I wrote about this topic in Elements of Data ScienceNotebook 9, where I suggest that using Pearson’s coefficient of correlation, usually denoted r, to summarize the relationship between two variables is problematic because:
Correlation only quantifies the linear relationship between variables; if the relationship is non-linear, correlation tends to underestimate it.
Correlation does not quantify the “strength” of the relationship in terms of slope, which is often more important in practice.
For an explanation of either of those points, see the discussion in Notebook 9. But that tweet and the responses got me thinking, and now I think there are even more reasons correlation is not a great statistic:
It is hard to interpret as a measure of predictive power.
It makes the relationship between variables sound more impressive than it is.
As an example, I’ll quantify the relationship between SAT scores and IQ tests. I know this is a contentious topic; people have strong feelings about the SAT, IQ, and the consequences of using standardized tests for college admissions.
I chose this example because it is a topic people care about, and I think the analysis I present can contribute to the discussion.
But a similar analysis applies in any domain where we use a correlation to quantify the strength of a relationship between two variables.
That’s just one study, and if you read the paper, you might have questions about the methodology. But for now I will take this estimate at face value. If you find another source that reports a different correlation, feel free to plug in another value and run my analysis again.
In the notebook, I generate fake datasets with the same mean and standard deviation as the SAT and the IQ, and with a correlation of 0.82.
Then I use them to compute
The coefficient of determination, R²,
The mean absolute error (MAE),
Root mean squared error (RMSE), and
Mean absolute percentage error (MAPE).
In the SAT-IQ example, the correlation is 0.82, which is a strong correlation, but I think it sounds stronger than it is.
R² is 0.66, which means we can reduce variance by 66%. But that also makes the relationship sound stronger than it is.
Using SAT scores to predict IQ, we can reduce MAE by 44%, we can reduce RMSE by 42%, and we can reduce MAPE also by 42%.
Admittedly, these are substantial reductions. If you have to guess someone’s IQ (for some reason) your guesses will be more accurate if you know their SAT scores.
But any of these reductions in error is substantially more modest than the correlation might lead you to believe.
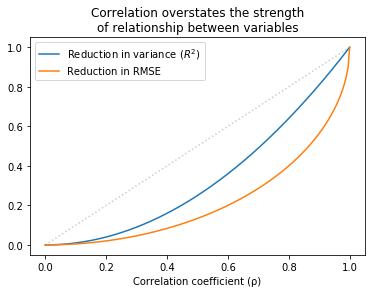
The same pattern holds over the range of possible correlations. The following figure shows R² and the fractional improvement in RMSE as a function of correlation:
For all values except 0 and 1, R² is less than correlation and the reduction in RMSE is even less than that.
Summary
Correlation is a problematic statistic because it sounds more impressive than it is.
Coefficient of determination, R², is a little better because it has a more natural interpretation: percentage reduction in variance. But reducing variance it usually not what we care about.
A better option is to choose a measure of error that is meaningful in context, possibly MAE, RMSE, or MAPE.
Which one of these is most meaningful depends on the cost function. Does the cost of being wrong depend on the absolute error, squared error, or percentage error? If so, that should guide your choice.
One advantage of RMSE is that we don’t need the data to compute it; we only need the variance of the dependent variable and either r or R². So if you read a paper that reports r, you can compute the corresponding reduction in RMSE.
But any measure of predictive error is more meaningful than reporting correlation or R².
Elvis Presley had a twin brother (who died at birth). What is the probability that Elvis was an identical twin?
I will answer this question in three steps:
First, we need some background information about the relative frequencies of identical and fraternal twins.
Then we will use Bayes’s Theorem to take into account one piece of data, which is that Elvis’s twin was male.
Finally, living up to the name of this blog, I will overthink the problem by taking into account a second piece of data, which is that Elvis’s twin died at birth.
With a few reasonable assumptions, we can use this data to compute the probability that Elvis was an identical twin, given that his twin brother died at birth.
In the last 30 years, college students have become much less religious. The fraction who say they have no religious affiliation tripled, from about 10% to 30%. And the fraction who say they have attended a religious service in the last year fell from more than 85% to less than 70%.
I’ve been following this trend for a while, using data from the CIRP Freshman Survey, which has surveyed a large sample of entering college students since 1966.
The most recently published data is from “97,753 first-time, full-time students who entered 147 U.S. colleges and universities of varying selectivity and type in the fall of 2018.”
Of course, college students are not a representative sample of the U.S. population. And as rates of college attendance have increased, they represent a different slice of the population over time. Nevertheless, surveying young adults over a long interval provides an early view of trends in the general population.
Religious preference
Among other questions, the Freshman Survey asks students to select their “current religious preference” from a list of seventeen common religions, “Other religion,” “Atheist”, “Agnostic”, or “None.”
The options “Atheist” and “Agnostic” were added in 2015. For consistency over time, I compare the “Nones” from previous years with the sum of “None”, “Atheist” and “Agnostic” since 2015.
The following figure shows the fraction of Nones from 1969, when the question was added, to 2018, the most recent data available.
The survey also asks students how often they “attended a religious service” in the last year. The choices are “Frequently,” “Occasionally,” and “Not at all.” Respondents are instructed to select “Occasionally” if they attended one or more times, so a wedding or a funeral would do it.
