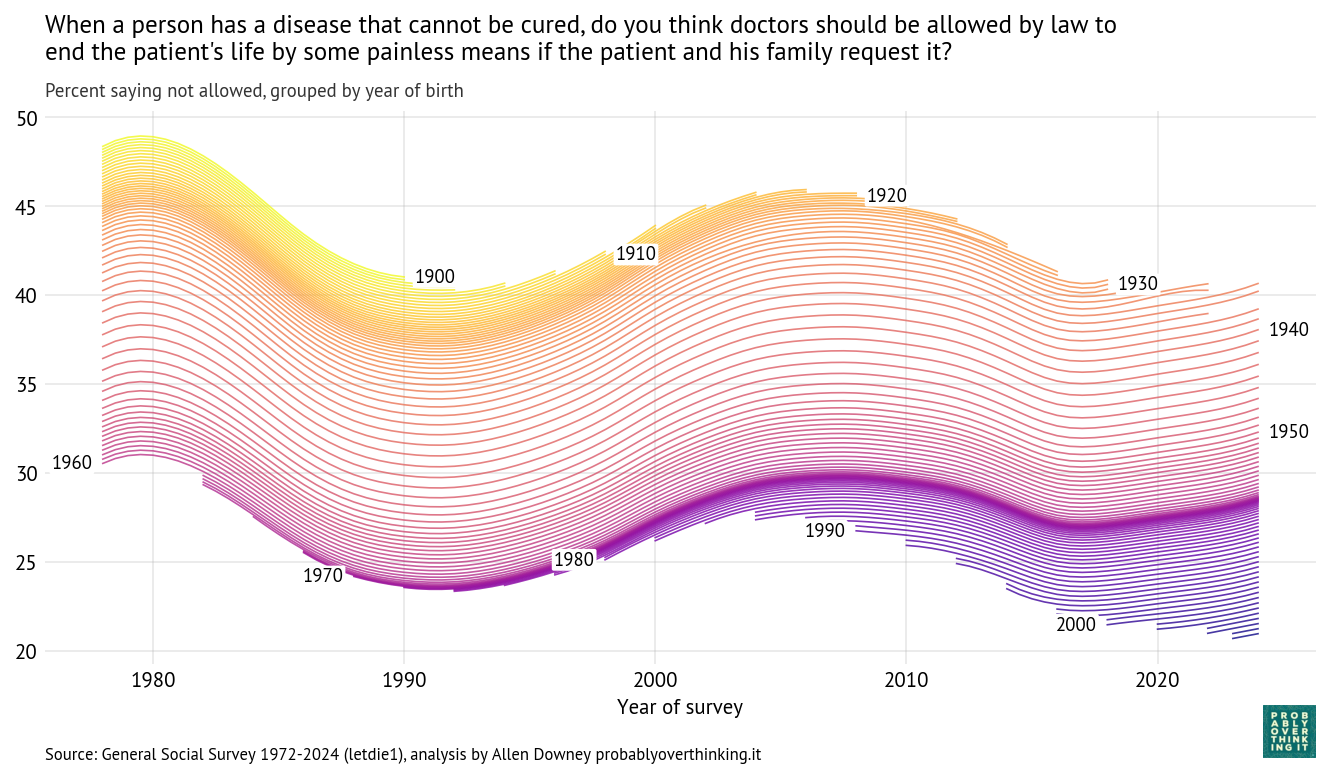
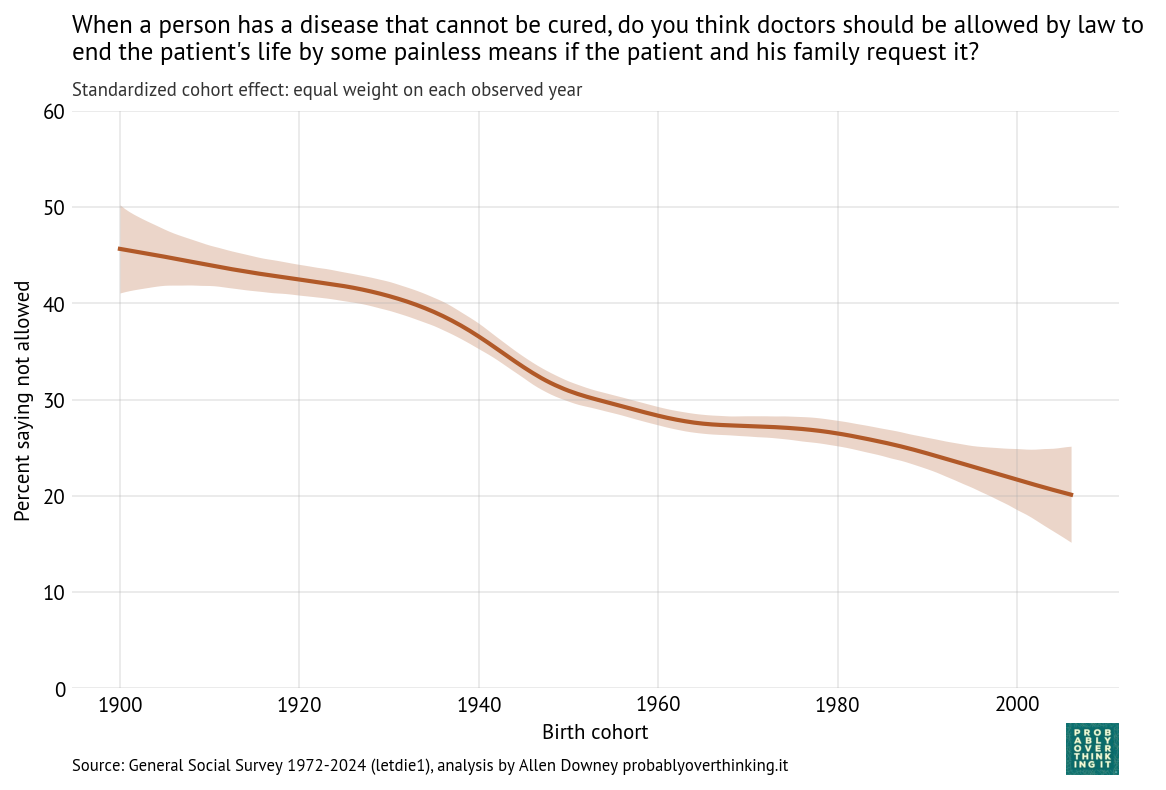
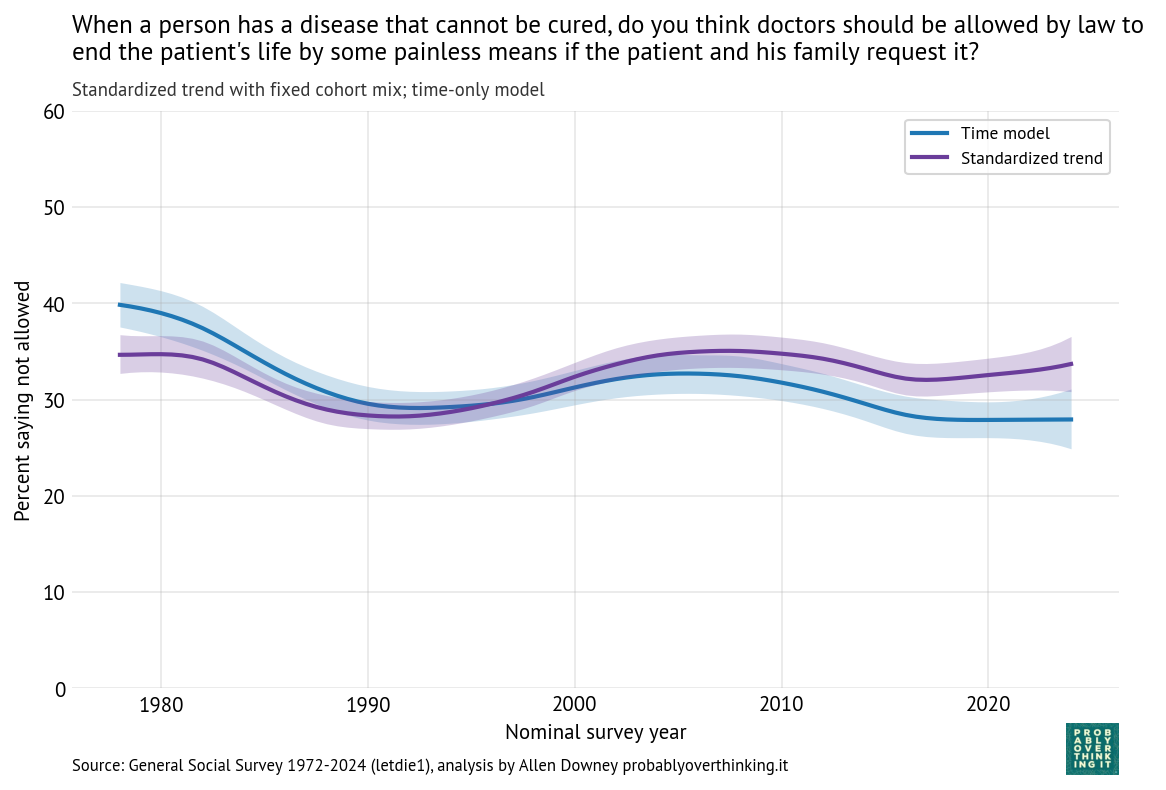
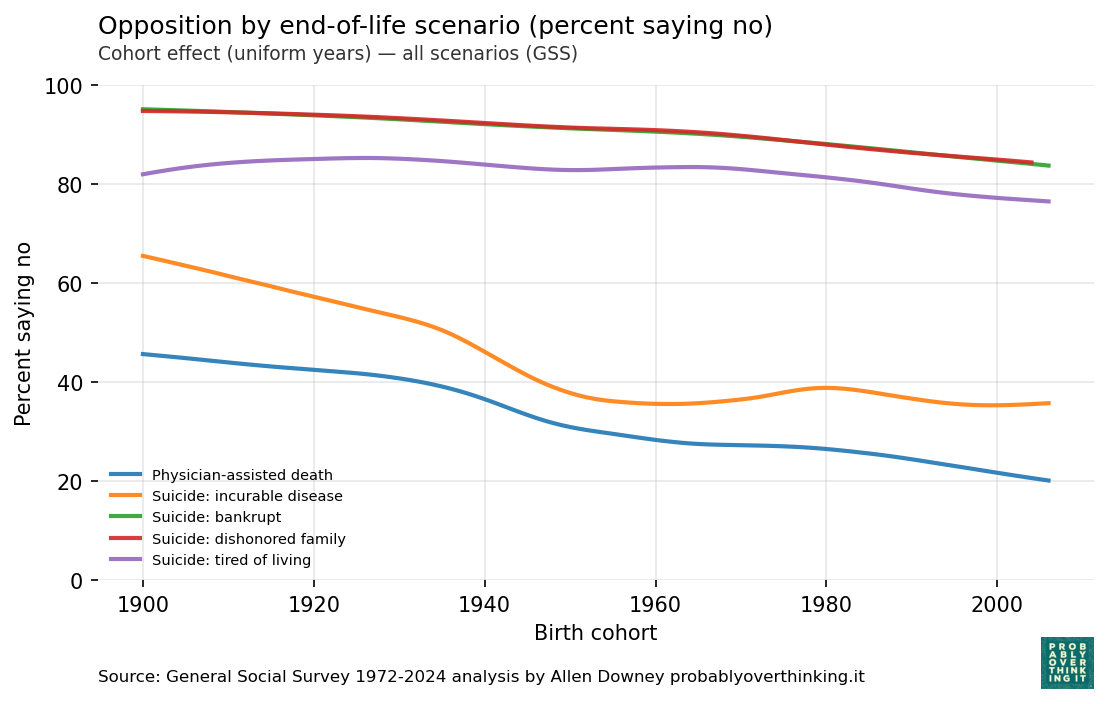
Confidence in Institutions
This article is one of a series exploring responses to core questions in the General Social Survey (GSS), estimating period and cohort effects, and looking for historical events that might explain the trends we see.
