The Gender Gap in Political Beliefs Is Small
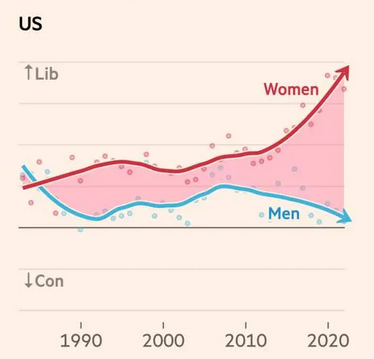
In previous articles (here, here, and here) I’ve looked at evidence of a gender gap in political alignment (liberal or conservative), party affiliation (Democrat or Republican), and policy preferences.
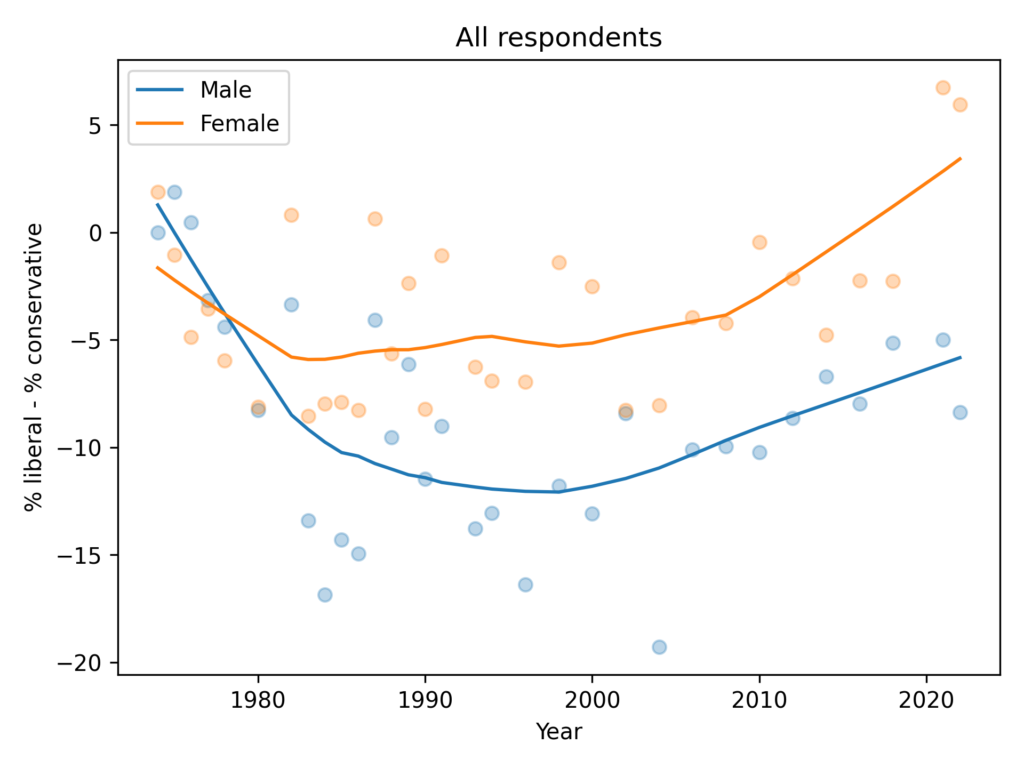
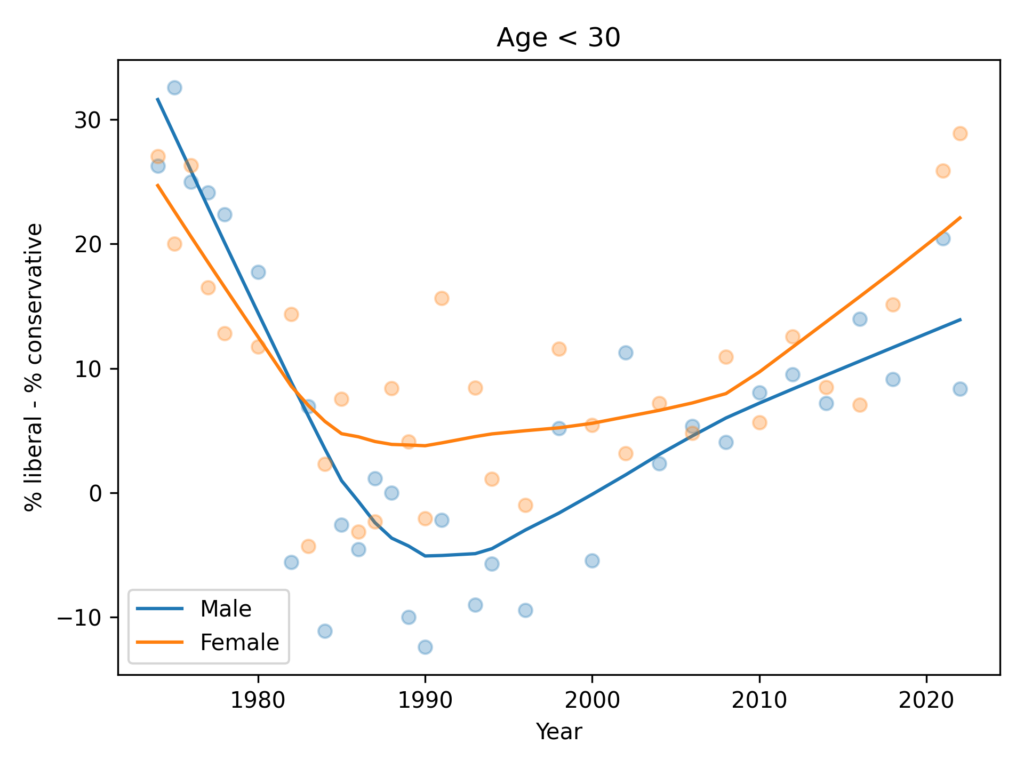
Using data from the GSS, I found that women are more likely to say they are liberal, and more likely to say they are Democrats, by 5-10 percentage points. But in their responses to 15 policy questions that most distinguish