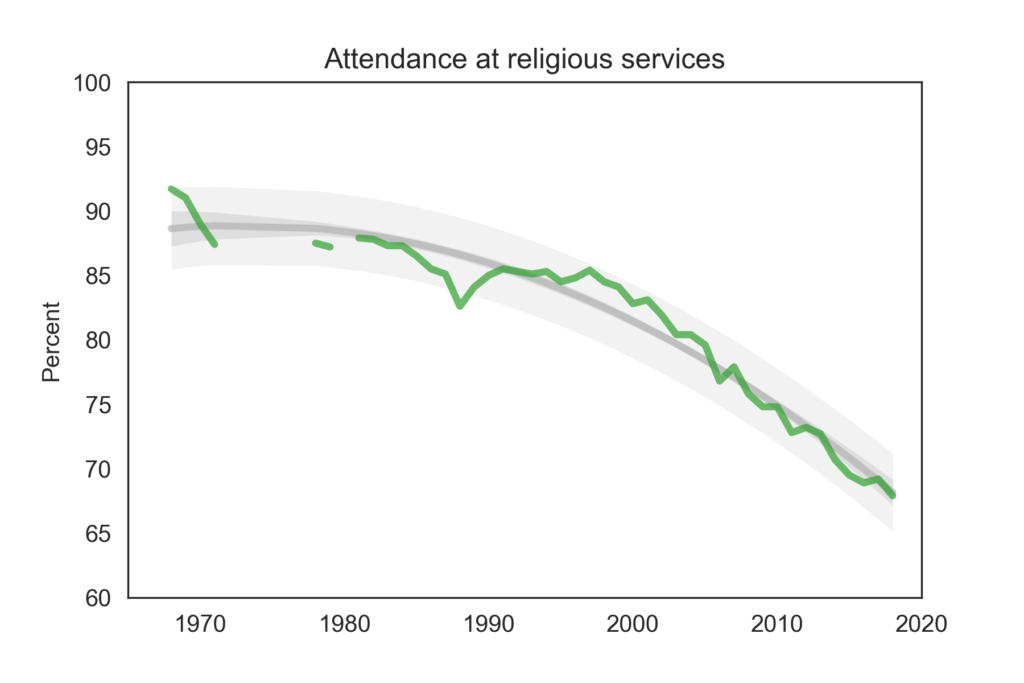
The following figure shows the fraction of students who reported any religious attendance in the last year, starting in 1968. I discarded a data point from 1966 that seems unlikely to be correct (66%).
Percentage of students who reported attending a religious service in the previous year.
About 68% of incoming college students said they attended a religious service in the last year, an all-time low in the history of the survey, and down more 20 percentage points from the peak.
In contrast with the fraction of Nones, this curve is on trend, with no sign of slowing down.
In previous years I have also reported on the gender gap in religious affiliation and attendance, but the data are not available yet. I will update when they are.
Data Source
The American Freshman: National Norms Fall 2018 Stolzenberg, Eagan, Romo, Tamargo, Aragon, Luedke, and Kang, Higher Education Research Institute, UCLA, December 2019
In the third article, I found that generational differences on most questions related to abortion are small and probably not practically or statistically significant.
GSS respondents were asked several questions related to their attitudes about sex:
There’s been a lot of discussion about the way morals and attitudes about sex are changing in this country.
If a man and woman have sex relations before marriage, do you think it is always wrong, almost always wrong, wrong only sometimes, or not wrong at all?
What if they are in their early teens, say 14 to 16 years old? In that case, do you think sex relations before marriage are always wrong, almost always wrong, wrong only sometimes, or not wrong at all?
What about sexual relations between two adults of the same sex–do you think it is always wrong, almost always wrong, wrong only sometimes, or not wrong at all?
What is your opinion about a married person having sexual relations with someone other than the marriage partner–is it always wrong, almost always wrong, wrong only sometimes, or not wrong at all?
For each of these questions, I count the fraction of respondents who reply “always wrong”.
And I looked at responses to one other sex-related question:
Would you be for or against sex education in the public schools?
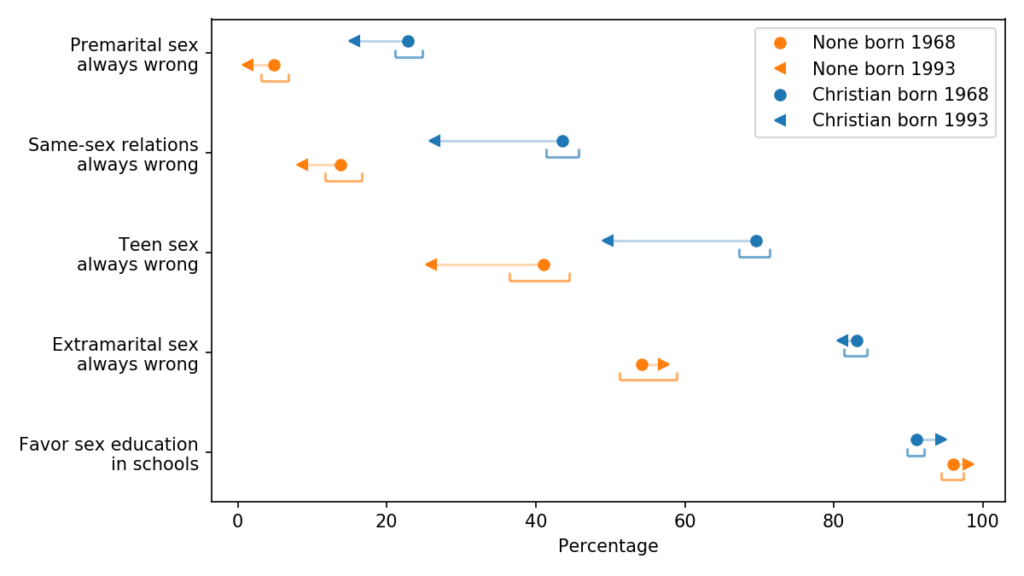
Here are the results:
Generational changes in attitudes related to sex.
The blue markers are for people whose religious preference is Catholic, Protestant, or Christian; the orange markers are for people with no religious affiliation.
For each group, the circles show estimated percentages for people born in 1968; the arrowheads show percentages for people born in 1993.