Confidence in American institutions
In this installment, we’ll look at 13 questions related to confidence in institutions. We’ll start with a detailed look at confidence in “the people running Congress”, and then summarize results from the other questions. The complete survey question is:
I am going to name some institutions in this country. As far as the people running these institutions are concerned, would you say you have a great deal of confidence, only some confidence, or hardly any confidence at all in […] Congress.
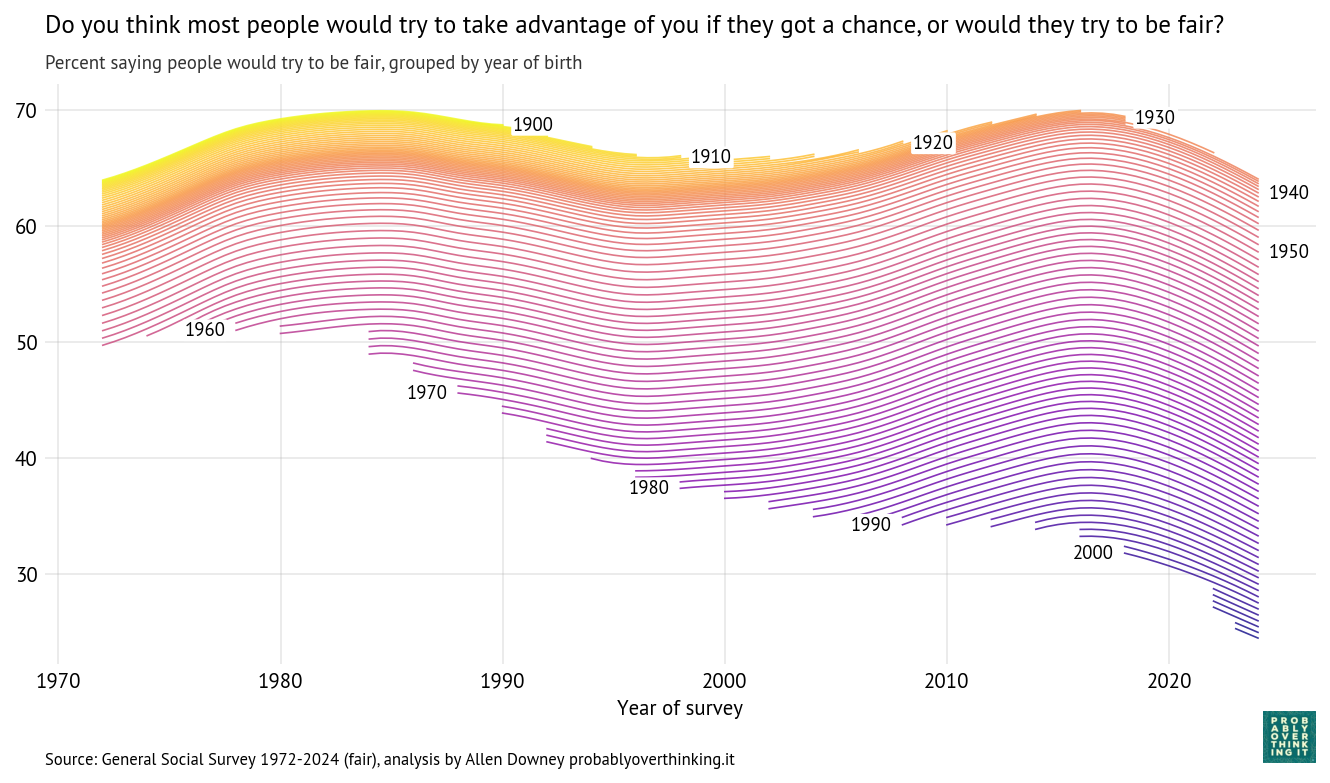
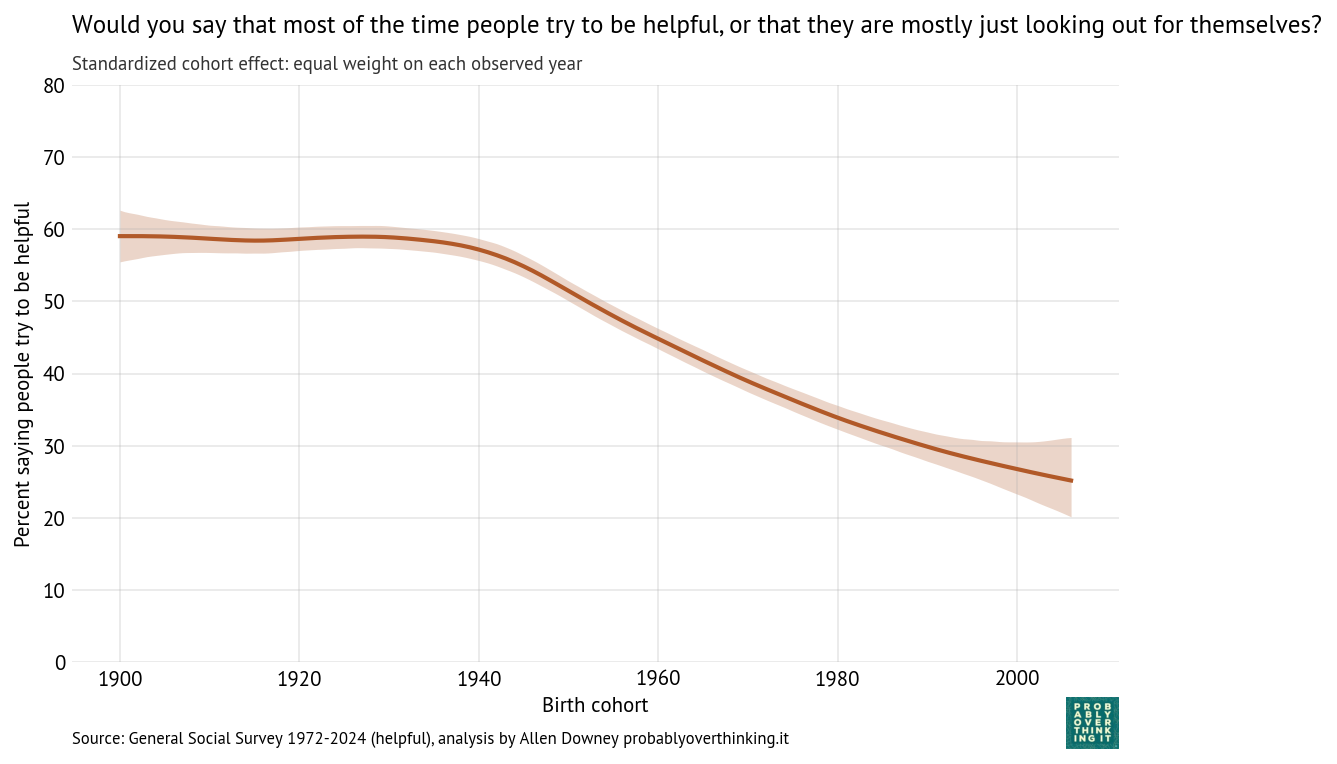
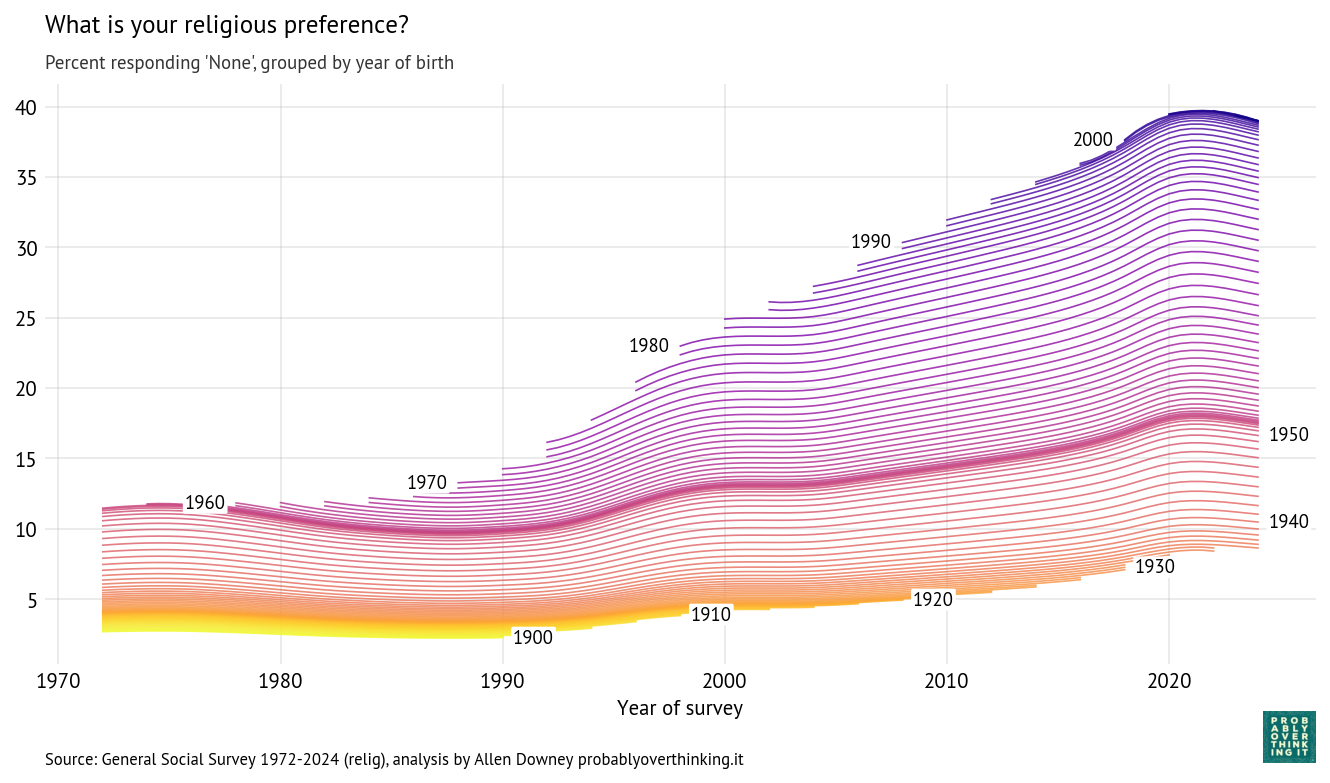
The following figure shows the fraction of people who answered “a great deal of confidence” or “only some confidence,” and a smooth line fitted to the raw percentages.
