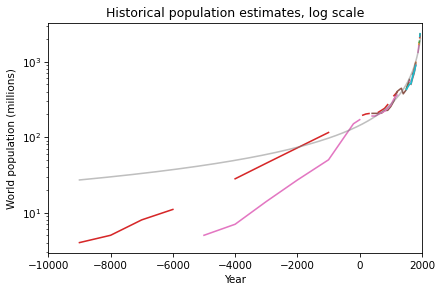
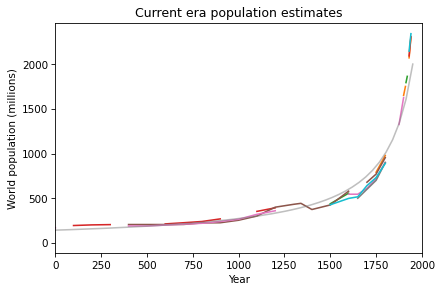
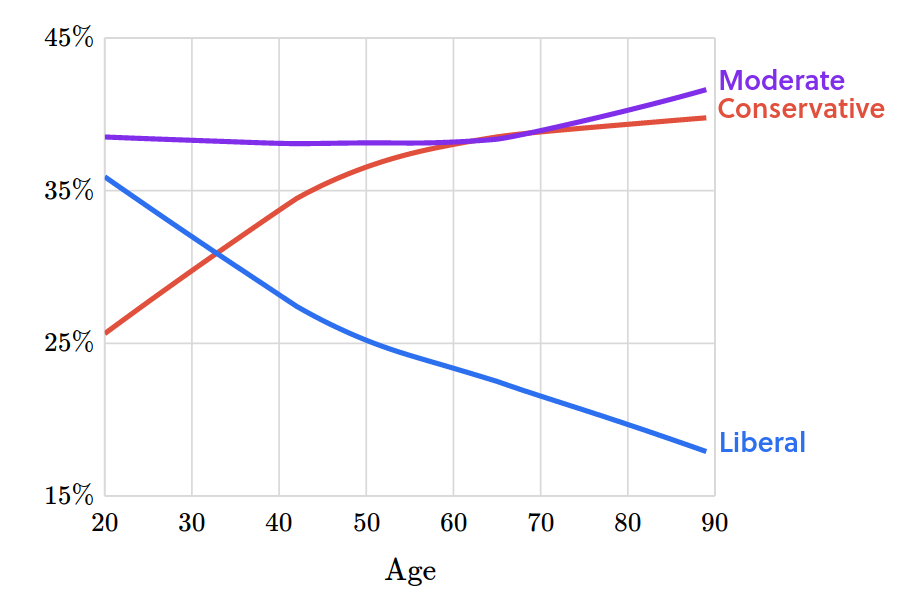
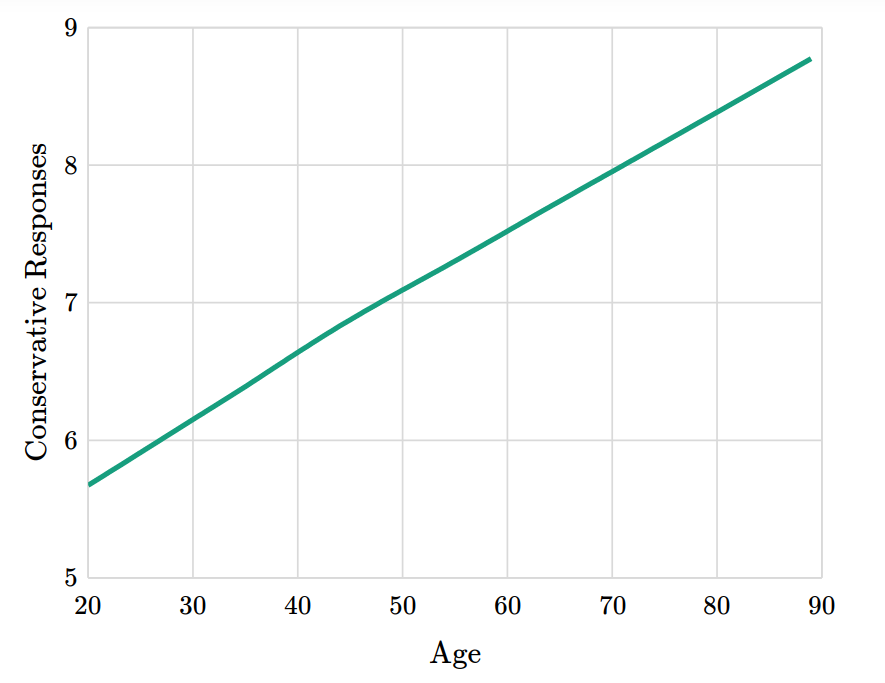
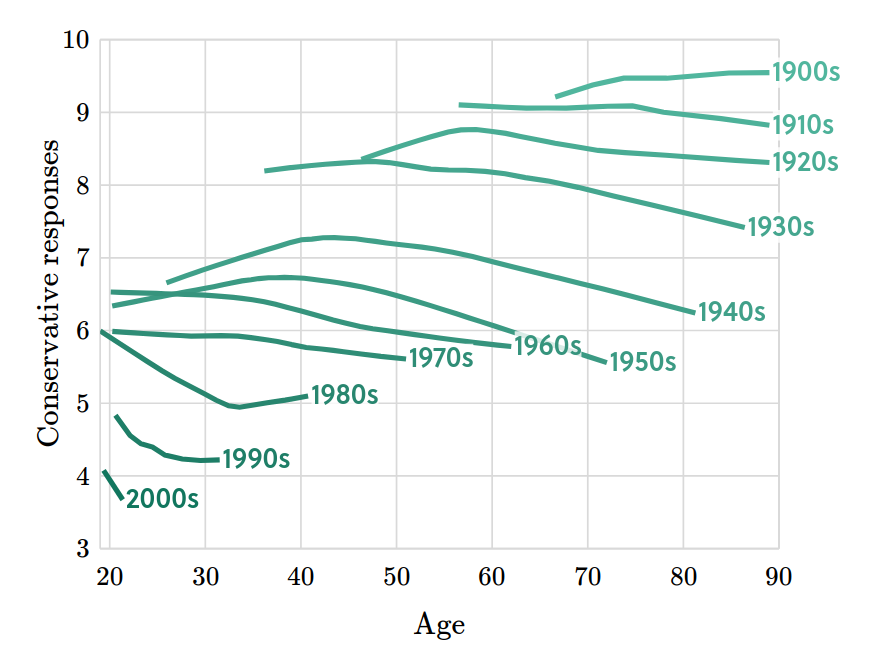
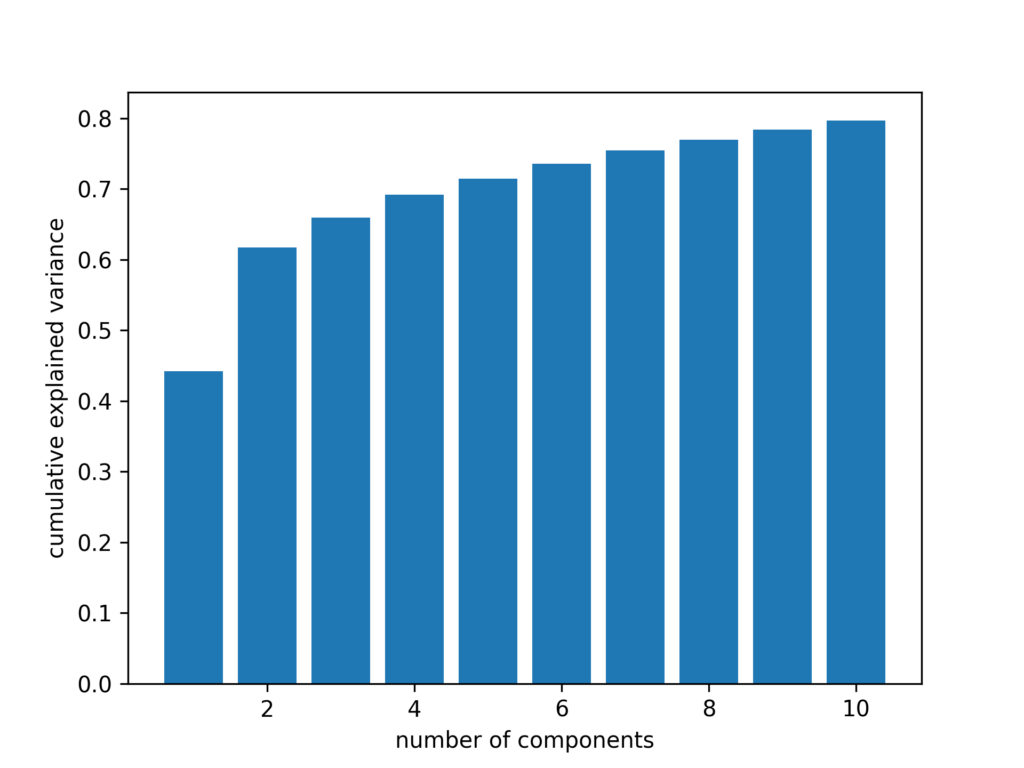
We Have a Book!
My copy of Probably Overthinking It has arrived!

If you want a copy for yourself, you can get a 30% discount if you order from the publisher and use the code UCPNEW. You can also order from Amazon or, if you want to support independent bookstores, from Bookshop.org.
The official release date is December 6, but since the book is in warehouses now, it might arrive a little early. While you wait, please enjoy this excerpt from the introduction…
Introduction
Let me start with a premise: we are better off when our decisions are guided by evidence and reason. By “evidence,” I mean data that is relevant to a question. By “reason” I mean the thought processes we use to interpret evidence and make decisions. And by “better off,” I mean we are more likely to accomplish what we set out to do—and more likely to avoid undesired outcomes.