For both groups, the estimates are for 2018, when the younger group was 25 and the older group was 50. The brackets show 90% confidence intervals.
In almost every scenario, young Christians are less likely than the previous generation to say that sex is “always wrong”, and in the cases of homosexual and teen sex, the changes are substantial.
Opposition to premarital sex was already low and did not change as much. Support for sex education was already high and is now an overwhelming majority.
The exception is extramarital sex, where there is practically no generational change: more than 80% of both generations think it is always wrong.
Compared to their Christian peers, the non-religious are more sex-positive by 15-30 percentage points. And their generational changes go in the same direction, with young Nones less likely to think sex in these scenarios is wrong.
But again, extramarital sex is the exception; among the Nones, the small generational change is within the margin of error.
This exception suggests that both groups distinguish between actions that harm people and transgressions of divine law.
Then, for a while, the story was that people were leaving organized religion, but they were still religious or at least spiritual; that is, they were “believing without belonging”.
In this series of articles, I have looked at changes among the ones who are left behind; that is, the decreasing fraction who identify as Christian. On many dimensions, the pattern is the same: young Christians are more secular than the previous generation.
Responses that follow this pattern include:
Almost all religious beliefs and activities, except belief in the afterlife.
Opposition to sex and sex education, except extramarital sex.
Matters of public policy including the legalization of marijuana, pornography, and euthanasia; support for affirmative action; and opposition to the death penalty and school prayer.
Many questions related to public spending follow the same pattern, with younger Christians generally moving toward positions held by their secular peers; the only substantial exception is mass transportation, which has less support among young people in both groups [although this result is so surprising to me that I need more evidence to be confident it is correct].
The most notable exceptions are opposition to gun control and abortion, which show almost no generational changes. Maybe not coincidentally, these exceptions are probably the most politicized topics among the questions I explored.
In summary, we can describe secularization in the U.S. as the sum of two trends, changes in affiliation and changes in belief. Both trends are moving fast, and they are moving in the same direction, away from religion.
Generational changes in public spending priorities
In the third article, I found that generational differences on most questions related to abortion are small and probably not practically or statistically significant.
GSS respondents were asked, “We are faced with many problems in this country, none of which can be solved easily or inexpensively. I’m going to name some of these problems, and for each one I’d like you to tell me whether you think we’re spending too much money on it, too little money, or about the right amount.”
Since they asked about 18 areas of public spending, I’ve put them in three categories:
Areas where young people are more inclined to increase spending,
Areas where young people are less inclined to increase spending, and
Areas where generational differences are inconsistent or small.
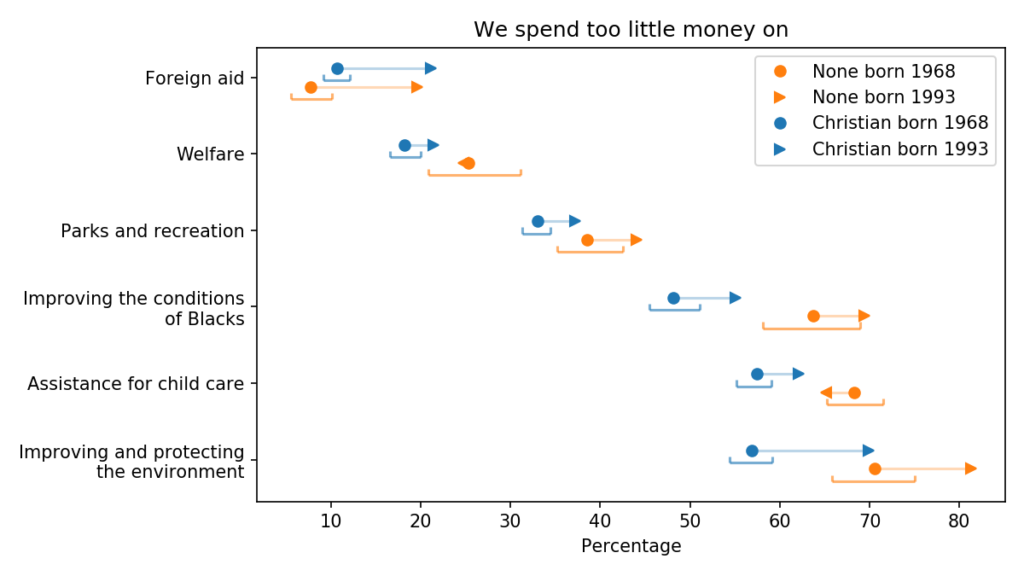
The following figure shows the first group, areas where young people are more likely to say we spend too little:
Generational changes in views on public spending
The blue markers are for people whose religious preference is Catholic, Protestant, or Christian; the orange markers are for people with no religious affiliation.
For each group, the circles show estimated percentages for people born in 1968; the arrowheads show percentages for people born in 1993.
For both groups, the estimates are for 2018, when the younger group was 25 and the older group was 50. The brackets show 90% confidence intervals.
The way these questions were posed, I suspect that most respondents can’t answer them literally. Few people know how much we spend in each area, what we spend it on, or what effect it would have if we spent more.
So their answers reflect some combination of how important they consider each issue, how much they think we are spending, and how effective they imagine more government spending would be.
With those caveats, we can draw a few conclusions:
On these issues, the priorities of Christians and Nones are generally aligned. The biggest difference between the groups is on spending to protect the environment, but a majority of both groups think we are spending too little.
The biggest generational changes are in foreign aid and protecting the environment; on both issues, young people are substantially more inclined to increase spending. But with respect to foreign aid, it is still a small minority.