conservatives and liberals, men and women give similar answers.
In other words, the political gap is mostly in what people say about themselves, not in what they believe about specific policy questions.
Now let’s see if we get similar results with ANES data. As with the GSS, I looked for questions where liberals and conservatives give different answers. From those, I selected questions about specific policies, plus four questions related to moral foundations, with preference for questions asked over a long period of time. Here are the 16 topics that met these criteria:
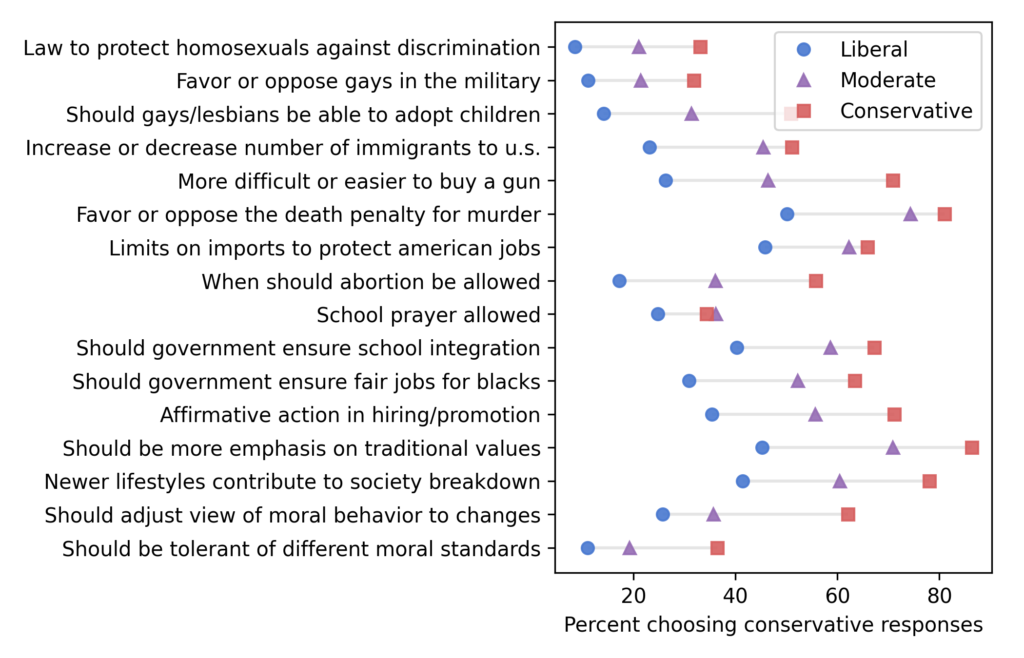
