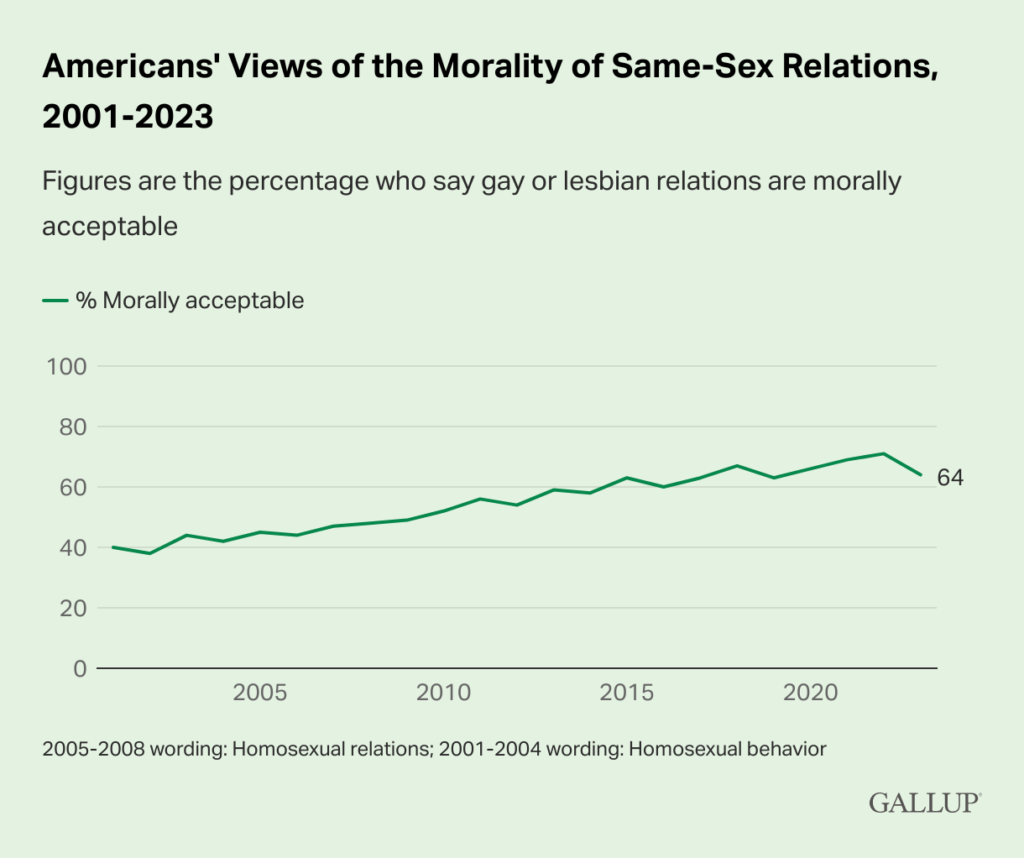
I’ve been experimenting with programming assisted by Large Language Models (LLMs) like ChatGPT. I am amazed at how good it is, and it seems clear to me that the great majority of programming work will be LLM-assisted, starting now. Here are some of the examples I’ve tried.
Think Python
For most of the exercises in Think Python, if you paste the question into ChatGPT, you get a correct answer on the first try. For example, here’s one of the exercises in the chapter on dictionaries:
Prompt: If you did Exercise 7, you already have a function named has_duplicates that takes a list as a parameter and returns True if there is any object that appears more than once in the list.
Use a dictionary to write a faster, simpler version of has_duplicates.
And here’s the response:
ChatGPT: Here’s one possible implementation of the has_duplicates function using a dictionary to keep track of the elements in the list:
def has_duplicates(lst):
"""
Returns True if there are any duplicates in the given list, False otherwise.
"""
seen = {}
for item in lst:
if item in seen:
return True
seen[item] = True
return False
ChatGPT: The function works by iterating through the list and adding each item to the seen dictionary. If an item is already in the dictionary, it means that we’ve seen it before and therefore there’s a duplicate in the list, so we return True. If we iterate through the entire list without finding any duplicates, we return False.
This implementation is faster and simpler than the previous one because checking for the presence of an item in a dictionary is much faster than iterating through the entire list each time. Also, using a dictionary allows us to keep track of the elements in the list using less code.
One of the later exercises asks what’s wrong with this class definition:
class Kangaroo:
"""A Kangaroo is a marsupial."""
def __init__(self, name, contents=[]):
"""Initialize the pouch contents.
name: string
contents: initial pouch contents.
"""
self.name = name
self.pouch_contents = contents
Here’s the response:
ChatGPT: The Kangaroo class has a potential issue in its __init__ method with the contents parameter. Specifically, the default value for the contents parameter is a mutable object (i.e., a list), which can cause unexpected behavior.
When the __init__ method is called without a contents argument, it creates a new instance of the list object and assigns it to the contents parameter. However, since the default value for contents is a mutable object, the same list object is used as the default value for all Kangaroo instances that don’t provide a contents argument.
