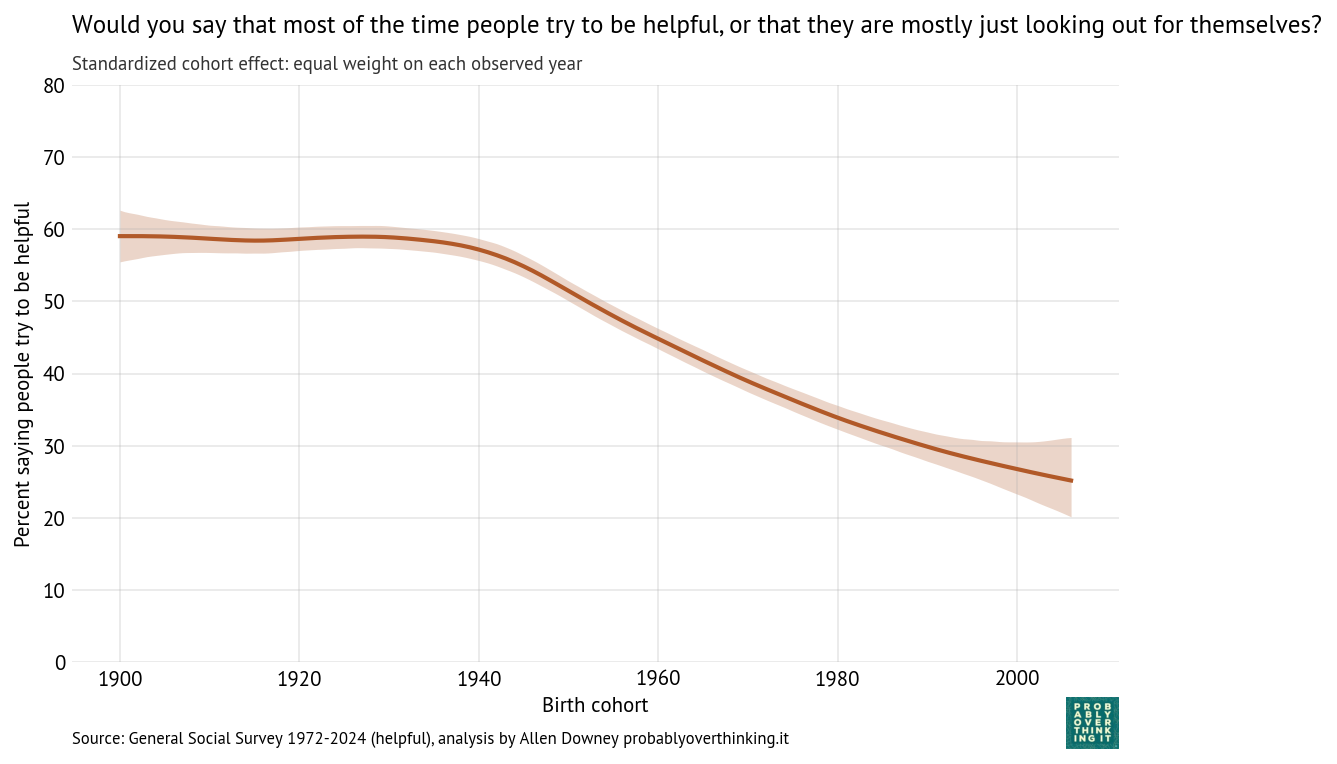
Standardized cohort effect with fixed time mix, percent saying people try to be helpful
And the period effect.
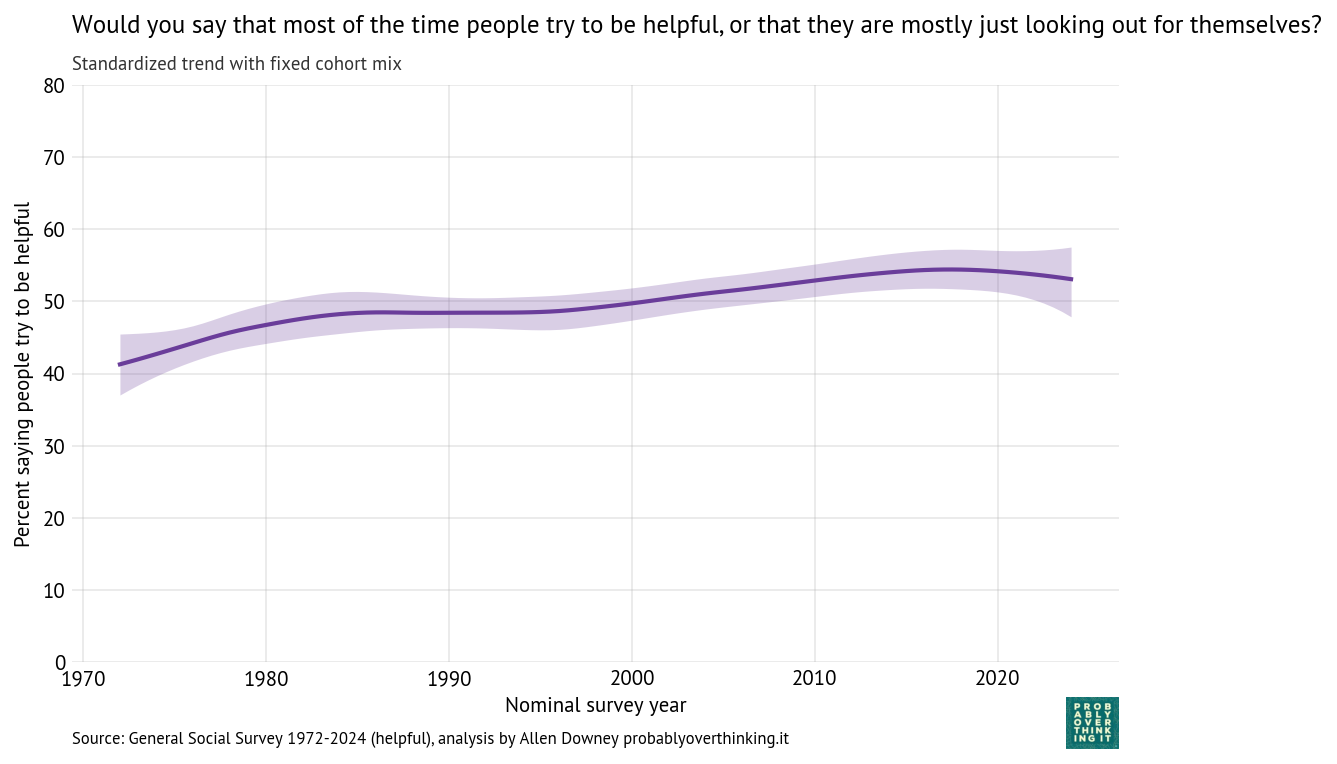
Standardized time trend with fixed cohort mix, percent saying people try to be helpful
Again we see the same pattern: little change between the cohorts born between 1900 and 1940, and then a decline of more than 30 percentage points over 60 years.