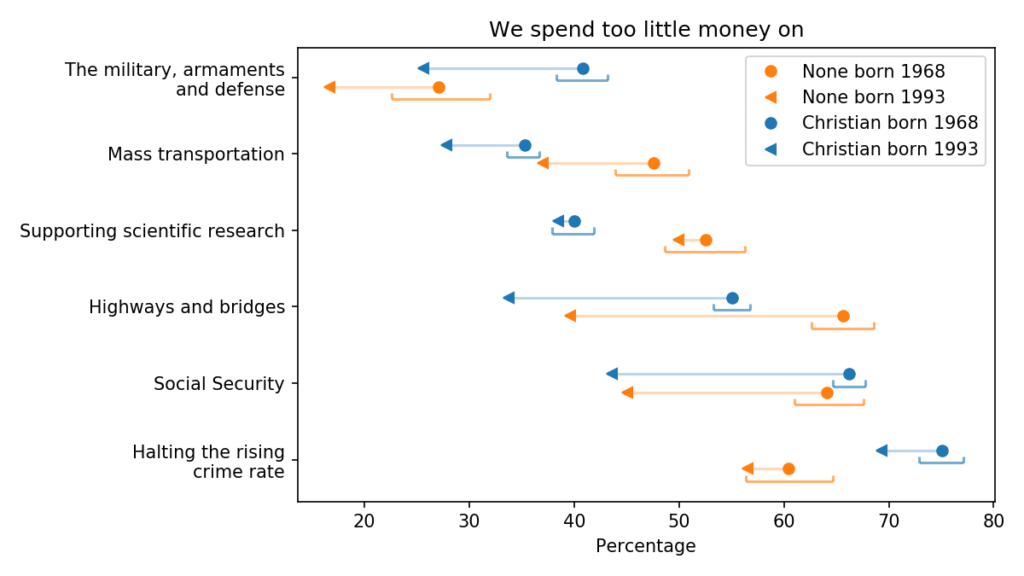
The following figure shows areas of public spending where the generational change is generally negative:
Generational changes in views on public spending
Compared to their parents’ generation, young people are substantially less likely to increase spending on the military, transportation infrastructure and Social Security. To me, the direction of those changes is not surprising, but the magnitude is.
The other change I find surprising is in support for mass transportation, which decreased in both groups. I double-checked the data and this result seems to be correct, but it might warrant more investigation.
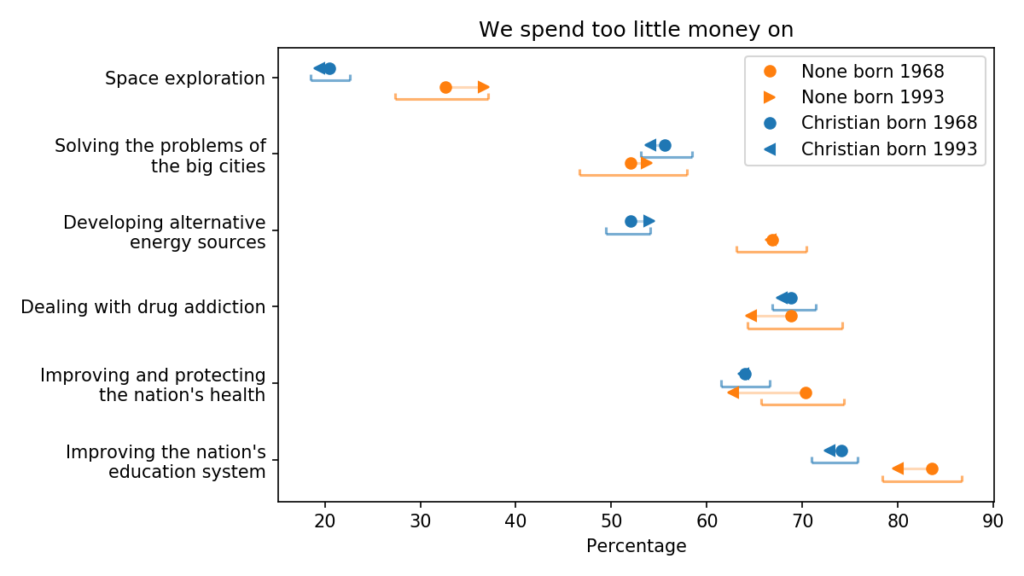
Finally, the following figure shows areas of public spending where generational changes are small and unlikely to be practically or statistically significant.
Generational changes in views on public spending
On these issues, the spending priorities of Christians and Nones are generally aligned, although Nones are more inclined to increase spending on space exploration, alternative energy, and education.
In the next article, I’ll look at generational changes related to confidence in various government and private institutions.
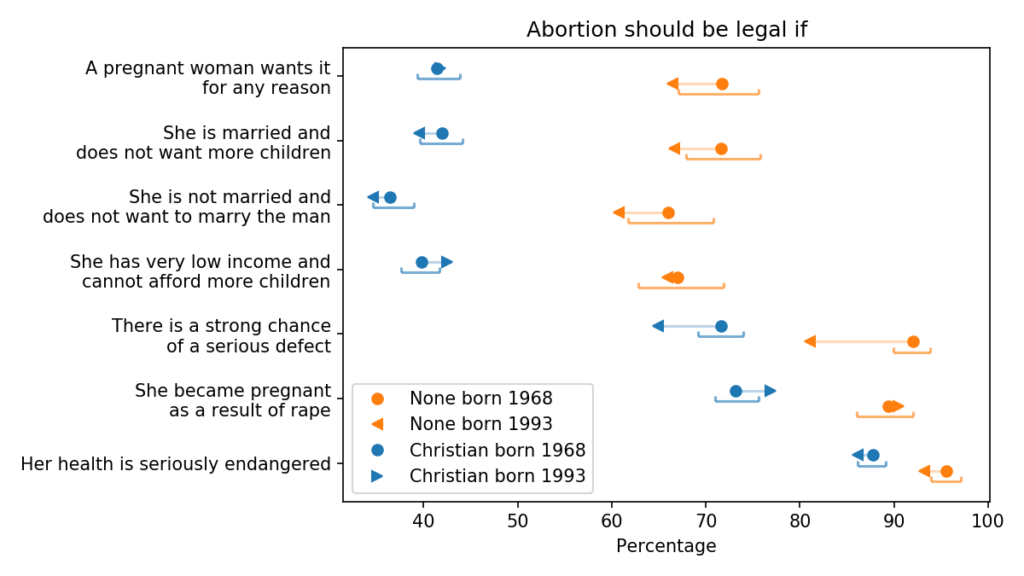
A large majority of Americans support legal abortion, at least in some circumstances
GSS respondents were asked, “Please tell me whether or not you think it should be possible for a pregnant woman to obtain a legal abortion” under different circumstances.