Sometimes interpreting data is easy. For example, one of the reasons we know that smoking causes lung cancer is that when only 20% of the population smoked, 80% of people with lung cancer were smokers. If you are a doctor who treats patients with lung cancer, it does not take long to notice numbers like that.
But interpreting data is not always that easy. For example, in 1971 a researcher at the University of California, Berkeley, published a pa per about the relationship between smoking during pregnancy, the weight of babies at birth, and mortality in the first month of life. He found that babies of mothers who smoke are lighter at birth and more likely to be classified as “low birthweight.” Also, low-birthweight babies are more likely to die within a month of birth, by a factor of 22. These results were not surprising.
However, when he looked specifically at the low-birthweight babies, he found that the mortality rate for children of smokers is lower, by a factor of two. That was surprising. He also found that among low-birthweight babies, children of smokers are less likely to have birth defects, also by a factor of 2. These results make maternal smoking seem beneficial for low-birthweight babies, somehow protecting them from birth defects and mortality.
The paper was influential. In a 2014 retrospective in the Inter- national Journal of Epidemiology, one commentator suggests it was responsible for “holding up anti-smoking measures among pregnant women for perhaps a decade” in the United States. Another suggests it “postponed by several years any campaign to change mothers’ smoking habits” in the United Kingdom. But it was a mistake. In fact, maternal smoking is bad for babies, low birthweight or not. The reason for the apparent benefit is a statistical error I will explain in chapter 7.
Among epidemiologists, this example is known as the low-birthweight paradox. A related phenomenon is called the obesity paradox. Other examples in this book include Berkson’s paradox and Simpson’s paradox. As you might infer from the prevalence of “paradoxes,” using data to answer questions can be tricky. But it is not hopeless. Once you have seen a few examples, you will start to recognize them, and you will be less likely to be fooled. And I have collected a lot of examples.
