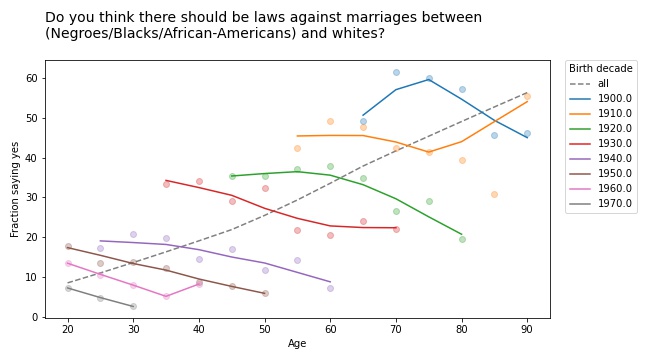
A recent post on Reddit asks, “Why was Bayes’ Theory not accepted/popular historically until the late 20th century?”
Great question! As always, there are many answers to a question like this, and the good people of Reddit provide several. But the first and most popular answer is, in my humble opinion, wrong.
The story goes something like this: “Bayesian methods are computationally expensive, so even though they were known in the early days of modern statistics, they were not practical until the availability of computational power and the recent development of efficient sampling algorithms.”
This theory is appealing because, if we look at problems where Bayesian methods are currently used, many of them are large and complex, and would indeed have been impractical to solve just a few years ago.
I think it is also appealing because it rationalizes the history of statistics. Ignoring Bayesian methods for almost 100 years wasn’t a mistake, we can tell ourselves; we were just waiting for the computers to catch up.
Well, I’m sorry, but that’s bunk. In fact, we could have been doing Bayesian statistics all along, using conjugate priors and grid algorithms.
Conjugate Priors
A large fraction of common, practical problems in statistics can be solved using conjugate priors, and the solutions require almost no computation. For example:
- Problems that involve estimating proportions can be solved using a beta prior and binomial likelihood function. In that case, a Bayesian update requires exactly two addition operations.
- In the multivariate case, with a Dirichlet prior and a multinomial likelihood function, the update consists of adding two vectors.
- Problems that involve estimating rates can be solved with a gamma prior and an exponential or Poisson likelihood function — and the update requires two additions.
- For problems that involve estimating the parameters of a normal distribution, things are a little more challenging: you have to compute the mean and standard deviation of the data, and then perform about a dozen arithmetic operations.
For details, see Chapter 18 of Think Bayes. And for even more examples, see this list of conjugate priors. All of these could have been done with paper and pencil, or chalk and rock, at any point in the 20th century.
And these methods would be sufficient to solve many common problems in statistics, including everything covered in an introductory statistics class, and a lot more. In the time it takes for students to understand p-values and confidence intervals, you could teach them Bayesian methods that are more interesting, comprehensible, and useful.
In terms of computational efficiency, updates with prior conjugates border on miraculous. But they are limited to problems where the prior and likelihood can be well modeled by simple analytic functions. For other problems, we need other methods.
Grid Algorithms
The idea behind grid algorithms is to enumerate all possible values for the parameters we want to estimate and, for each set of parameters:
- Compute the prior probability,
- Compute the likelihood of the data,
- Multiply the priors and the likelihoods,
- Add up the products to get the total probability of the data, and
- Divide through to normalize the posterior distribution.
If the parameters are continuous, we approximate the results by evaluating the prior and likelihood at a discrete set of values, often evenly spaced to form a d-dimensional grid, where d is the number of parameters.
If there are n possible values and m elements in the dataset, the total amount of computation we need is proportional to the product n m, which is practical for most problems. And in many cases we can do even better by summarizing the data; then the computation we need is proportional to n + m.
For problems with 1-2 parameters — which includes many useful, real-world problems — grid algorithms are efficient enough to run on my 1982 vintage Commodore 64.
For problems with 3-4 parameters, we need a little more power. For example, in Chapter 15 of Think Bayes I solve a problem with 3 parameters, which takes a few seconds on my laptop, and in Chapter 17 I solve a problem that takes about a minute.
With some optimization, you might be able to estimate 5-6 parameters using a coarse grid, but at that point you are probably better off with Markov chain Monte Carlo (MCMC) or Approximate Bayesian Computation (ABC).