The following figure shows the results.
Generational changes in beliefs about legal abortion
The blue markers are for people whose religious preference is Catholic, Protestant, or Christian; the orange markers are for people with no religious affiliation.
For each group, the circles show estimated percentages for people born in 1968; the arrowheads show percentages for people born in 1993.
For both groups, the estimates are for 2018, when the younger group was 25 and the older group was 50. The brackets show 90% confidence intervals.
Before we look for generational changes, we should notice the starting point: a large majority of Americans support legal abortion, at least in some circumstances.
In cases of severe birth defects and pregnancy due to rape, the majority is about 70% of Christians and 90% of the nonreligious.
In cases of serious danger to the woman’s health, it’s almost 90% of Christians and nearly all of the nonreligious.
Under other circumstances, opinions are more divided, with support near 40% among Christians and 70% among the Nones.
Looking now at the generational changes, I see only one that is likely to be practically and statistically significant: younger people in both groups are less likely than the previous generation to support legal abortion if there is a chance of serious birth defect.
Even so, there is majority support in both groups, more than 60% among Christians and 80% among Nones at age 25.
In summary:
Beliefs about abortion depend substantially on the circumstances;
In many circumstances, a large majority of Christians and the non-religious support legal abortion;
Even where there is disagreement between the groups, there is substantial diversity of opinion within both groups;
Generational changes in these opinions are generally small and within the statistical margin of error.
Generational changes in religious belief and public policy
Here are results for five propositions with relatively high support:
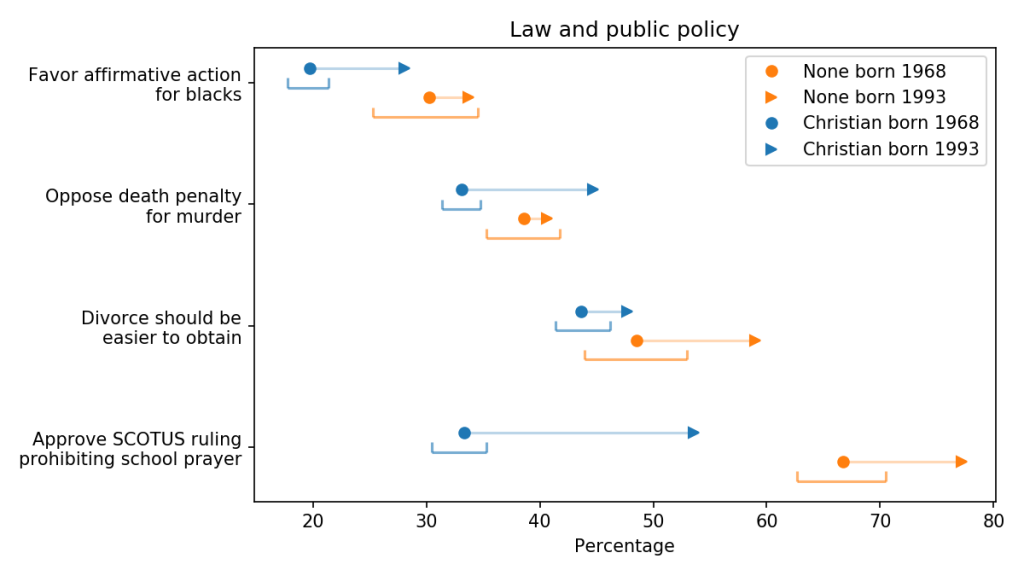
Generational changes in support for issues related to law and public policy
The blue markers are for people whose religious preference is Catholic, Protestant, or Christian; the orange markers are for people with no religious affiliation.
For each group, the circles show estimated percentages for people born in 1968; the arrowheads show percentages for people born in 1993.
For both groups, the estimates are for 2018, when the younger group was 25 and the older group was 50. The brackets show 90% confidence intervals.
The first row shows the percentage of respondents who answered “Yes” to the question “Do you think the use of marijuana should be made legal or not?”
Young Christians are substantially more likely to support legalization than their parents’ generation. Among the Nones, support might also be increasing, but the change is within the statistical margin of error.
Young Christians also support legal pornography. When asked, “Which of these statements comes closest to your feelings about pornography laws?”, more than 75% of them indicated that it should be legal, or legal for adults, rather than illegal. That’s more than 10 percentage points higher than in the previous generation.
Support for legal pornography has also increase among the unaffiliated, from 85% to almost 90%.
Young Christians are more likely to support legal euthanasia; when asked “When a person has a disease that cannot be cured, do you think Doctors should be allowed by law to end the patient’s life by some painless means if the patient and his family request it?”, more than 75% say “Yes”.
On these three questions, Christians are moving toward the position of their secular peers. On the other two questions, there are no clear patterns:
Support for fair housing policy is high in both groups and might be increasing.