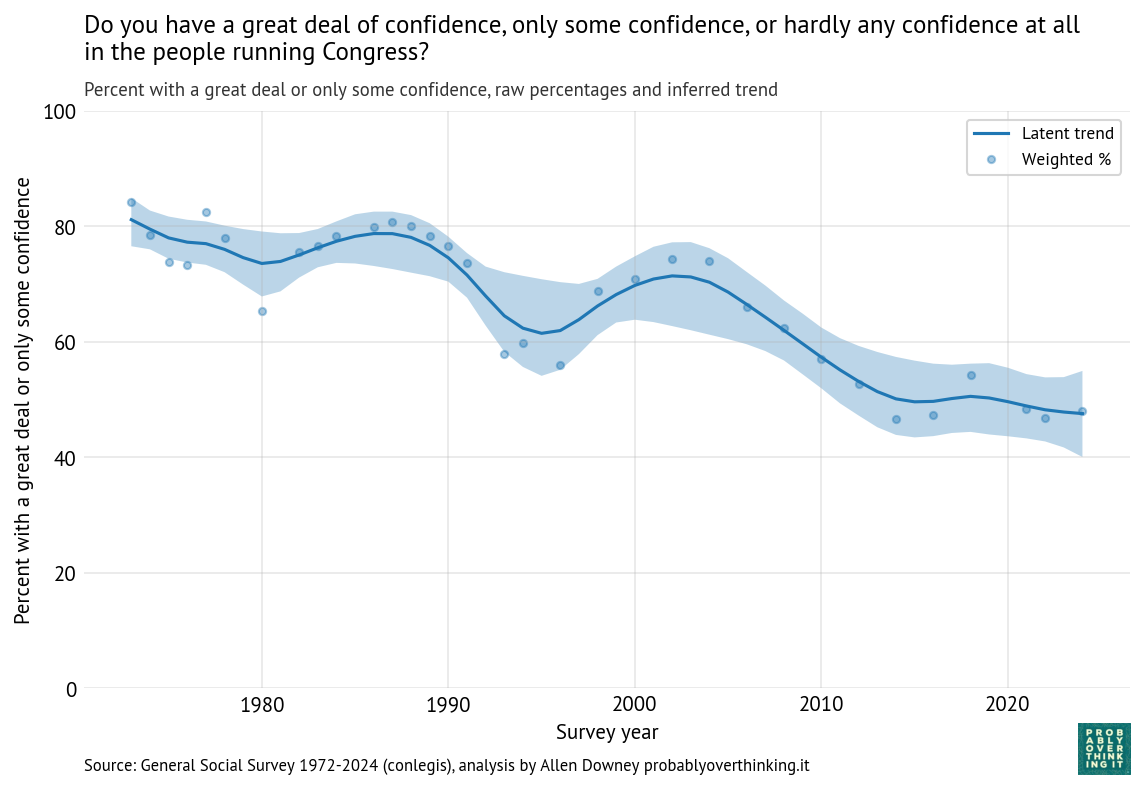
The long-term trend is downward, from about 80% during the first iteration of the survey to below 50% in the most recent iterations. But there are ups and downs.
It looks like confidence was increasing during the 1980s before collapsing in the early 1990s. Possible causes of the decline include:
- The House banking scandal, also known as Rubbergate, and the Congressional Post Office scandal.
- Increased polarization and perception of dysfunction during the period when Newt Gingrich was minority whip (1989-1995).
- An economic recession from 1990 into 1991.
Confidence in Congress recovered between 1995 and 2005, and declined again between 2005 and 2015. A likely contributor is the Great Recession from late 2007 to mid-2009.
This period also saw the rise of anti-establishment politics, including the Tea Party movement and Ron Paul’s presidential campaign.
Now we’ll decompose these changes into period and cohort effects.
Period and cohort effects
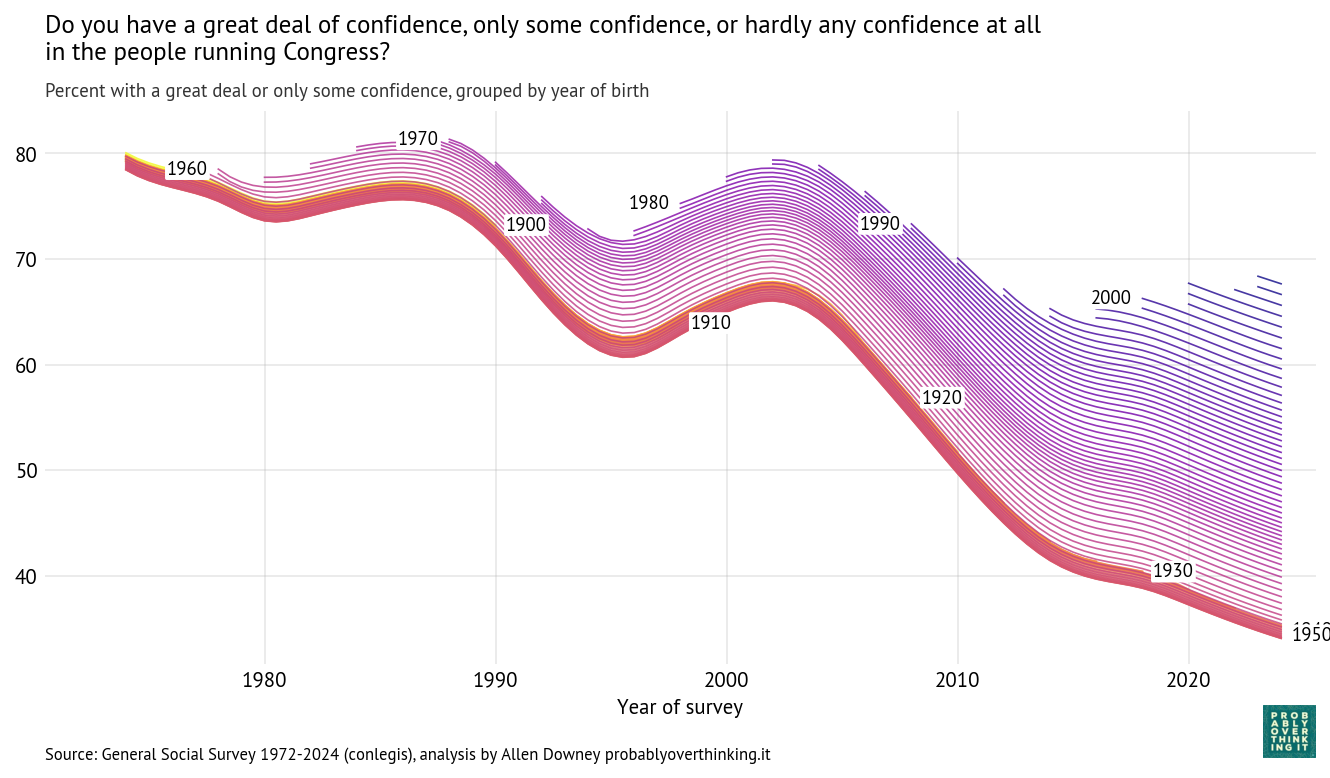
Using the Bayesian model described here we can estimate a latent “confidence in Congress” factor for each birth cohort over time. The following figure shows these estimates; each line represents a single birth year.