So we can use data to answer questions and resolve debates. We can also use it to make better decisions, but it is not always easy. One of the challenges is that our intuition for probability is sometimes dangerously misleading. For example, in October 2021, a guest on a well-known podcast reported with alarm that “in the U.K. 70-plus percent of the people who die now from COVID are fully vaccinated.” He was correct; that number was from a report published by Public Health England, based on reliable national statistics. But his implication—that the vaccine is useless or actually harmful—is wrong.
As I’ll show in chapter 9, we can use data from the same report to compute the effectiveness of the vaccine and estimate the number of lives it saved. It turns out that the vaccine was more than 80% effective at preventing death and probably saved more than 7000 lives, in a four-week period, out of a population of 48 million. If you ever find yourself with the opportunity to save 7000 people in a month, you should take it.
The error committed by this podcast guest is known as the base rate fallacy, and it is an easy mistake to make. In this book, we will see examples from medicine, criminal justice, and other domains where decisions based on probability can be a matter of health, freedom, and life.
The Ground Rules
Not long ago, the only statistics in newspapers were in the sports section. Now, newspapers publish articles with original research, based on data collected and analyzed by journalists, presented with well-designed, effective visualization. And data visualization has come a long way. When USA Today started publishing in 1982, the infographics on their front page were a novelty. But many of them presented a single statistic, or a few percentages in the form of a pie chart.
Since then, data journalists have turned up the heat. In 2015, “The Upshot,” an online feature of the New York Times, published an interactive, three-dimensional representation of the yield curve — a notoriously difficult concept in economics. I am not sure I fully understand this figure, but I admire the effort, and I appreciate the willingness of the authors to challenge the audience. I will also challenge my audience, but I won’t assume that you have prior knowledge of statistics beyond a few basics. Everything else, I’ll explain as we go.
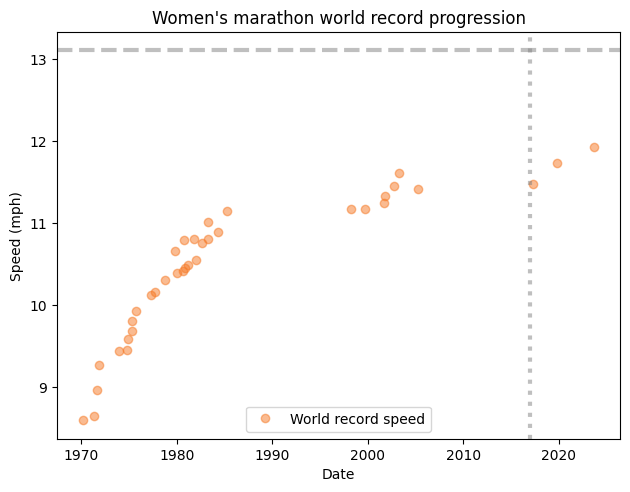
Some of the examples in this book are based on published research; others are based on my own observations and exploration of data. Rather than report results from a prior work or copy a figure, I get the data, replicate the analysis, and make the figures myself. In some cases, I was able to repeat the analysis with more recent data. These updates are enlightening. For example, the low-birthweight paradox, which was first observed in the 1970s, persisted into the 1990s, but it has disappeared in the most recent data.
All of the work for this book is based on tools and practices of reproducible science. I wrote each chapter in a Jupyter notebook, which combines the text, computer code, and results in a single document. These documents are organized in a version-control system that helps to ensure they are consistent and correct. In total, I wrote about 6000 lines of Python code using reliable, open-source libraries like NumPy, SciPy, and pandas. Of course, it is possible that there are bugs in my code, but I have tested it to minimize the chance of errors that substantially affect the results.
My Jupyter notebooks are available online so that anyone can replicate the analysis I’ve done with the push of a button.