And again, the period effect is comparatively small and generally increasing — but possibly declining in the most recent cycles of the survey.
Cause and Effect?
It is plausible that the decline in trust is a contributing factor to the decline in happiness. If you believe that people are out to get you, and 80% of your friends agree, that’s not a worldview conducive to a sense of well-being. And generational decline in trust precedes the decline in happiness, so it is at least a potential cause.
The decline in trust-related beliefs also supports the interpretation that recent cohorts are actually unhappy, rather than interpreting the question differently, or being more willing than previous generations to say they are unhappy.
I haven’t done full-on causal modeling to quantify these relationships, but I ran a few regression models to explore. To reduce the number of researcher degrees of freedom, I asked ChatGPT to interpret the results:
Differences in happiness across cohorts appear to be partly explained by differences in social outlook (trust, fairness, helpfulness), and these outlook variables behave like stable, cohort-structured traits rather than period-driven fluctuations.
The AI-generated summary of the experiments follows.
Model 1: Cross-sectional association (complete cases)
Specification:
- Outcome:
very_happy(binary) - Predictors:
trust,fair,helpful(all binary) - Sample: complete cases with all variables observed
Purpose:
- Estimate the cross-sectional relationship between social outlook and happiness.
- Provides baseline associations without accounting for cohort or period effects.
Interpretation:
- Coefficients represent conditional associations among individuals at a point in time.
- Answers: Are people with a more positive outlook more likely to be very happy?
Model 2: Outlook + cohort + period (restricted sample)
Specification:
- Outcome:
very_happy - Predictors:
trust,fair,helpfulcohort_c(mean-centered birth year)year_c(mean-centered survey year)
- Sample: respondents born ≥ 1940 with complete data
Purpose:
- Assess whether the outlook–happiness relationship persists after accounting for:
- Cohort effects (differences across birth cohorts)
- Period effects (changes over survey years)
Interpretation:
- Coefficients for outlook variables reflect within-cohort, within-period associations.
- Cohort and year coefficients capture linear trends in happiness after controlling for outlook.
- Answers:
- Are outlook variables still associated with happiness after adjusting for historical context?
- Is there an independent cohort or period trend?
Model 3: Cohort + period only (no outlook variables)
Specification:
- Outcome:
very_happy - Predictors:
cohort_cyear_c
- Sample: respondents born > 1940 (larger sample since outlook variables not required)
Purpose:
- Estimate total cohort and period effects on happiness without controlling for outlook.
- Provides a baseline for comparison with Model 2.
Interpretation:
- Cohort and year coefficients reflect combined (direct + indirect) effects.
- Comparing to Model 2 shows how much of these effects are accounted for by outlook variables.
- Answers:
- How does happiness vary across cohorts and over time in aggregate?
- How much do these patterns change when outlook is included?
Key Findings
- Positive social outlook is associated with higher happiness.
- Trust, fairness, and helpfulness all have positive and statistically significant associations with being “very happy.”
- Estimated odds ratios:
- Trust: ~1.25
- Fairness: ~1.36 (strongest)
- Helpfulness: ~1.29
- These effects are modest in size and explain a small fraction of overall variation (Pseudo R² ≈ 0.016).
- These relationships are stable across cohorts and time.
- Adding cohort and survey year controls has little effect on the coefficients.
- This suggests the outlook–happiness relationship is primarily cross-sectional, not driven by historical shifts.
Cohort and Period Effects
- Without controlling for outlook:
- Later cohorts are less likely to report being very happy.
- There is also a negative period trend (declining happiness over time).
- With outlook variables included:
- The cohort effect becomes small and statistically insignificant.
- The period effect remains negative and significant.
Interpretation
- Outlook variables appear to mediate cohort differences in happiness.
- Later cohorts tend to report lower trust, fairness, and helpfulness.
- These differences account for much of the observed cohort decline in happiness.
- Period effects persist independently.
- There is a modest downward trend in happiness over time that is not explained by outlook variables.
Data Considerations
- Approximately 40% of observations are missing at least one outlook variable, reducing the complete-case sample.
- This raises the possibility of selection bias in the estimates.
Bottom Line
- A more positive view of others (trust, fairness, helpfulness) is consistently associated with higher happiness.
- Differences in these outlook measures help explain why later cohorts report lower happiness.
- However, there is also an independent downward trend in happiness over time.