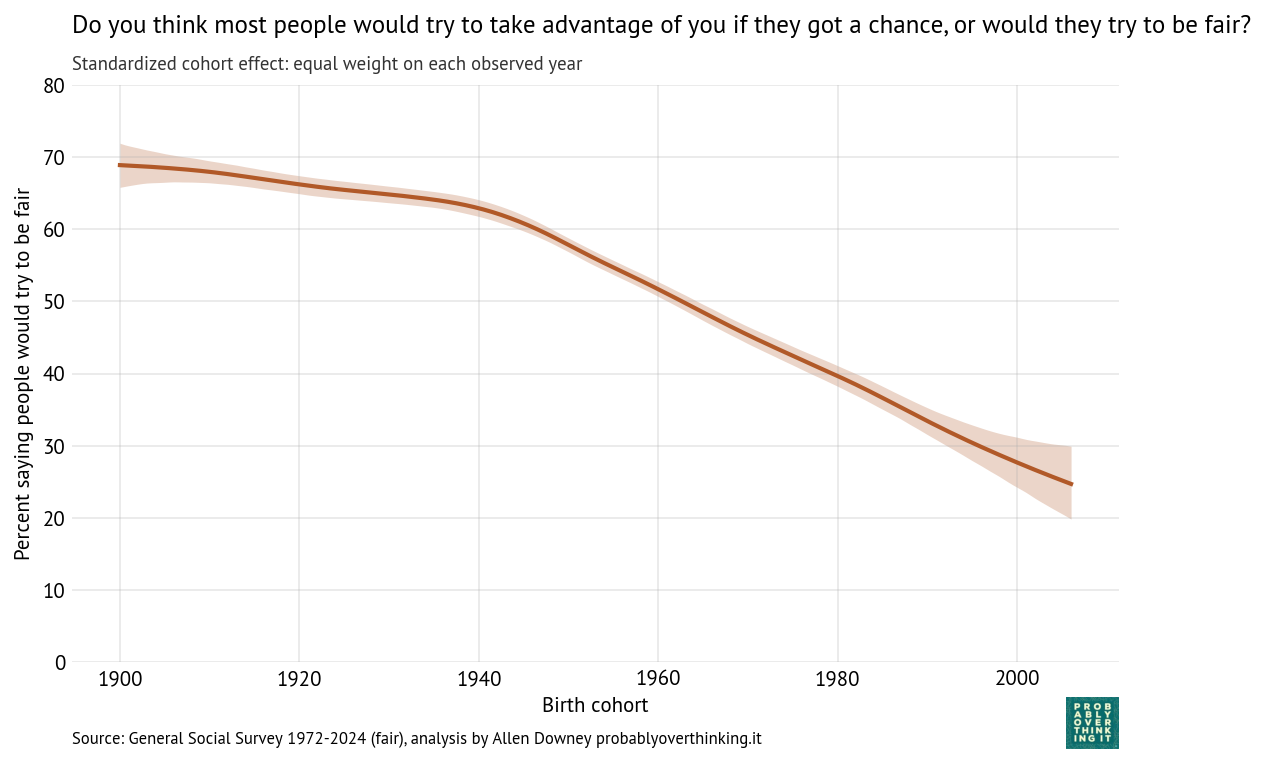
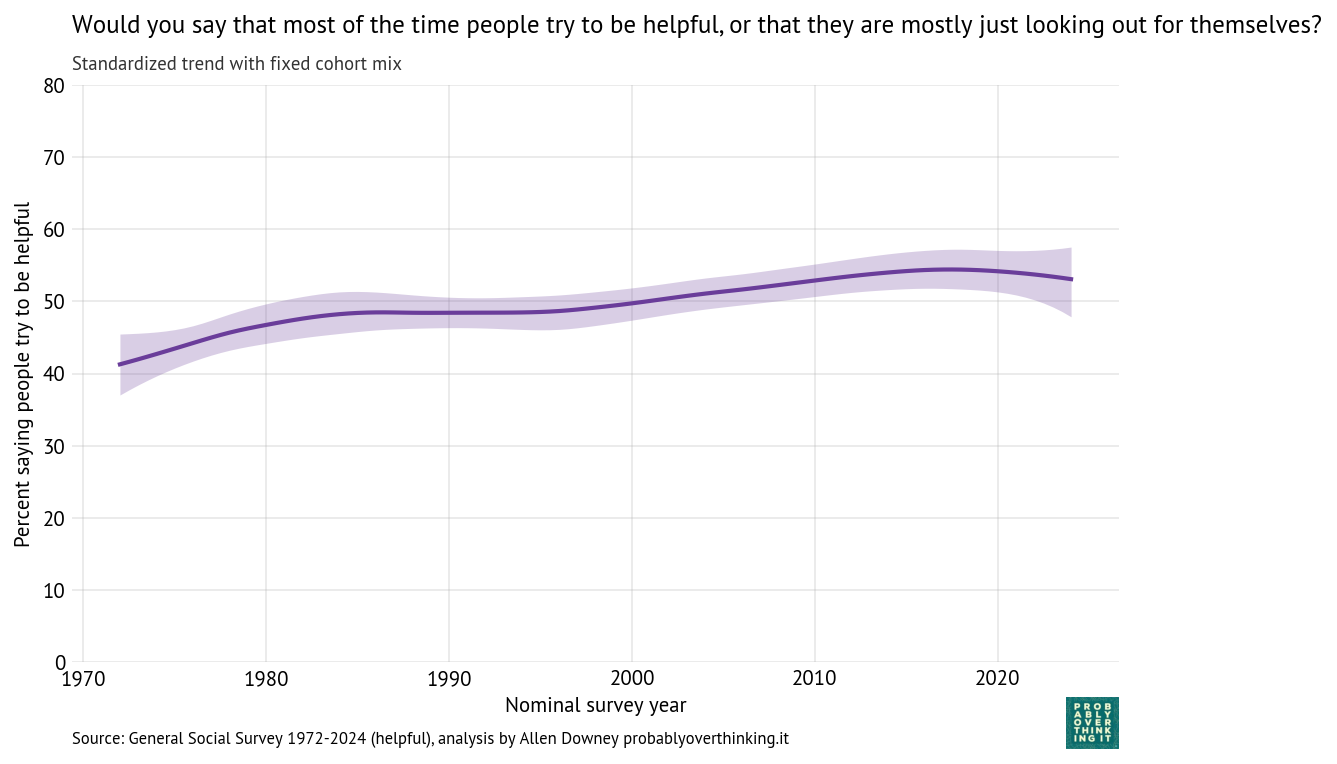
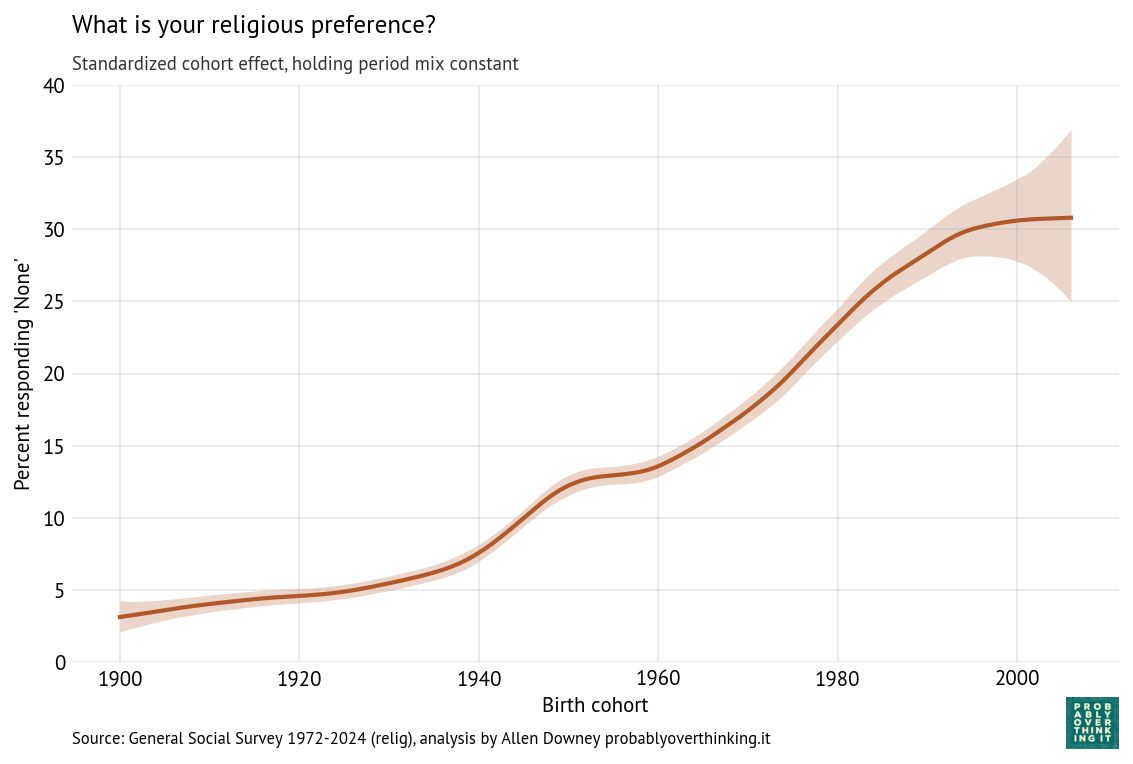
Those results are easier to interpret if we factor out the cohort effect (keeping the mixture of survey years constant) and the period effect (keeping the mixture of cohorts constant). The following figure shows the standardized cohort effect.
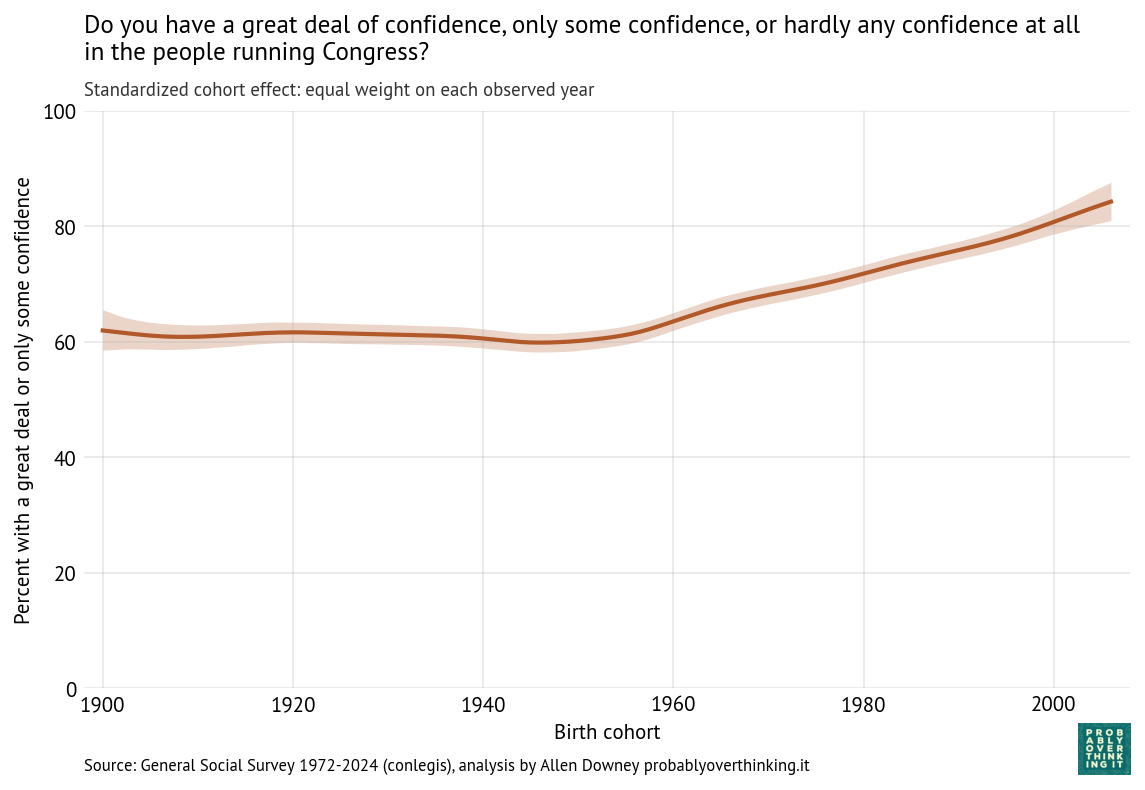
Among people born between 1900 and 1950, there is almost no change. Then starting with people born in the 1960s, confidence in Congress has increased consistently and substantially.
To interpret this result, it is helpful to go back to the previous figure. Starting in the upper left:
- Among people born in the 1960s and 1970s, about 80% reported confidence in Congress when they were surveyed as young adults.
- Among people born in the 1980s and 1990s, it was closer to 70%.
- And among people born in the 2000s it’s below 70%.
The entry point of each cohort is below the entry point of previous cohorts, but because these entry points are above the declining trend of previous generations, this relative optimism is interpreted as an increasing cohort effect.
So we should not conclude that younger generations are more confident in Congress, only that when they are first surveyed, they start out above the trajectory of previous cohorts.
As a simplification, we might imagine an 18-year-old entering adulthood with a relatively idealized understanding of American government — shaped by civics classes and maybe a school trip to Washington D.C. — before later political experiences erode some of that confidence.
Another possibility is that younger generations have grown up with lower expectations of government, so when they say they have “some confidence”, they might be evaluating Congress against a lower standard.
