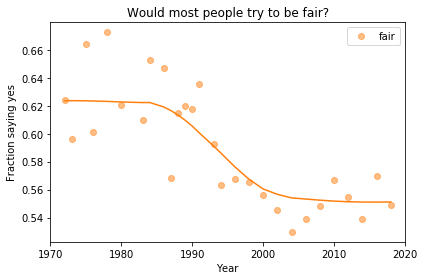
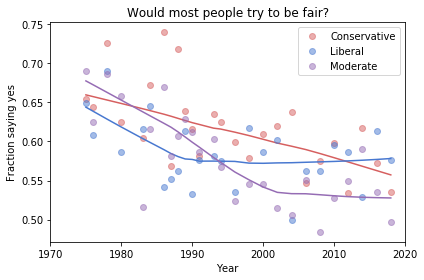
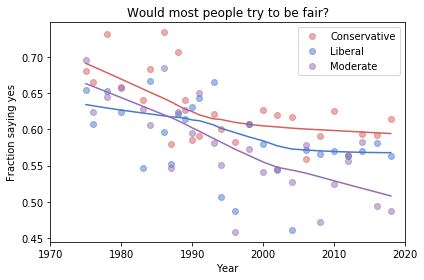
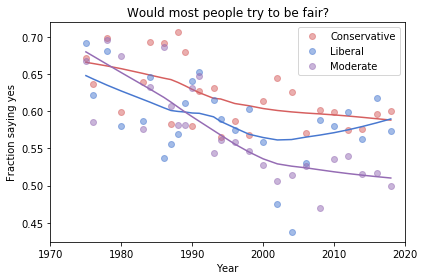
The Foundation Fallacy
At Olin College recently, I met with a group from the Kyiv School of Economics who are creating a new engineering program. I am very impressed with the work they are doing, and their persistence despite everything happening in Ukraine.
As preparation for their curriculum design process, they interviewed engineers and engineering students, and they identified two recurring themes: passion and disappointment — that is, passion for engineering and disappointment with the education they got.
One of the professors, reflecting on her work experience, said she thought her education had given her a good theoretical foundation, but when she went to work, she found that it did not apply — she felt like she was starting from scratch.
I suggested that if a “good theoretical foundation” is not actually good preparation for engineering work, maybe it’s not actually a foundation — maybe it’s just a hoop for the ones who can jump through it, and a barrier for the ones who can’t.
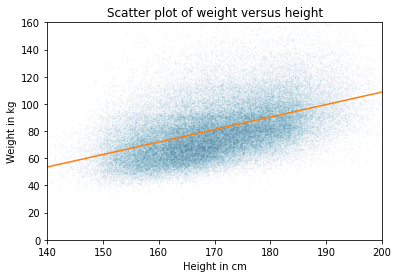
The engineering curriculum is based on the assumption that math (especially calculus) and science (especially physics) are (1) the foundations of engineering, and therefore (2) the prerequisites of engineering education. Together, these assumptions are what I call the Foundation Fallacy.
To explain what I mean, I’ll use an example that is not exactly engineering, but it demonstrates the fallacy and some of the rhetoric that sometimes obscures it.
A recent post on LinkedIn includes this image:

And this text:
What makes a data scientist a data scientist? Is it their ability to use R or Python to solve data problems? Partially. But just like any tool, I’d rather those making decisions with data truly understand the tools they’re using so that when something breaks, they can diagnose it.
As the image shows, running a linear regression in R or Python is just the tip of the iceberg. What lies beneath, including the theory, assumptions, and reasoning that make those models work, is far more substantial and complex.
ChatGPT can write the code. But it’s the data scientist who decides whether that model is appropriate, interprets the results, and translates them into sound decisions. That’s why I don’t just hand my students an R function and tell them to use it. We dig into why it works, not just that it works. The questions and groans I get along the way are all part of the process, because this deeper understanding is what truly sets a data scientist apart.
Most of the replies to this post, coming from people who jumped through the hoops, agree. The ones who hit a barrier, and the ones groaning in statistics classes, might have a different opinion.
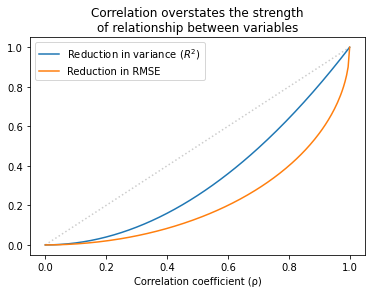
I completely agree that choosing models, interpreting results, and making sound decisions are as important as programming skills. But I’m not sure the things in that iceberg actually develop those skills — in fact, I am confident they don’t.
And maybe for someone who knows these topics, “when something breaks, they can diagnose it.” But I’m not sure about that either — and I am quite sure it’s not necessary. You can understand multiple collinearity without a semester of linear algebra. And you can get what you need to know about AIC without a semester of information theory.
For someone building a regression model, a high-level understanding of causal inference is a lot more useful than the Gauss-Markov theorem. Also more useful: domain knowledge, understanding the context, and communicating the results. Maybe math and science classes could teach these topics, but the ones in this universe really, really don’t.
Everything I just said about linear regression also applies to engineering. Good engineers understand context, not just technology; they understand the people who will interact with, and be affected by, the things they build; and they can communicate effectively with non-engineers.
In their work lives, engineers hardly ever use calculus — more often they use computational tools based on numerical methods. If they know calculus, does that knowledge help them use the tools more effectively, or diagnose problems? Maybe, but I really doubt it.
My reply to the iceberg analogy is the car analogy: you can drive a car without knowing how the engine works. And knowing how the engine works does not make you a better driver. If someone is passionate about driving, the worst thing we can do is make them study thermodynamics. The best thing we can do is let them drive.