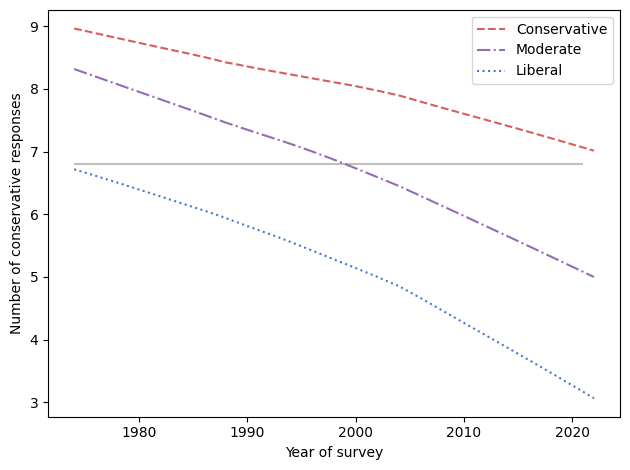
For each question, I identified one or more responses that were more likely to be given by conservatives, which is what I’m calling “conservative responses”.
Not every respondent was asked every question, so I used a Bayesian method based on item response theory to fill missing values. You can get the details of the method here.
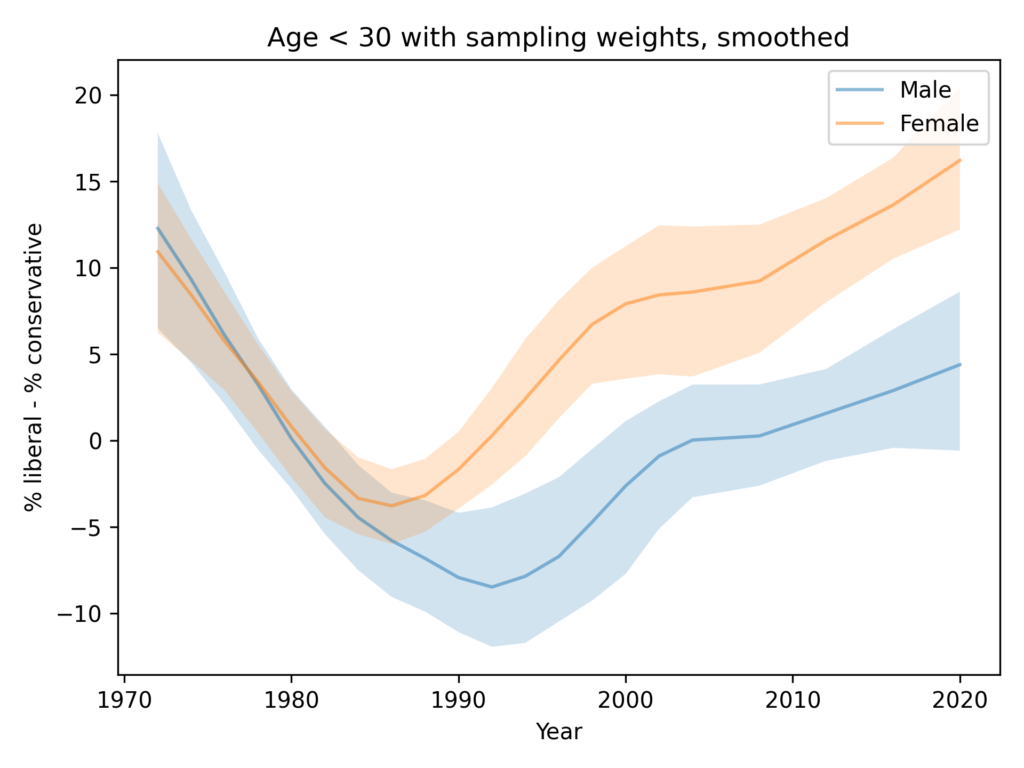
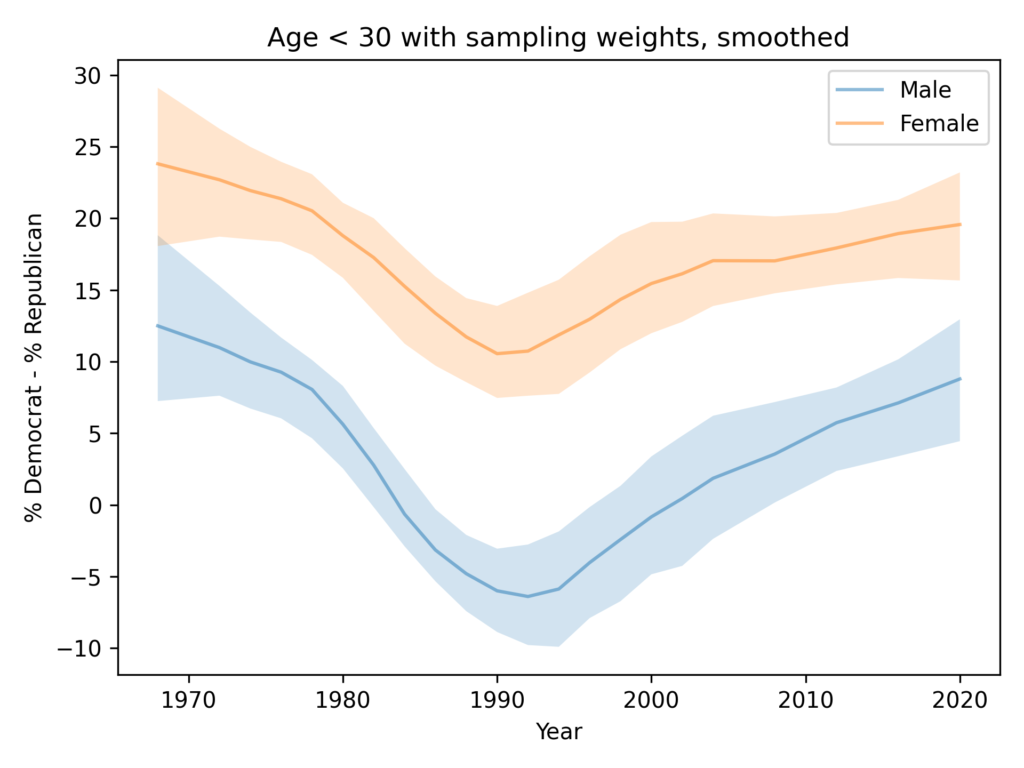
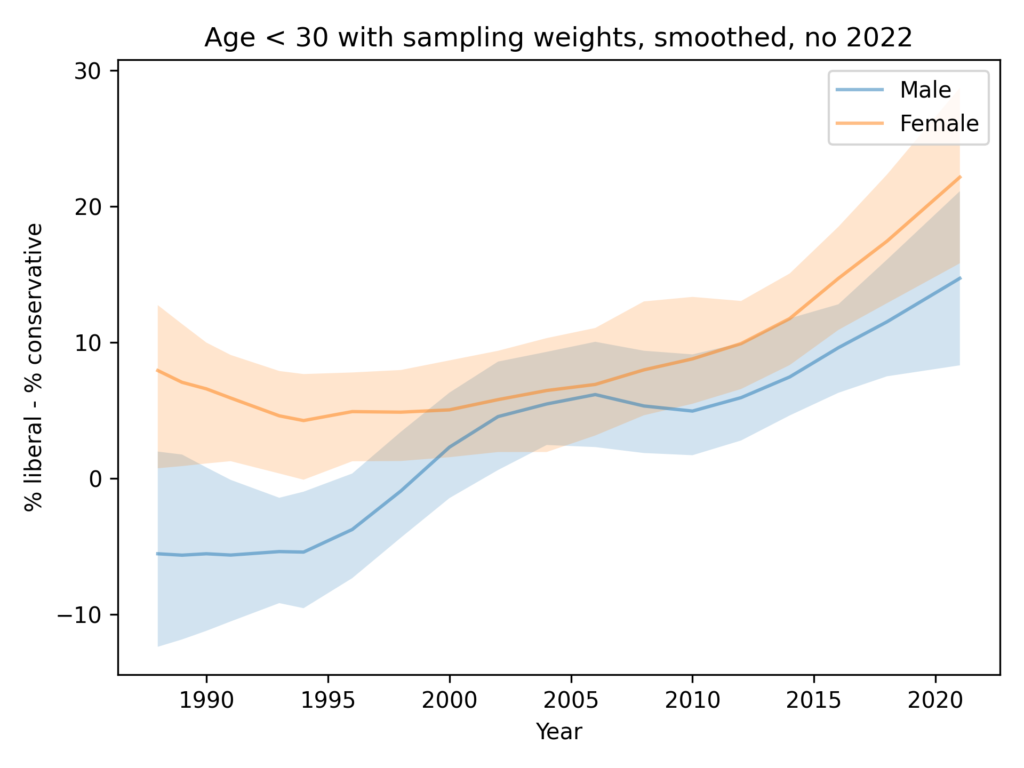
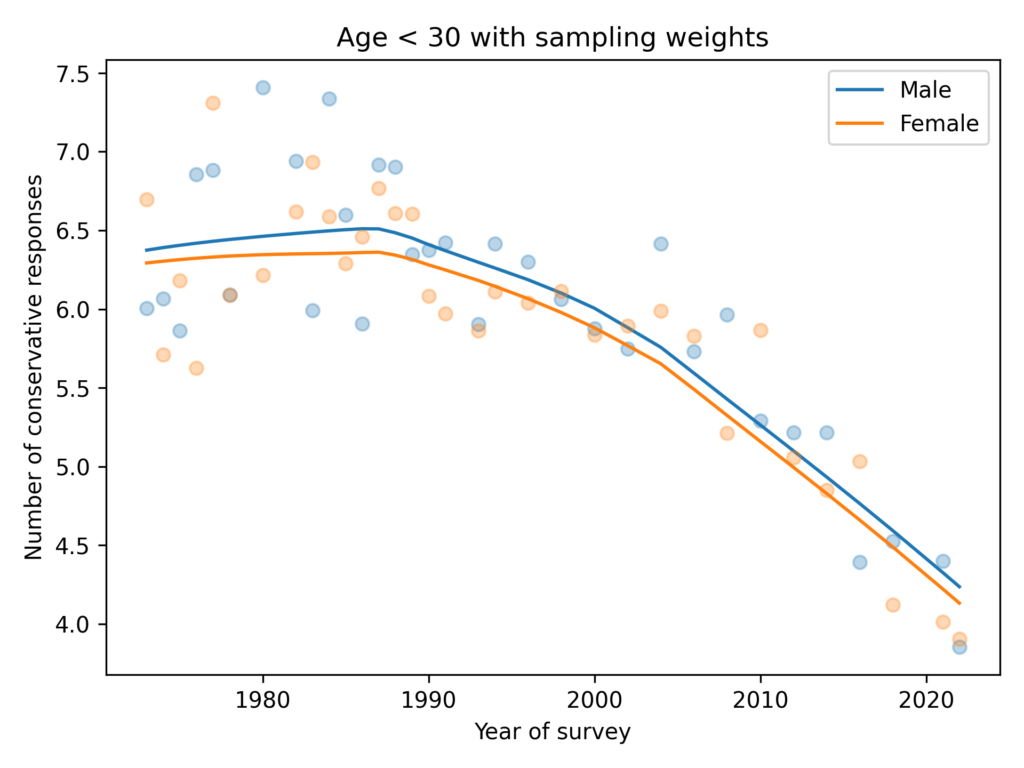
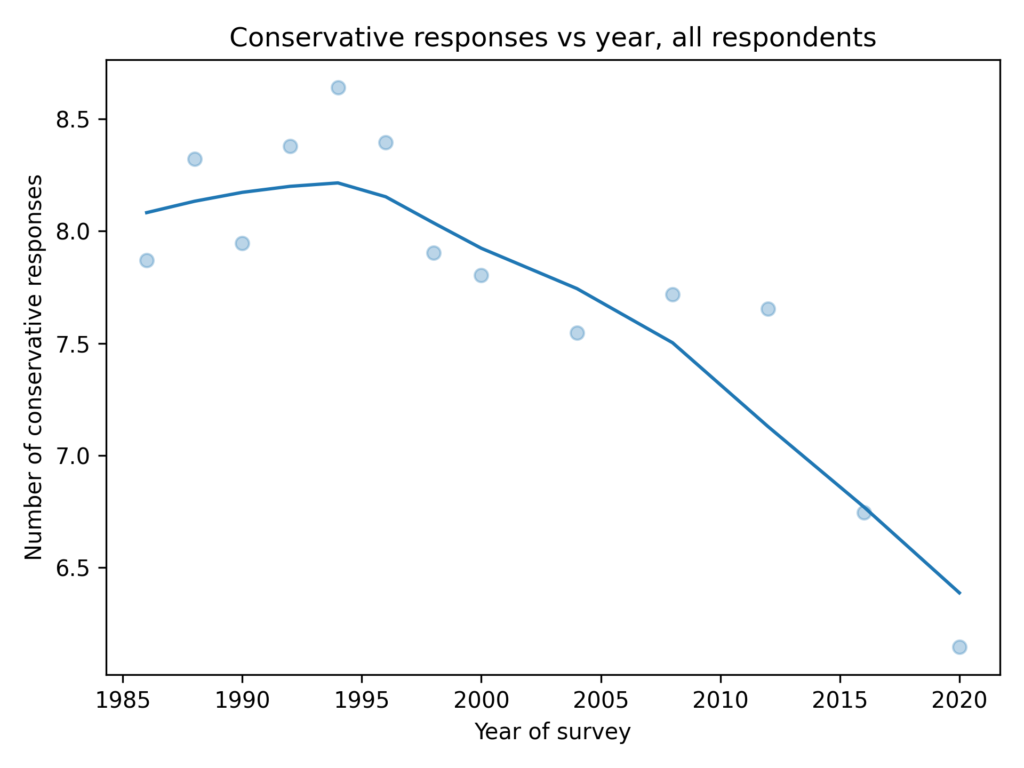