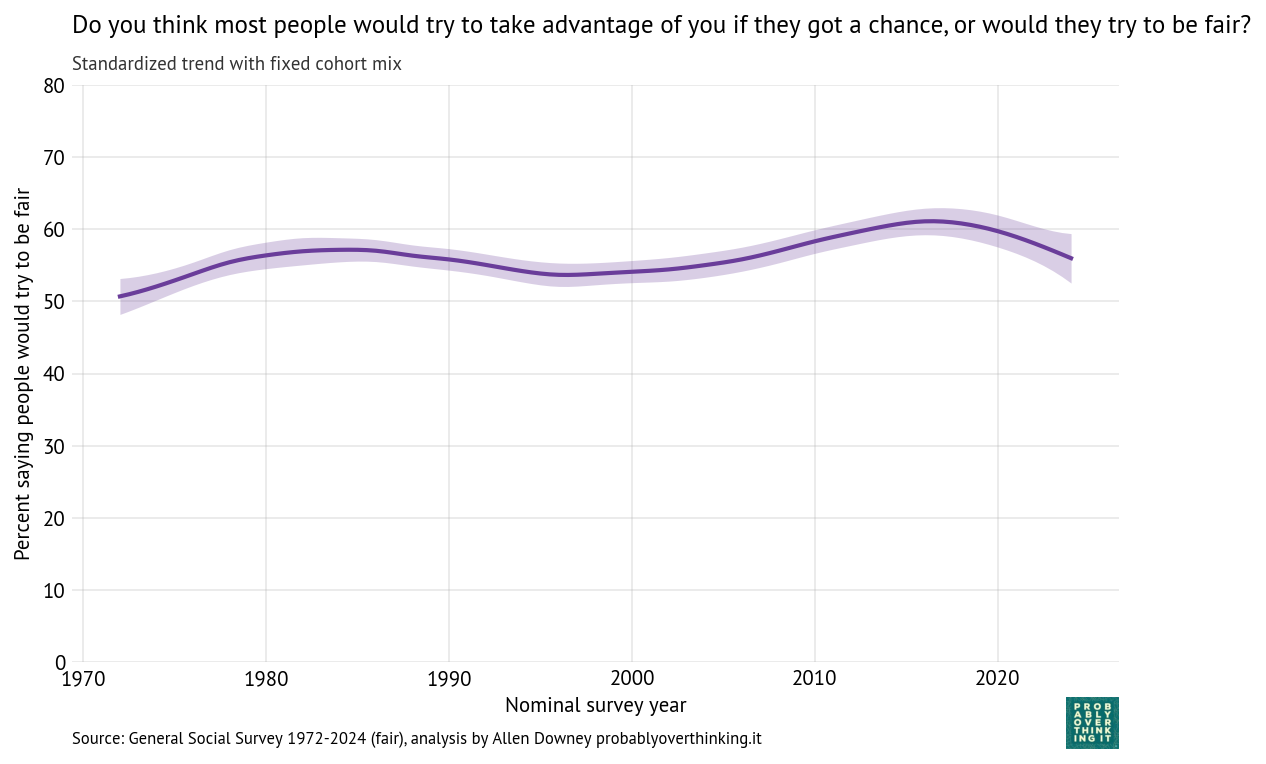
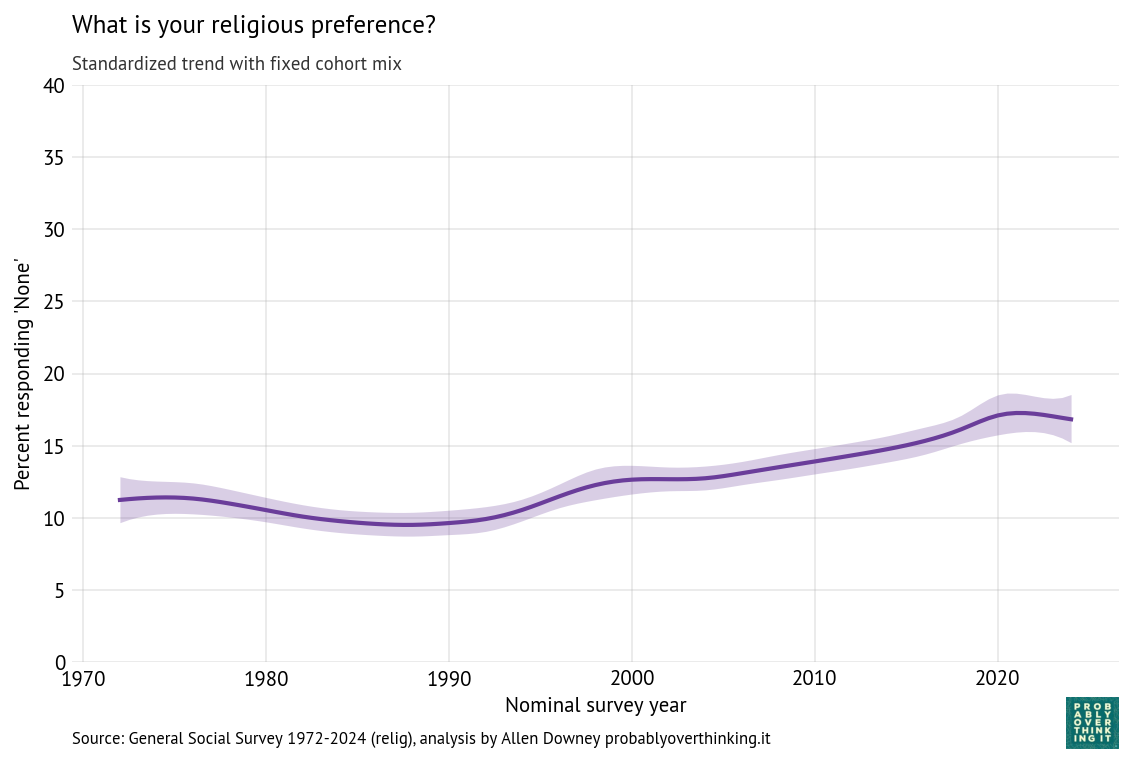
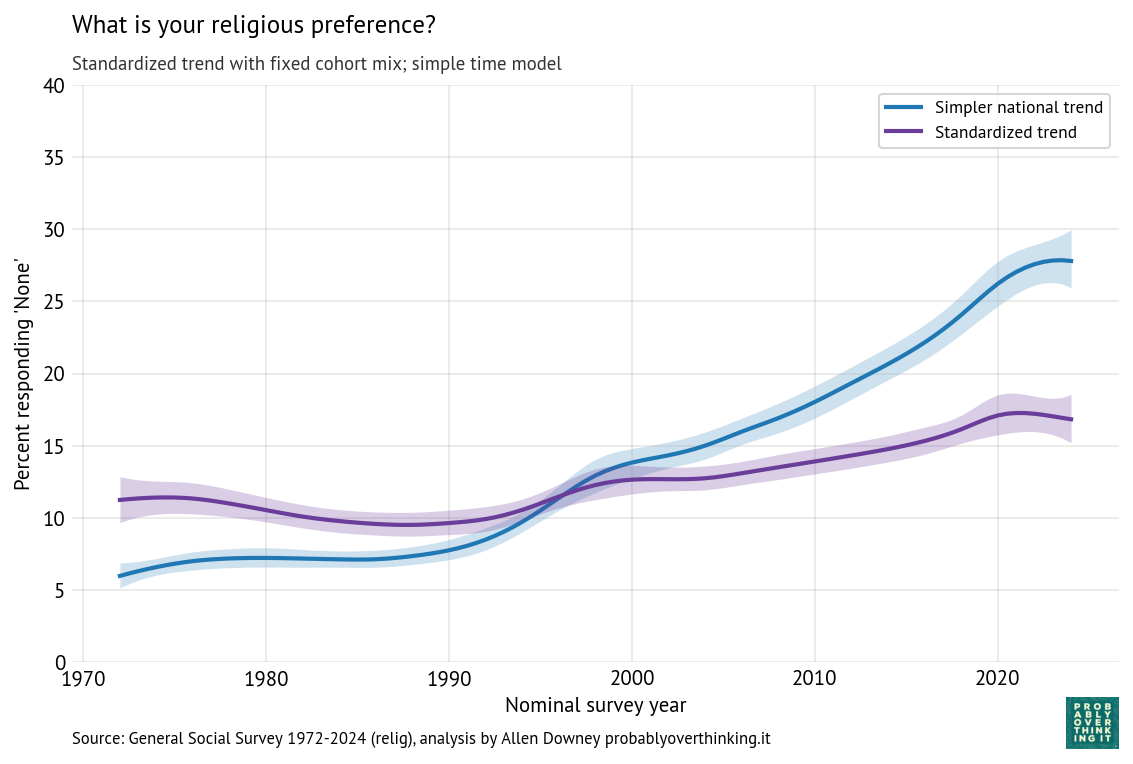
The following figure shows the estimated period effect, with the mix of cohorts held constant.
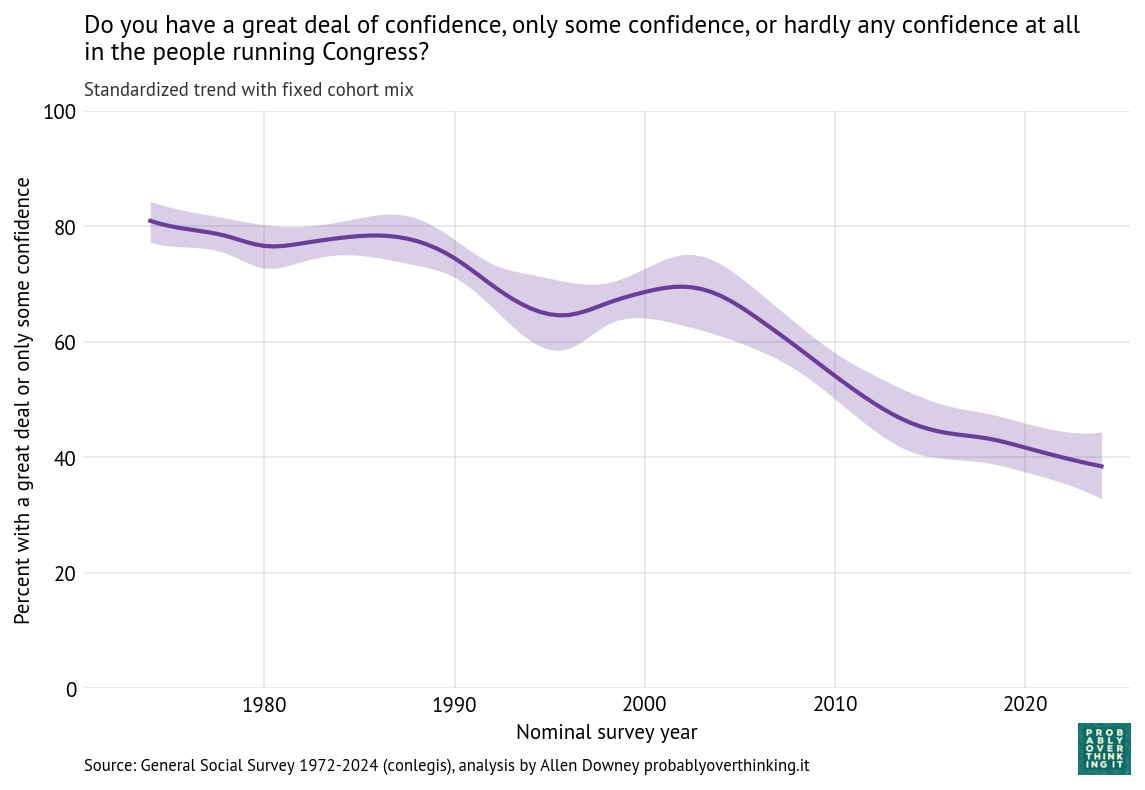
This decline is steeper than what we saw in the time-only model, because we have factored out the mitigating effect of relative optimism in recent generations.