Here are results for four propositions with somewhat lower support:
Generational changes in support for issues related to law and public policy
These results shows that younger Christians are more likely than the previous generation to:
Support affirmative action,
Oppose legal obstactles to divorce,
Oppose the death penalty, and
Approve the prohibition of prayer in public schools.
In each case, Christians are moving toward the position held by the nonreligious, and in one case they have overtaken them: Christians are now more likely to oppose the death penalty than Nones of the current or previous generation.
Regarding school prayer, they were asked “The United States Supreme Court has ruled that no state or local government may require the reading of the Lord’s Prayer or Bible verses in public schools. What are your views on this–do you approve or disapprove of the court ruling?” More than 50% of young Christians answered that they approve, 20 percentage points higher than the previous generation.
Summary
These results suggest that people who identify as Christians are more politically progressive than previous generations. On most issues of law and public policy, a 25-year old Christian is more aligned with a 50-year old None than a 50-year old Christian.
In the next article, I’ll explore generational changes in other opinions and attitudes.
Related reading: In this article about an evangelical Christian activist, The Washington Post Magazine asks “Can Shane Claiborne’s progressive version of evangelical Christianity catch on with a new generation?” The article emphasizes Claiborne’s progressive views on reducing gun violence. My analysis of data from the GSS suggests that young Christians are more progressive than previous generations on many issues, but gun control is not one of them.
Young Christians are less religious than the previous generation
This is the first in a series of articles where I use data from the General Social Survey (GSS) to explore
Differences in beliefs and attitudes between Christians and people with no religious affiliation (“Nones”),
Generational differences between younger and older Christians, and
Generational differences between younger and older Nones.
On several dimensions of religious belief, young Christians are less religious than their parents’ generation. I’ll explain the methodology below, but here are the results:
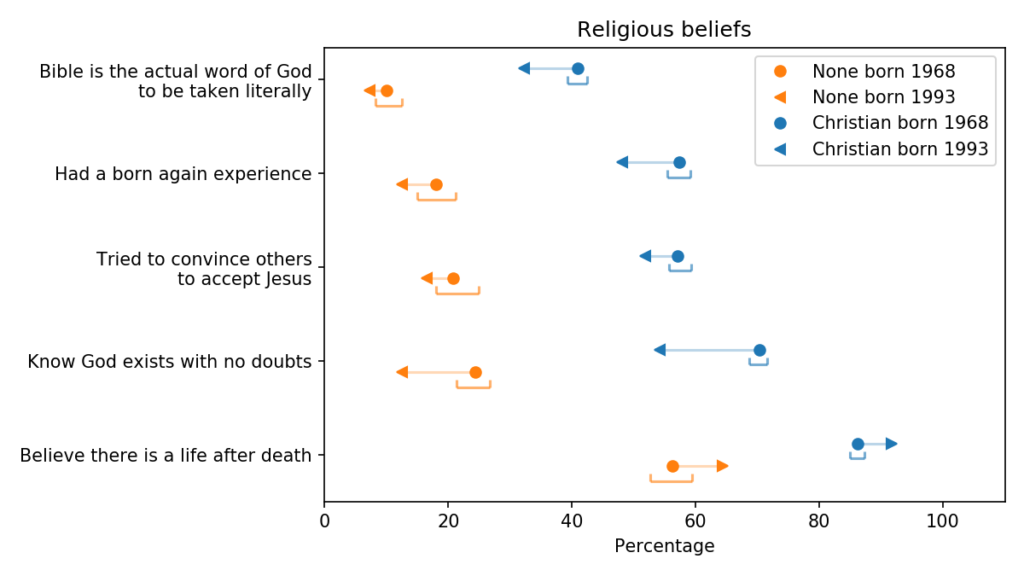
Generational changes in religious belief, comparing people born in 1968 and 1993
The blue markers are for Christians (people whose religious preference is Catholic, Protestant, or Christian); the orange markers are for people with no religious affiliation.
For each group, the circles show estimated percentages for people born in 1968; the arrowheads show percentages for people born in 1993.
For both groups, the estimates are for 2018, when the younger group was 25 and the older group was 50. The brackets show 90% confidence intervals for the estimates, computed by random resampling.
The top row shows the fraction of respondents who interpret the Christian bible literally; more specifically, when asked “Which of these statements comes closest to describing your feelings about the Bible?”, they chose the first of these options:
“The Bible is the actual word of God and is to be taken literally, word for word”
“The Bible is the inspired word of God but not everything in it should be taken literally, word for word.
“The Bible is an ancient book of fables, legends, history, and moral precepts recorded by men.”
Not surprisingly, people who consider themselves Christian are more likely to interpret the Bible literally, compared to people with no religious affiliation.
But younger Christians are less likely to be literalists than the previous generation. Most of the other variables show the same pattern; younger Christians are less likely to answer yes to these questions:
“Would you say you have been ‘born again’ or have had a ‘born again’ experience — that is, a turning point in your life when you committed yourself to Christ?”
“Have you ever tried to encourage someone to believe in Jesus Christ or to accept Jesus Christ as his or her savior?”
And they are less likely to report that they know God really exists; specifically, they were asked “Which statement comes closest to expressing what you believe about God?” and given these options:
I don’t believe in God
I don’t know whether there is a God and I don’t believe there is any way to find out.
I don’t believe in a personal God, but I do believe in a Higher Power of some kind.
I find myself believing in God some of the time, but not at others.
While I have doubts, I feel that I do believe in God.
I know God really exists and I have no doubts about it.
Younger Christians are less likely to say they know God exists and have no doubts.
Despite all that, younger Christians are more likely to believe in an afterlife. When asked “Do you believe there is a life after death?”, more than 90% say yes.