As in the GSS data, the average number of conservative responses has gone down over time.
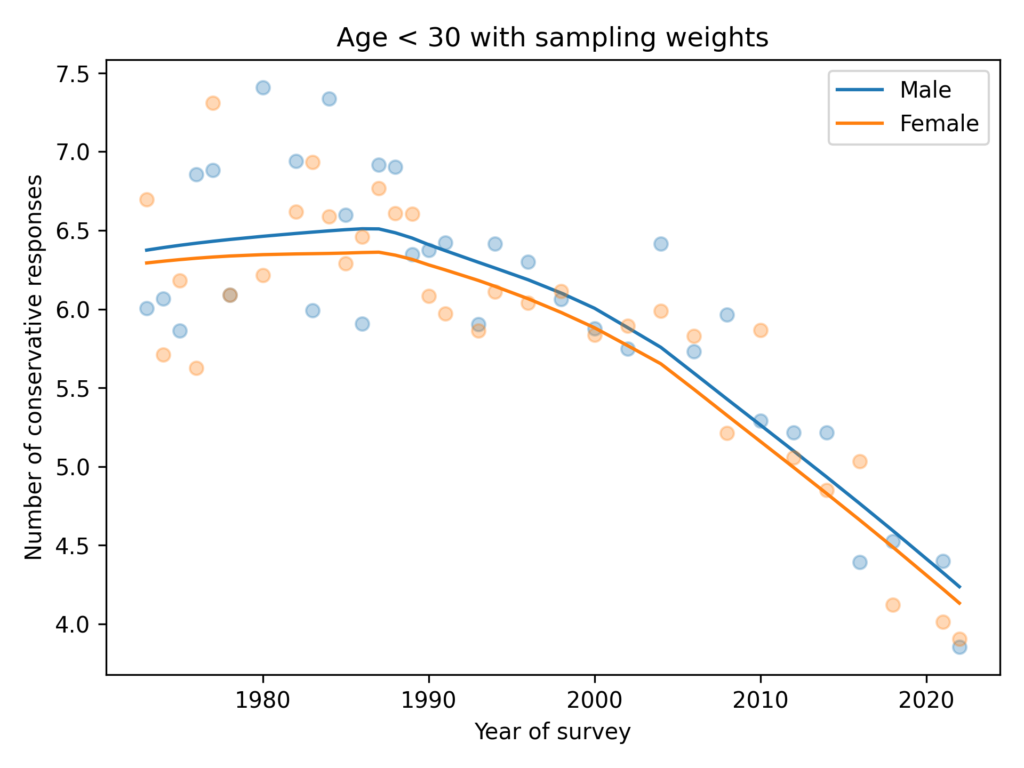
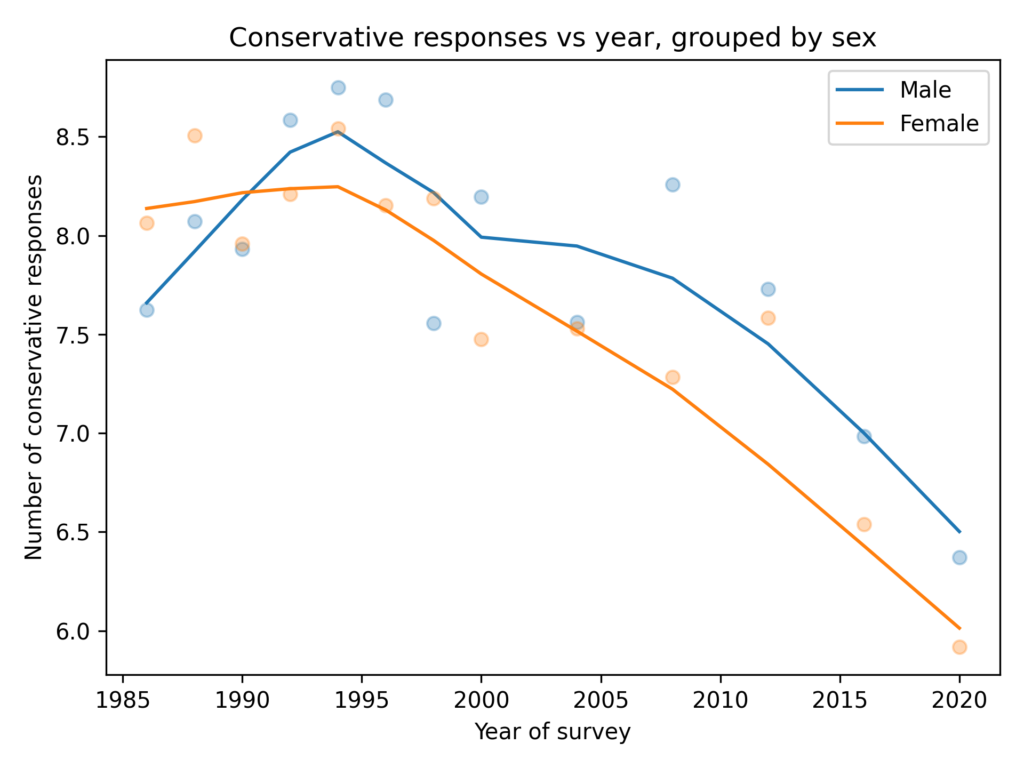
Men give more conservative responses than women, on average, but the differences is only half a question, and the gap is not getting bigger.