Government Institutions
Now we’ll apply the same analysis to questions about the executive branch of the federal government, the Supreme Court, and the military (technically part of the executive branch).
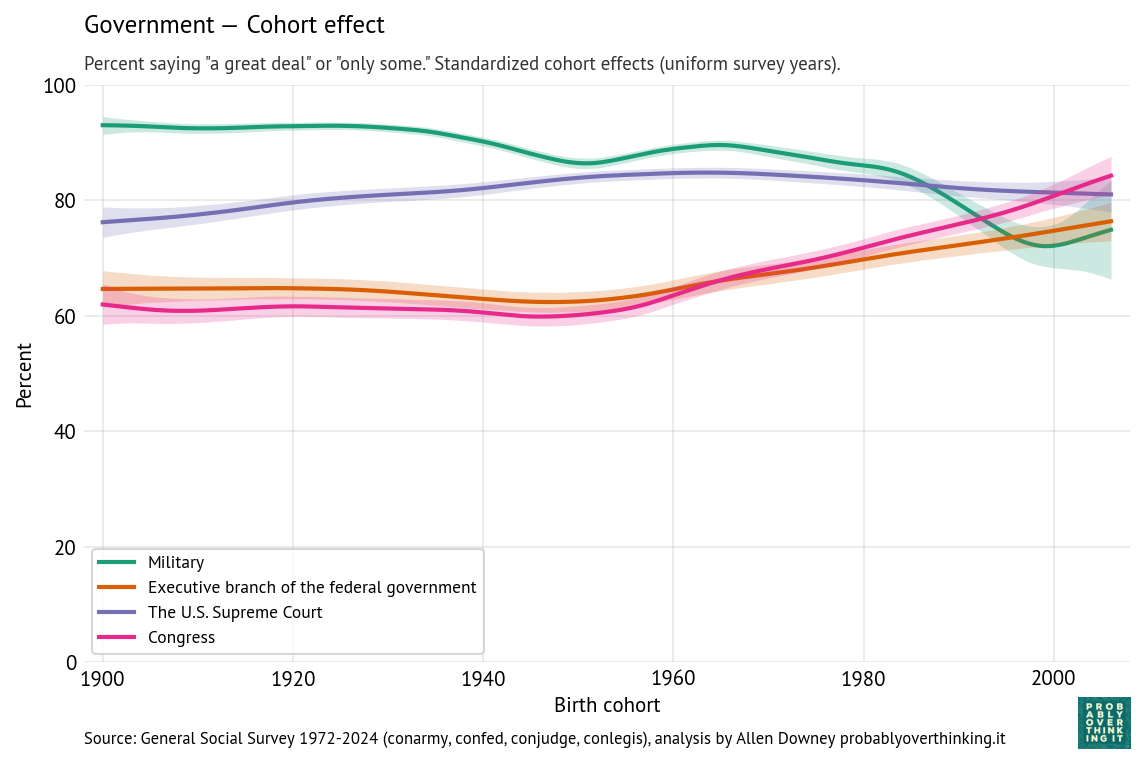
The following figure shows the estimated cohort effects for each of these institutions.
And the following figure shows the period effect, after factoring out the cohort effect.
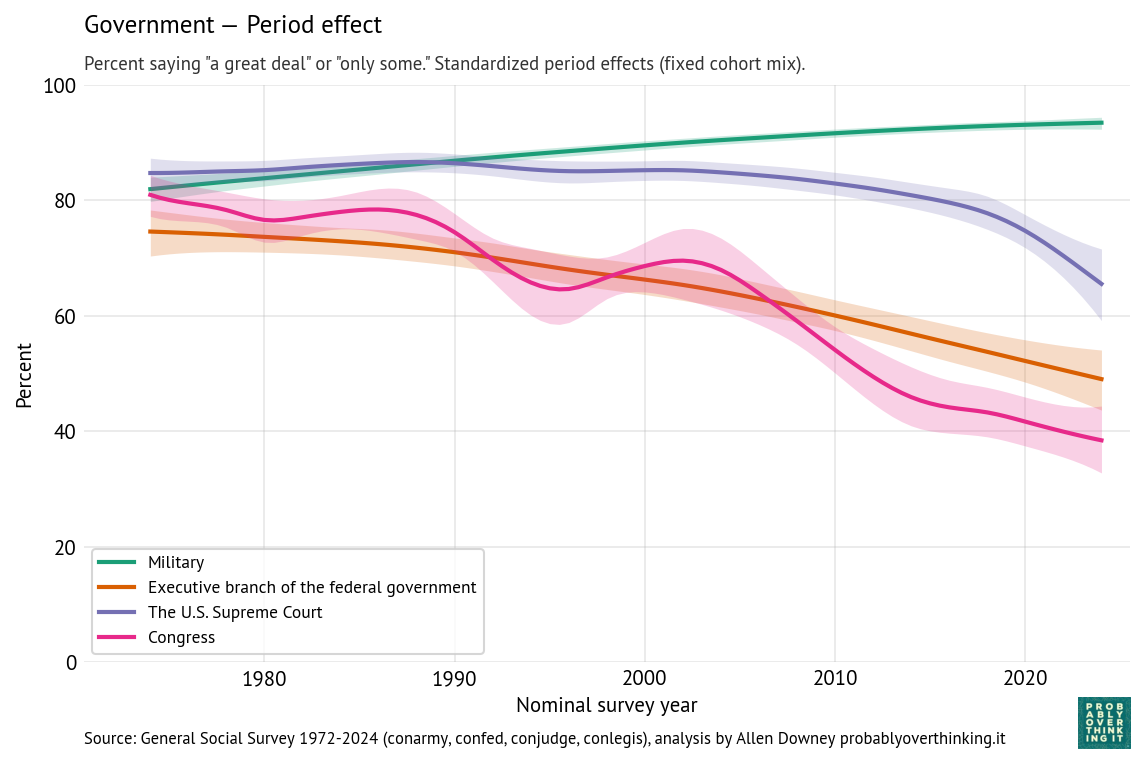
The results for the executive branch are similar to the results for Congress.
- The cohort effect is flat between people born in the 1900s and 1950s, and increasing after that.
- The period effect declines substantially and consistently — without the ups and downs of confidence in Congress.
When respondents are asked about the “executive branch”, it’s not clear whether they think primarily about the president, federal agencies, or the federal government in general.
The patterns for the military and Supreme Court are different.
- Confidence in the military is generally high. The cohort effect declined gradually, and possibly more steeply among people born after 1980. The period effect gradually increased.
- Confidence in the Supreme Court is higher than confidence in other branches, although the period effect has dropped steeply since 2015. The cohort effect increased among people born between 1900 and 1960; among more recent generations it is gradually declining.
Historically, the Court cultivated an image of being above politics; that perception weakened substantially in the 2010s. In March 2016, Merrick Garland was nominated to the Supreme Court after the death of Antonin Scalia. The Republican majority in the Senate refused to hold a hearing or vote on his nomination. The seat remained empty until Donald Trump nominated, and the Senate confirmed, Neil Gorsuch, who is considered to be more conservative. To many liberals, the Senate’s 293-day blockade undermined the legitimacy of the Court.
Then when Ruth Bader Ginsburg died in September 2020, Donald Trump nominated Amy Coney Barrett and the Senate confirmed her 8 days before the 2020 presidential election, in a process criticized by Democratic leaders as illegitimate.
These appointments, along with the confirmation of Brett Kavanaugh in 2018, shifted the composition of the Court toward conservatives, forming what is now described as a 6-3 supermajority of conservative justices.
Since then, the Supreme Court has issued several decisions contrary to majority public opinion, most notably the 2022 decision overturning Roe v. Wade. Other unpopular decisions weakened gun control and limited federal regulatory authority, especially over environmental policy. Many of these decisions have been perceived, especially on the left, to be motivated by politics rather than constitutional principles and precedent.
The slope of the cohort effect might reflect a generational change in associations with the Supreme Court. Older cohorts may associate the Supreme Court with landmark decisions like Brown v. Board of Education and the expansion of civil rights. Younger cohorts may instead associate it with partisan conflict, blocked reforms, and ideological polarization. Older generations might also have been more deferential toward the institution itself. Younger generations, exposed to more adversarial and partisan media coverage, might be less inclined to deference.
Economic institutions
The following figures show the cohort and period effects for confidence in economic institutions: banks, major companies, and organized labor.