Among the unaffiliated, the trends are the same. Younger Nones are less likely to believe that the Bible is the literal word of God, less likely to have proselytized or been born again, and less likely to be sure God exists. But they are a little more likely to believe in an afterlife.
More questions, less religion
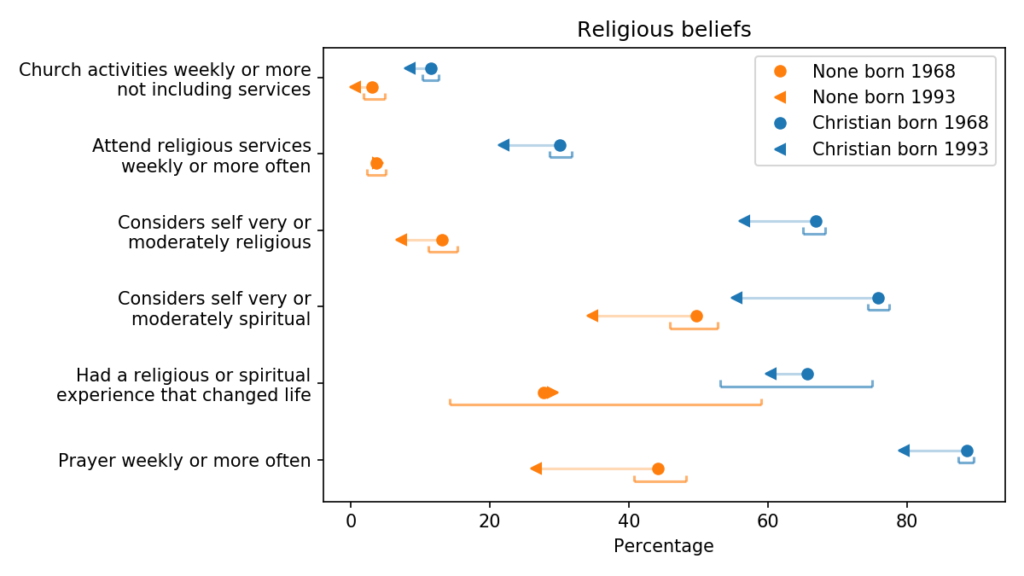
UPDATE: Since the first version of this article, I’ve had a chance to look at six other questions related to religious belief and activity. Here are the results:
Generational changes in religious belief, comparing people born in 1968 and 1993
Qualitatively, these results are similar to what we saw before: controlling for period effects, younger Christians are more secular than the previous generation, in both beliefs and actions.
They are substantially less likely to consider themselves “religious” or “spiritual”, and less likely to attend religious services or pray weekly. And they are slightly less likely to participate in church activities other than services.
They might also be less likely to say they have had a life-changing religious experience, but that change falls within the margin of error.
In later articles, I’ll look at trends in other beliefs and attitudes, especially related to public policy. But first I should explain how I generated these estimates.
Methodology
My goal is to estimate generational changes, that is, cohort effects as distinguished from age and period effects. In general, it is not possible to distinguish between age, period, and cohort effects without making some assumptions. So this analysis is based on the assumption that age effects in this dataset are negligible compared to period and cohort effects.
Data from the General Social Survey goes back to 1972; it includes data from almost 65,000 respondents.
To measure current differences between people born in 1968 and 1993, I could select only respondents born in those years and interviewed in 2018. But there are not very many of them.
Alternatively, I could use data from all respondents, going back to 1972, fit a model, and use the model to estimate generational differences. That might work, but it would probably give too much weight to older, less relevant data.
As a compromise, I use data from 1998 to 2018, from respondents born in 1940 or later. This subset includes about 25,000 respondents. But not every respondent was asked every question, so the number of valid responses for most questions is smaller.
For most questions, I discard a small number of respondents who gave no response or said they did not know.
To model the responses, I use logistic regression with year of birth (cohort) and year of interview as independent variables. For questions with more than two responses, I choose one of the responses to study, usually the most popular; in a few cases, I grouped a subset of responses (for example “agree” and “strongly agree”).
I use a quadratic model for the period effect and a cubic model of the cohort effect, using visual tests to check whether the models do an acceptable job of describing the trends in the data.
I fit separate models for Christians and Nones, to allow for the possibility that trends might look different in the two groups (as it turns out they often do).
Then I use the models to generate predictions for four groups: Christians born in 1968 and 1993, and Nones born in the same years. These are “predictions” in the statistical sense of the word, but they are deliberately not extrapolations into cohorts or periods that are not in the dataset; it might be more correct to call them “interpolations”.