This means that if you create two Kangaroo instances without providing a contents argument, both instances will share the same list object. This can lead to unexpected behavior if you modify the list of one Kangaroo instance, as the changes will be reflected in the other instance as well.
To fix this issue, you can use a more appropriate default value for the contents parameter, such as None, and then create a new list instance inside the __init__ method if no contents argument is provided, like this:
class Kangaroo:
def __init__(self, name, contents=None):
"""Initialize the pouch contents.
name: string
contents: initial pouch contents.
"""
self.name = name
if contents is None:
self.pouch_contents = []
else:
self.pouch_contents = contents
So that’s pretty good.
On Twitter, many people have helpfully pointed out that the exercises in Think Python, and solutions available on the web, are part of ChatGPT’s training corpus, so I am “testing on the training set”.
While that may be true, I think it misses the point several times over:
- The responses I saw were not my solutions, and based on a few Google searches, I could not find a source they were copied from. At worse, ChatGPT makes it easier and faster to find a correct solution than a conventional search. But it seems to be doing more than that, recombining elements of the training corpus in useful (possibly novel) ways.
- Even if LLMs do nothing more than retrieve solutions from a large database, that alone would accelerate the great majority of programming — so substantially that I think it will change the day-to-day work of a great majority of programmers.
Data Structures
One of my complaints about data structures classes is that most of the work students do is re-implementation of basic algorithms. Most of them have been available in libraries for a long time, which means there is an opportunity to spend less time on how they work and more time on how we use them to do more interesting things. I hope the prevalence of LLMs will accelerate this process.
Here’s one of the exercises from Data Structures and Information Retrieval in Python (aka DSIRP):
Prompt: Write a function called intersect that takes two LetterSet objects and returns a new LetterSet that represents the intersection of the two sets. In other words, the new LetterSet should contain only elements that appear in both sets. In a comment, identify the order of growth of this function.
I also provided the introduction to the question, which introduced the LetterSet object. Here’s the code ChatGPT generated:
def intersect(set1, set2):
bits = [a and b for a, b in zip(set1.bits, set2.bits)]
return LetterSet(bits)
And its explanation:
ChatGPT: The intersect function first creates a new list bits by using a list comprehension that computes the element-wise logical AND of the bits in the two LetterSet objects. The resulting list contains True values only for the elements that appear in both sets, and False values for all other elements.
The intersect function then creates a new LetterSet object using the bits list and returns it.
The order of growth of the intersect function is O(1), because the size of the LetterSet objects is fixed at 26 elements, and the function always performs a constant number of operations (i.e., create a new list using a list comprehension, create a new LetterSet object, and return it).
Unlike Think Python, DSIRP is not well known and if there are answers to these exercises on the web, they are not easy to find.
But again, I don’t think it matters where the answers are coming from. The impact on the practice of programming is the same: the solution to basic programming problems can be generated quickly, which means programmers will be able to spend more time on higher-value activities.
Probability of Superiority
Let’s see how ChatGPT does with something a little harder:
Prompt: write a python function that takes the parameters of two poisson distributions and computes the probability of superiority
Here’s the code (I’ll skip the explanatory text):
from math import exp, factorial
def poisson_probability_of_superiority(lambda1, lambda2):
"""
Calculates the probability of superiority between two Poisson distributions.
Parameters:
lambda1 (float): the parameter of the first Poisson distribution.
lambda2 (float): the parameter of the second Poisson distribution.
Returns:
float: the probability that a random variable drawn from the first Poisson distribution is greater than a random variable drawn from the second Poisson distribution.
"""
prob = 0
for i in range(int(lambda1) + 1):
for j in range(int(lambda2)):
prob += (exp(-lambda1) * lambda1**i / factorial(i)) * (exp(-lambda2) * lambda2**j / factorial(j))
return prob
I asked for a version that uses SciPy and NumPy, and got this:
import numpy as np
from scipy.stats import poisson
def poisson_probability_of_superiority(lambda1, lambda2):
"""
Calculates the probability of superiority between two Poisson distributions.
Parameters:
lambda1 (float): the parameter of the first Poisson distribution.
lambda2 (float): the parameter of the second Poisson distribution.
Returns:
float: the probability that a random variable drawn from the first Poisson distribution is greater than a random variable drawn from the second Poisson distribution.
"""
k = np.arange(int(lambda1) + 1)
pmf1 = poisson.pmf(k, lambda1)
cdf2 = poisson.cdf(k - 1, lambda2)
prob = np.sum(pmf1 * (1 - cdf2))
return prob
This is close to being a good solution, but there are still a couple of problems. However, after just a few more iterations, I got a good solution to this problem, and a similar solution that works with exponential distributions. You can see the sequence of prompts and responses in this notebook.
I have no idea where this solution came from. If you Google for a solution to this problem, the results are not very useful. If anyone reading this can find the source of this code, please let me know.