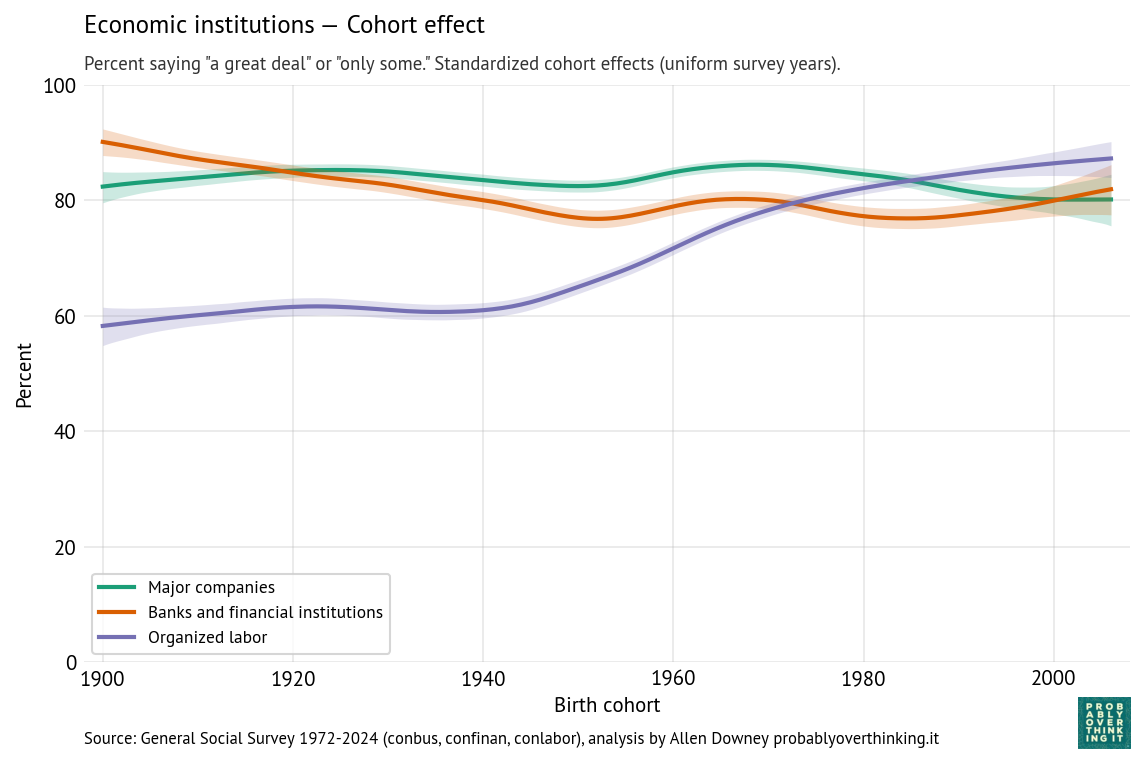
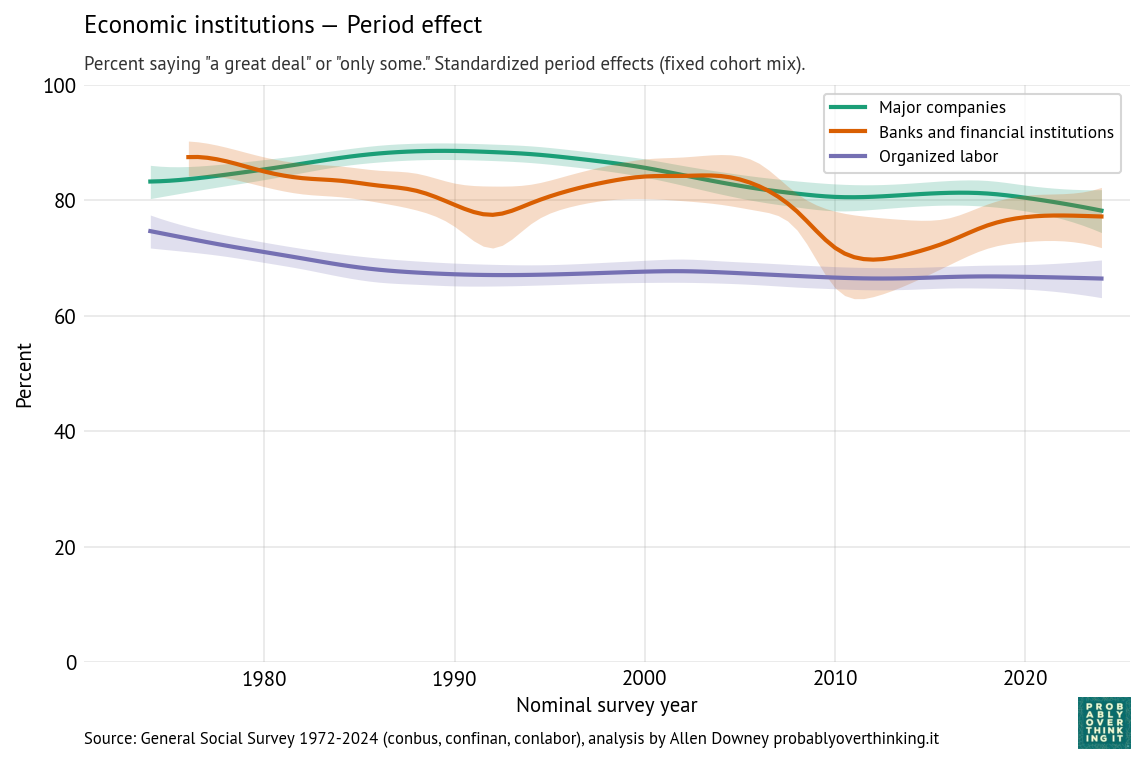
Confidence in these institutions is generally high. Looking at the cohort effects, the most salient feature is increased confidence in organized labor among people born after 1940.
A possible explanation is that younger cohorts have less exposure to organized labor. Older generations were more likely to be affected by strikes and related economic disruption, and more likely to be aware of corruption in labor unions. As union membership has declined and the gig economy has expanded, younger cohorts are less aware of the negative aspects of organized labor, including dues, and more likely to perceive their lack of negotiating power in the labor market. Also, anti-labor ideology has declined since the end of the Cold War, as the framing has shifted from “labor versus management” to “workers versus corporations”.
By comparison with the cohort effects, the period effects are modest:
- The period effect on organized labor is almost unchanged since the 1980s — the change we see over time is almost entirely due to generational replacement.
- The period effect on confidence in major companies has declined somewhat.
- The trend for banks and financial institutions is more complicated — arguably driven by shorter-term period effects like scandals and financial crises. The first notable downturn, in the 1980s, coincides with the savings and loan crisis, when hundreds of financial institutions failed and taxpayers absorbed large bailout costs, followed by an economic recession from 1990 into 1991. The larger downturn around 2008 coincides with the 2008 global financial crisis, when taxpayers were hit with even larger bailout costs, and public anger at “private gains, public losses” came to a focus in the Occupy Wall Street protests.
Professions, knowledge, and religion
The following figures show estimated cohort and period effects for confidence in education, medicine, the scientific community, and organized religion.
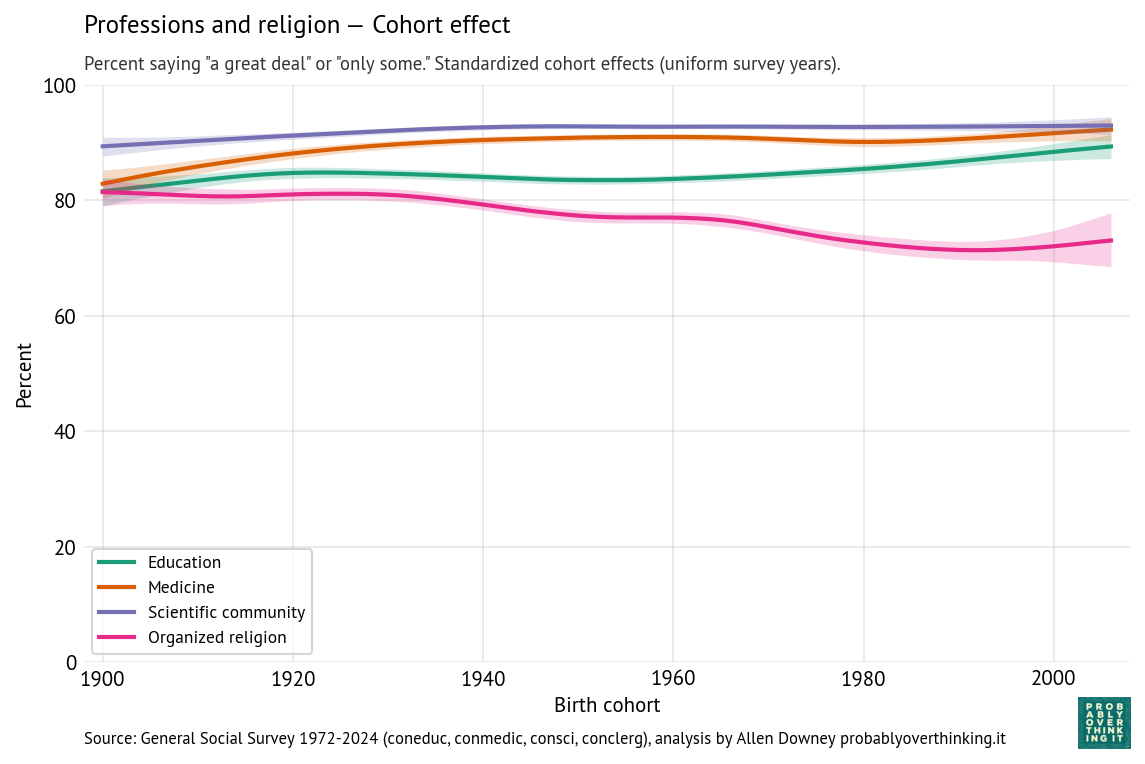
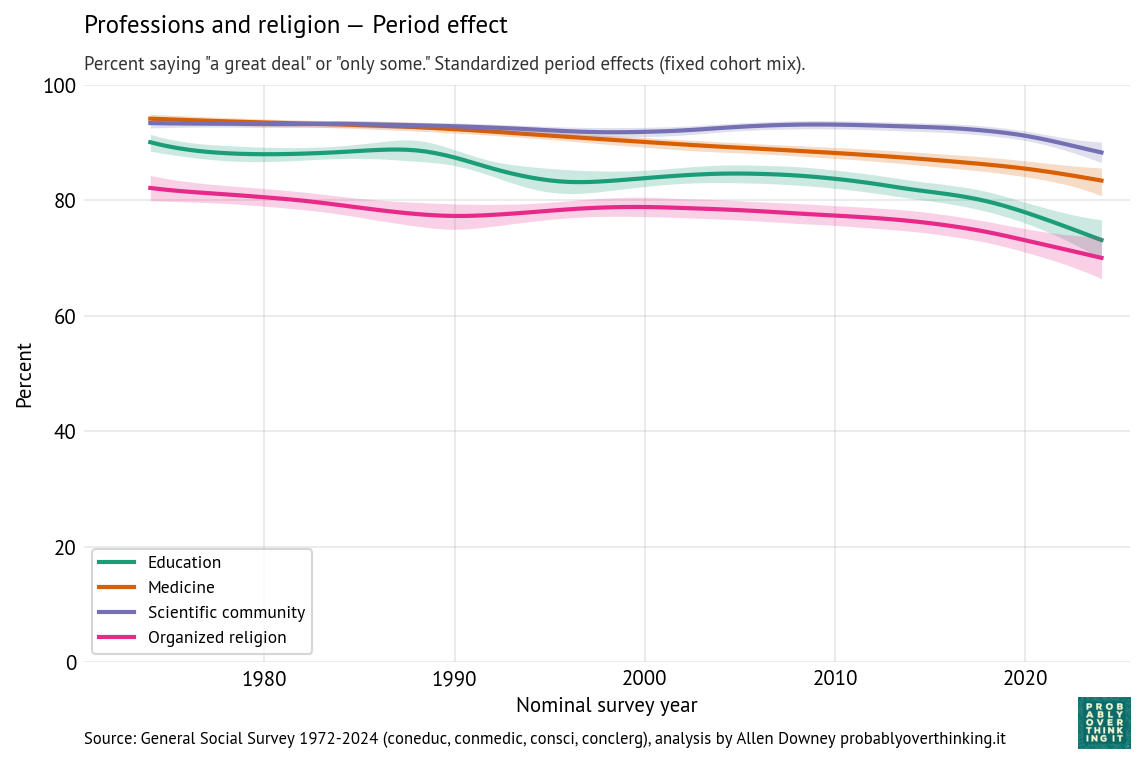
Confidence in these institutions is highest for science and medicine, lower for education and religion.