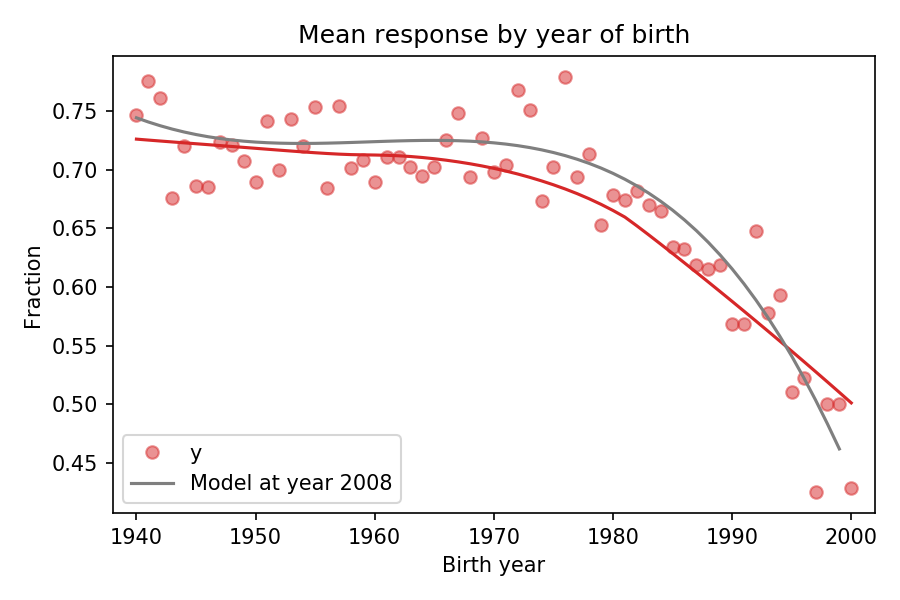
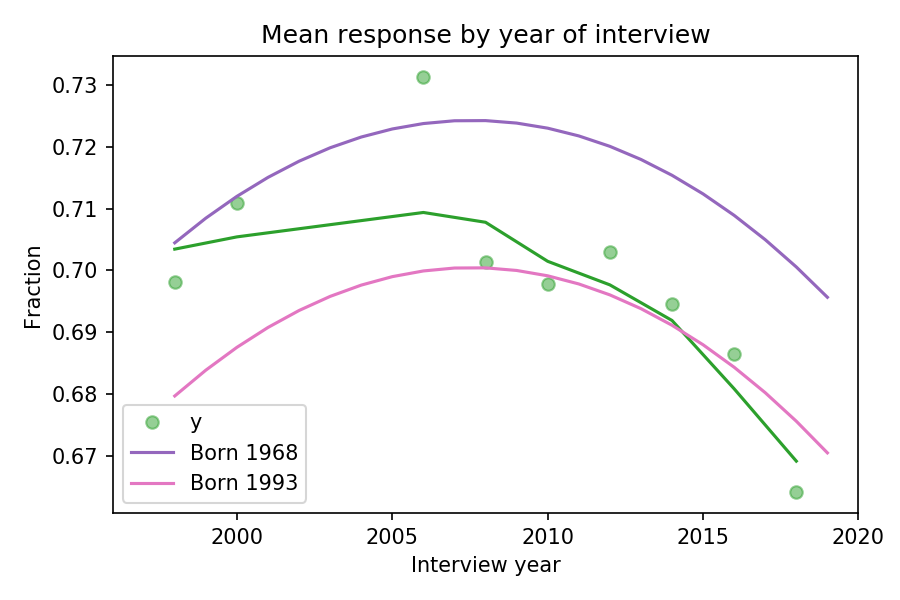
To show how this method works, let’s consider the fraction of Christians who answer that they know God exists, with no doubts. The following figure shows this fraction as a function of birth year (cohort):
Fraction of Christians who says they know God exists, plotted over year of birth
The red dots show the fraction of respondents in each birth cohort. The red line shows a smooth curve through the data, computed by local regression (LOWESS). The gray line shows the predictions of the model for year 2008.
This figure shows that the logistic regression model of birth year does an acceptable job of describing the trends in the data, while also controlling for year of interview.
To see whether the model also describes trends over time, we can plot the fraction of respondents in each year of interview:
Fraction of Christians who says they know God exists, plotted over year of inteview
The green dots show the fraction of respondents during each year of interview and the green line shows a local regression through the data. The purple line shows the model’s predictions for someone born in 1968; the pink line shows predictions for someone born in 1993.
The gap between the purple and pink curves is the estimated generational change; in this example, it’s about 3 percentage points.
In summary, the model uses data from a range of birth years and interview years to fit a model, then uses the model to estimate the difference in response between people born in different years, both interviewed in 2018.
The results are based on the assumption that the model adequately describes the period and cohort effects, and that any age effects are negligible by comparison.
You might think you have to, but you don’t and you shouldn’t.
Why you might think you have to
Science is objective and it doesn’t matter who does the experiment, so we should write in the passive voice, which emphasizes the methods and materials, not the scientists.
You are teaching at <a level of education> and you have to prepare students for the <next level of education>, where they will be required to write in the passive voice.
Why you don’t have to
Regardless of how objective we think science is, writing about it in the passive voice doesn’t make it any more objective. Science is done by humans; there is no reason to pretend otherwise.
If you are teaching students to write in the passive voice because you think they need it at the next stage in the pipeline, you don’t have to.
If they learn to write in the active voice now, they can learn to write in the passive voice later, when and if they have to. And they might not have to.
“Choose the active voice more often than you choose the passive, for the passive voice usually requires more words and often obscures the agent of action.”
“Nature journals like authors to write in the active voice (“we performed the experiment…” ) as experience has shown that readers find concepts and results to be conveyed more clearly if written directly.”
“[We] feel that accepted best practice in writing and editing favors active voice over passive.”
Top journals agree: you don’t have to teach students to write in the passive voice.
Why you shouldn’t
As a stylistic matter, excessive use of the passive voice is boring. As a practical matter, it is unclear.
For example, the following is the abstract of a paper I read recently. It describes prior work that was done by other scientists and summarizes new work done by the author. See if you can tell which is which.
The Lotka–Volterra model of predator–prey dynamics was used for approximation of the well-known empirical time series on the lynx–hare system in Canada that was collected by the Hudson Bay Company in 1845–1935. The model was assumed to demonstrate satisfactory data approximation if the sets of deviations of the model and empirical data for both time series satisfied a number of statistical criteria (for the selected significance level). The frequency distributions of deviations between the theoretical (model) trajectories and empirical datasets were tested for symmetry (with respect to the Y-axis; the Kolmogorov–Smirnov and Lehmann–Rosenblatt tests) and the presence or absence of serial correlation (the Swed–Eisenhart and “jumps up–jumps down” tests). The numerical calculations show that the set of points of the space of model parameters, when the deviations satisfy the statistical criteria, is not empty and, consequently, the model is suitable for describing empirical data.