For more than six parameters, grid algorithms are not practical at all. But you can solve a lot of real-world problems with fewer than six parameters, using only the computational power that’s been available since 1970.
So why didn’t we?
Awful People, Bankrupt Ideas
In 1925, R.A. Fisher wrote, “… it will be sufficient … to reaffirm my personal conviction … that the theory of inverse probability is founded upon an error, and must be wholly rejected.” By “inverse probability”, he meant what is now called Bayesian statistics, and this is probably the nicest thing he ever wrote about it.
Unfortunately for Bayesianism, Fisher’s “personal conviction” carried more weight than most. Fisher was “the single most important figure in 20th century statistics”, at least according this article. He was also, according to contemporaneous accounts, a colossal jerk who sat on 20th century statistics like a 400-pound gorilla, a raving eugenicist, even after World War II, and a paid denier that smoking causes lung cancer.
For details of the story, I recommend The Theory That Would Not Die, where Sharon Bertsch McGrayne writes: “If Bayes’ story were a TV melodrama, it would need a clear-cut villain, and Fisher would probably be the audience’s choice by acclamation.”
Among other failings, Fisher feuded endlessly with Karl Pearson, Egon Pearson, and Jerzy Neyman, to the detriment of statistics, science, and the world. But he and Neyman agreed about one thing: they were both rabid and influential anti-Bayesians.
The focus of their animosity was the apparent subjectivity of Bayesian statistics, particularly in the choice of prior distributions. But this concern is, in my personal conviction, founded upon an error: the belief that frequentist methods are less subjective than Bayesian methods.
All statistical methods are based on modeling decisions, and modeling decisions are subjective. With Bayesian methods, the modeling decisions are represented more explicitly, but that’s a feature, not a bug. As I.J. Good said, “The subjectivist [Bayesian] states his judgements, whereas the objectivist [frequentist] sweeps them under the carpet by calling assumptions knowledge, and he basks in the glorious objectivity of science.”
In summary, it would be nice to think it was reasonable to neglect Bayesian statistics for most of the 20th century because we didn’t have the computational power to make them practical. But that’s a rationalization. A much more substantial part of the reason is the open opposition of awful people with bankrupt ideas.
What does GPT think?
Update September 2025: I wrote this article before LLMs were in wide use. So I was curious to see what ChatGPT thinks of it.
Where it’s strongest
- Conjugate priors and grid algorithms really were feasible
The point that many standard Bayesian updates require just a few arithmetic operations is absolutely right. Beta–binomial, gamma–Poisson, normal–normal, etc., were all within easy reach of anyone doing applied stats in the early 20th century. And grid methods for 1–2 parameters could have been done on slide rules or early calculators. So it’s historically inaccurate to say “Bayes was impossible without modern computers.”
- The sociology of science matters
The post rightly highlights how much Fisher’s stature (and temperament) shaped the discipline. Statistics developed as a community, with gatekeepers, priorities, and academic politics. That context is often missing when people assume computational constraints were the decisive factor.
- The critique of “objectivity”
The argument that frequentist methods were no less subjective than Bayesian ones is well put. Making assumptions explicit via priors is not inherently worse than burying assumptions in model form or test design.
Where it could be more nuanced
Teaching and pedagogy
Saying you could have taught Bayes instead of p-values in intro stats is true in principle, but history shows pedagogy is conservative. Frequentist methods were entrenched in textbooks, curricula, and exam systems. Switching to Bayesianism wasn’t just a matter of arithmetic feasibility.
Complex problems were genuinely out of reach
While it’s true conjugate priors handled many bread-and-butter problems, once you move beyond simple distributions or low-dimensional parameter spaces, the practical work does explode. MCMC was a breakthrough precisely because real-world scientific models quickly exceeded the 2–3 parameter realm. So the “computational barrier” explanation is not wholly bunk—it just doesn’t account for the whole story.
Fisher wasn’t the only factor
Fisher looms large, but the frequentist program (Neyman–Pearson hypothesis testing, confidence intervals, large-sample theory) also had its own intrinsic appeal: it offered procedures with guarantees that looked “objective” and fit well with the needs of experimental science at the time. That institutional fit helped frequentism dominate, even apart from Fisher’s personality.