Looking at the period effects, they are all in decline. Confidence in education declined most steeply; confidence in the scientific community is relatively stable, although it declines after 2020.
Thinking about confidence in education, it might be useful to separate colleges and universities from K-12 schools.
- In higher education, the decline might be due to increasing tuition and student debt, credential inflation, and increasing uncertainty about the economic return on a college degree, especially among majors in the arts and humanities. More recently, confidence in universities has decreased steeply, especially among conservatives, due to the perception of ideological bias.
- In K-12 education, declining confidence might be related to anxiety about standardized testing, international competition, and especially around the No Child Left Behind Act in 2001, the framing of public schools as underperforming institutions requiring accountability reforms and federal intervention. Also, public schools have increasingly become focal points for political conflicts about curriculum, race, gender, religion, and parental authority.
Most of the cohort effects have increased modestly; in particular confidence in education is higher among people born after 1980, compared to previous generations observed at the same time. But for these institutions, the interaction of the period and cohort effect is similar to what we saw for Congress — it’s not that recent generations have more confidence, it’s just that when they are surveyed as young adults, they come in at entry points above the declining trend of previous generations.
Confidence in organized religion is the exception — the period and cohort effects both trend downward, so the decline is additive. A likely contributor to the period effect is growing public awareness of sexual abuse and institutional coverups in the Catholic Church, which received national attention beginning in the 1980s, escalated after the Boston Globe investigations published in 2002, and continues to the present with additional revelations in the United States and other countries. But the decline is not limited to the Catholic Church, and it began before these scandals were widely known.
The cohort effect likely reflects broader secularization trends, including declining religious affiliation, lower church attendance, and weakening institutional authority among younger generations.
Media
Finally, the following figures show estimated cohort and period effects for confidence in television and the press.
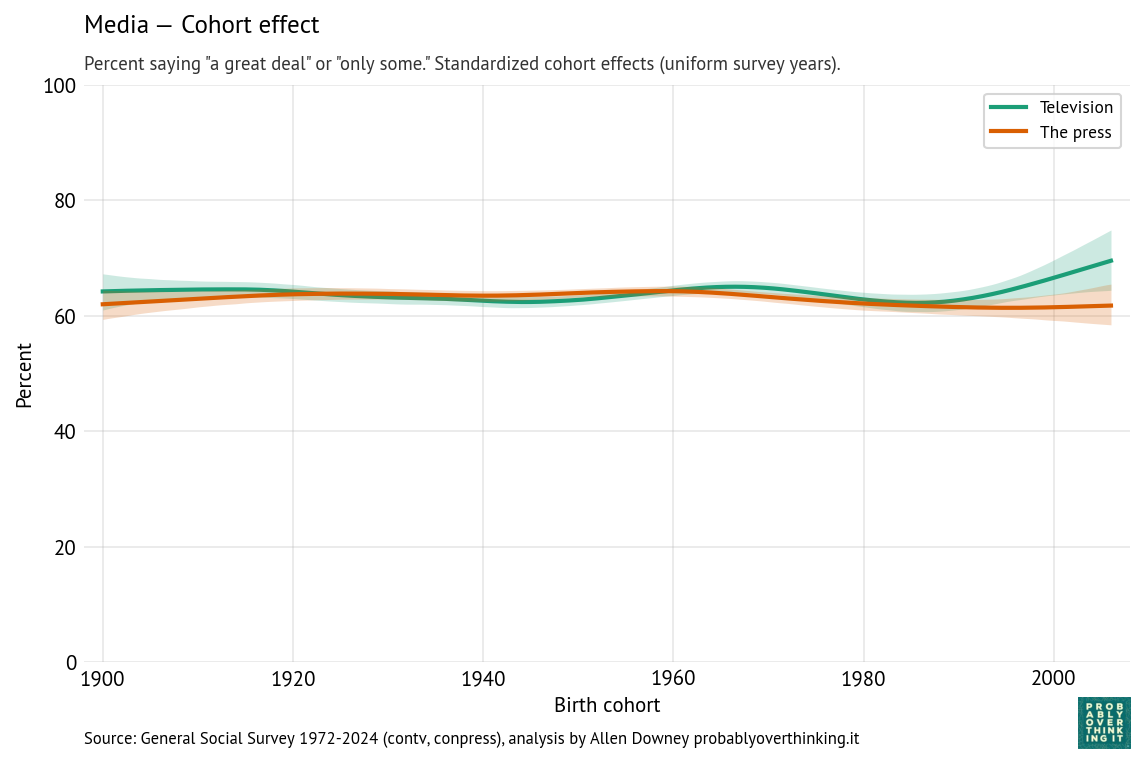
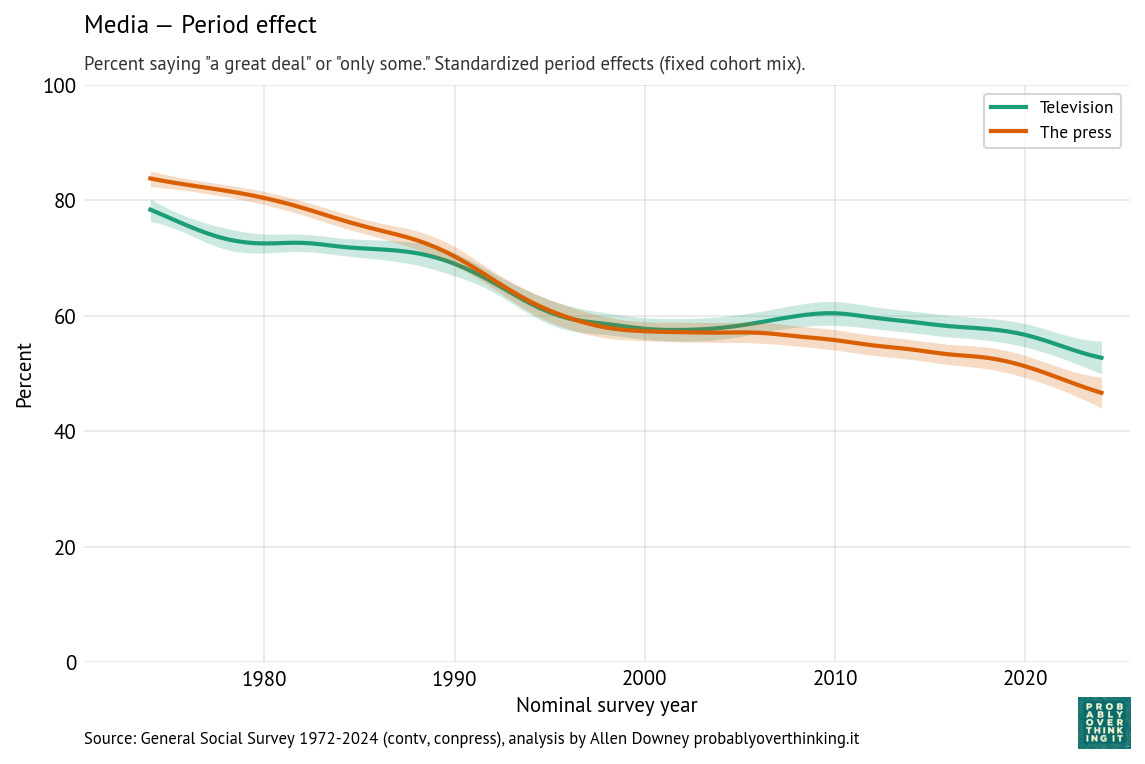
There is almost no cohort effect, although the most recent cohorts might have a little more confidence in television.
The headline here is the period effect, which is consistently downward, and steeper for the press than television. The steepest part of the decline for both media started around 1990, shortly after the 1987 abolition of the fairness doctrine, which required broadcast coverage of controversial topics to be “fair in the sense that it provides an opportunity for the presentation of contrasting points of view,” as described in the 1949 FCC report that established the doctrine.
The end of the fairness doctrine coincided with the rise of talk radio programs with explicit political viewpoints, including The Rush Limbaugh Show, which was nationally syndicated in 1988.
Cable television news followed, including Fox News Channel in 1996, with an explicit conservative orientation, and MSNBC, which developed a more liberal identity in the 2000s.
During this period, more generally, media audiences became more fragmented. Prior to 1980, most Americans were exposed to a small number of shared news sources, notably the three major television networks. Talk radio and cable television offered more options and less common experience.
And then the internet happened, starting in the 1990s with online news and political blogs, including the Drudge Report which started as a weekly email newsletter in 1995, and rose to national prominence when it broke the Clinton-Lewinsky scandal in 1998.
Social media followed. YouTube was founded in 2005; Facebook and Twitter launched in 2006. While these platforms have become important sources of news for many Americans, engagement-driven algorithms often promote emotionally provocative and polarizing content over careful reporting. The rise of the internet contributed to the decline of local newspapers, and eventually national newspapers as well.
Ownership of television stations became increasingly consolidated following the 1996 Telecommunications Act, allowing a small number of national media companies to control larger shares of local news programming. The effect of this consolidation is explained in this Vox article and memorably demonstrated in this Deadspin compilation showing dozens of TV news anchors reading nearly identical scripts provided by the Sinclair Broadcast Group, which requires the channels it owns to air segments called “must-runs” — many of them presenting conservative talking points.
Finally, since the beginning of his presidential campaign in 2015, Donald Trump has repeatedly denigrated television and print media, frequently describing unfavorable coverage as “fake news” and labeling journalists “enemies of the people.” These attacks likely contribute to declining confidence in the press, especially among Republicans.
Negativity Bias
In the previous examples, you might notice that I offer explanations for the downturns, but no explanation for the upturns. That’s because bad things, like scandals and economic crises, often happen quickly and they get a lot of coverage; good things often happen slowly and continue without comment.
For many institutions, no news is good news. When they do their jobs, they don’t get much attention, and public confidence drifts higher, even without specific positive events or coverage.
So I want to end this article by highlighting some of the positive results we see in this data:
- Confidence in education, science, and medicine is high and although the period effects are negative, the cohort effects are positive, which bodes well for the future.
- Confidence in financial institutions and organized labor is high.
- Confidence in government is lower and declining, but as each generation of young adults starts out more optimistic than their elders, there is hope for a turnaround.
But the recent steep decline of confidence in the Supreme Court is a concern, as is the loss of confidence in the media. It’s hard to find a positive take on those trends.