Looking at the sequence of solutions ChatGPT generated, I got several ideas for solving this problem that I might not have come up with. The solutions I got still need some work, but I could polish them off without much additional effort. And I got ChatGPT to generate a unit test as well:
def test_exponential_probability_of_superiority():
# Test case with known result
lambda1 = 0.5
lambda2 = 1.0
expected_prob = 0.368
tol = 0.001
prob = exponential_probability_of_superiority(lambda1, lambda2)
assert abs(prob - expected_prob) < tol, f"Test case failed: expected {expected_prob}, but got {prob}"
I would not have confidence in this solution without additional refactoring and testing, but ChatGPT got me off to a very fast start on a non-trivial problem.
Correlation in Elm
If you find yourself working with an unfamiliar language or libraries, LLMs can accelerate your learning — by a lot. Recently I started learning Elm, so I am not very good at it. And it is not a commonly-used language, so I expect the corpus to be limited. Let’s see how it does on a basic stats question:
Prompt: write an elm function to compute the correlation of two lists of floats
Here’s the response:
correlation : List Float -> List Float -> Maybe Float
correlation xs ys =
let
n = List.length xs
meanX = List.sum xs / Float.fromInt n
meanY = List.sum ys / Float.fromInt n
numerator = List.foldl (\(x, y) acc -> acc + ((x - meanX) * (y - meanY))) 0 (List.zip xs ys)
denominatorX = List.foldl (\x acc -> acc + ((x - meanX) * (x - meanX))) 0 xs
denominatorY = List.foldl (\y acc -> acc + ((y - meanY) * (y - meanY))) 0 ys
denominator = sqrt (denominatorX * denominatorY)
in
if denominator == 0 then
Nothing
else
Just (numerator / denominator)
That’s pretty good, and the explanation is even better:
ChatGPT: The correlation function takes in two lists of floats xs and ys and computes the Pearson correlation coefficient between them. The result is returned as a Maybe Float, as it is possible for the denominator to be 0 if one of the lists is empty or if all the elements in one of the lists are the same, in which case the correlation is undefined.
The function first computes the mean of each list and then uses these means to calculate the numerator of the correlation coefficient using a fold over the zipped lists. It then calculates the denominators for each list separately, and computes the denominator of the correlation coefficient by taking the product of these two denominators and then taking the square root. Finally, the function checks if the denominator is 0 and returns Nothing in that case, or returns the correlation coefficient as a Just Float.
To someone getting the hang of Elm’s type system, this is very helpful.
I asked it to generate a version using map instead of foldl, and another using existing functions to compute mean and variance. You can see the entire exchange in this notebook.
Coding is different now
When I wrote about these examples on Twitter, I got more disagreement than I expected. Lots of people reminded me of the limitations of LLMs for generating code. But again, I think this is missing the point. Even if LLMs only solve simple programming problems, there are a lot of simple programming problems! And I conjecture that most programmers spend most of their time on things that ChatGPT could greatly accelerate — or just solve.
And we’ve only been using them for a few weeks! LLMs will get better, and we will get better at using them. So I stand by my conclusion: The great majority of coding will be LLM-assisted, starting now.
LLMs will also have a huge effect on how we teach and learn programming, but I’ll get to that later.
Addendum: The New Skills
Most of the skills programmers use now are also the skills they will need to work with LLMs. Breaking a problem down into smaller problems, and designing good interfaces between components, are still essential skills. One difference is that now, for each of those smaller problems, programmers need to decide whether it would be easier and faster to solve it themselves or start a conversation with an LLM.
After deciding whether to start a conversation, the next big question is how to compose the prompt. In particular, it makes a big difference how much information is included as a preamble. Just as we all got better at composing search terms, we’ll get better at composing prompts. (I have a hard time not being polite to ChatGPT. I wonder if that will persist, or we’ll start writing blunt imperatives.)
And a final question is when to stop a conversation and work with the code you have, or ask for further refinements. In my experiments, it felt like I reached a point of diminishing returns, where further refinements were likely to introduce new errors. On the other hand, asking for at least two versions of a function produced useful variations.
At least for now, we cannot assume that code produced by an LLM is correct, which means it needs extensive testing. People who are used to test-driven development (TDD) will have a head start with LLM-assisted programming. Of course, we can use LLMs to generate unit tests as well, but then we have to validate the unit tests, too.
Which brings me to what I think will be the most important skill for LLM-assisted programming: reading code. LLMs can generate code much faster than we can understand it, so the ability to read, understand, and check code will be critical.
The other skill that will become more important is meta-language, that is, the vocabulary we use to talk about programs. In my correlation in Elm example, I asked ChatGPT to “factor out the anonymous function”, and it new exactly what I meant. In general, it seems to understand the meta-language of programming well, so it will be useful if we can speak it.
Most of the skills programmers need to work with LLMs are the skills they already have, but some of them will become more important, especially problem decomposition, reading code, and speaking the meta-language of programming.