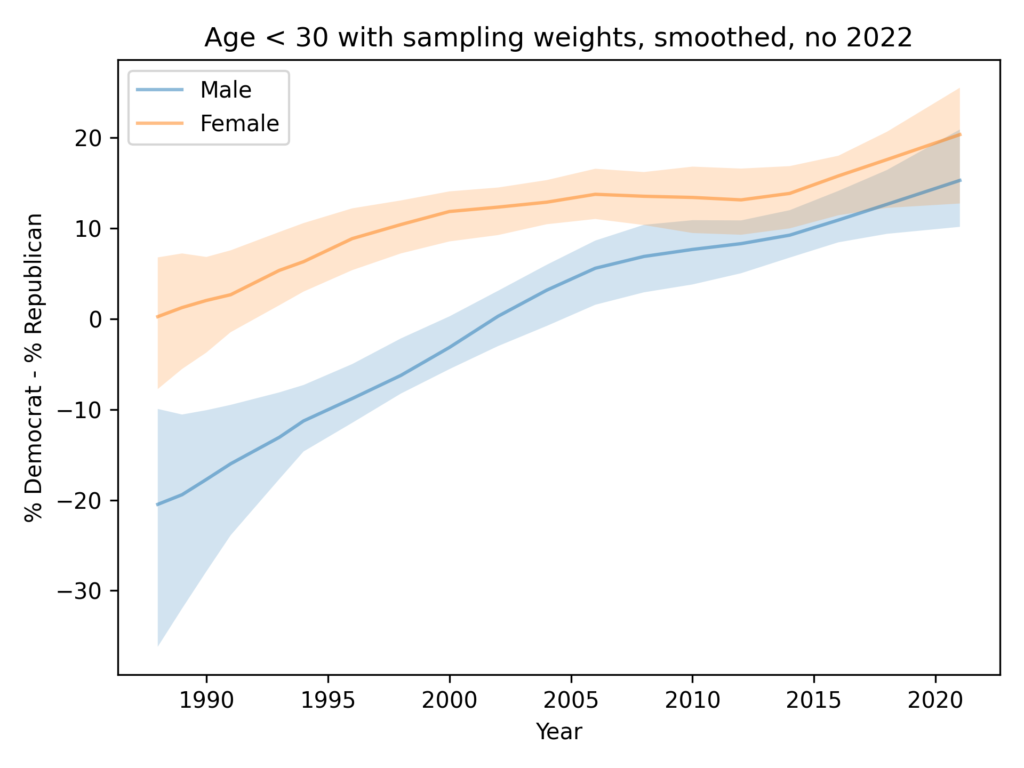
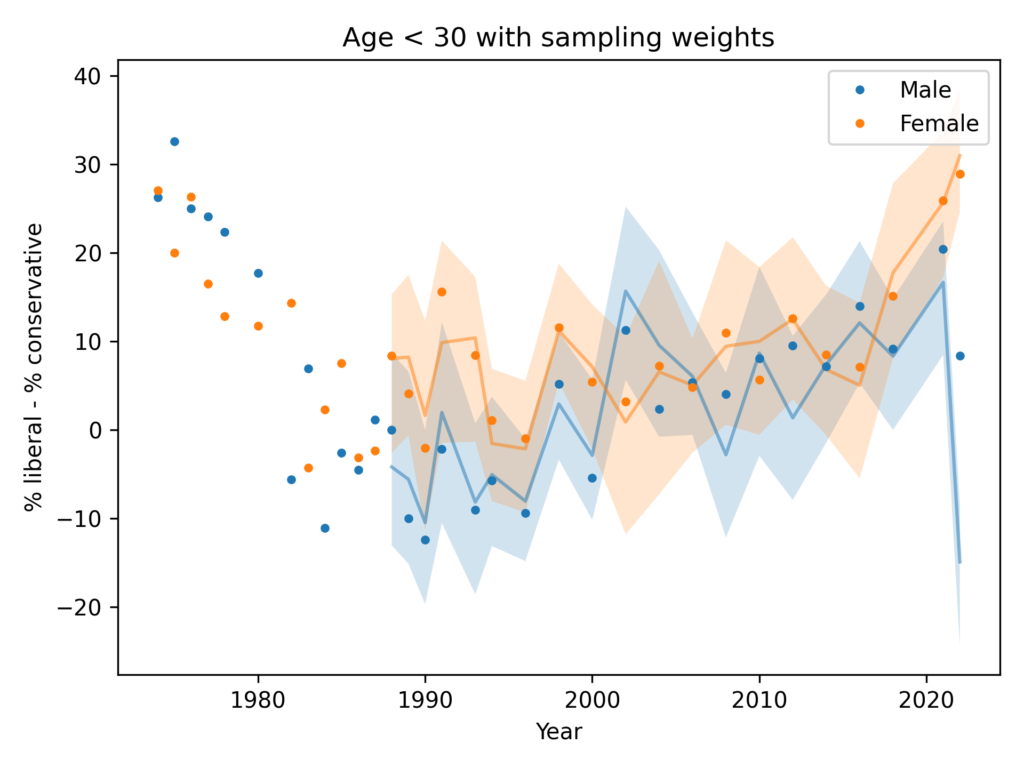
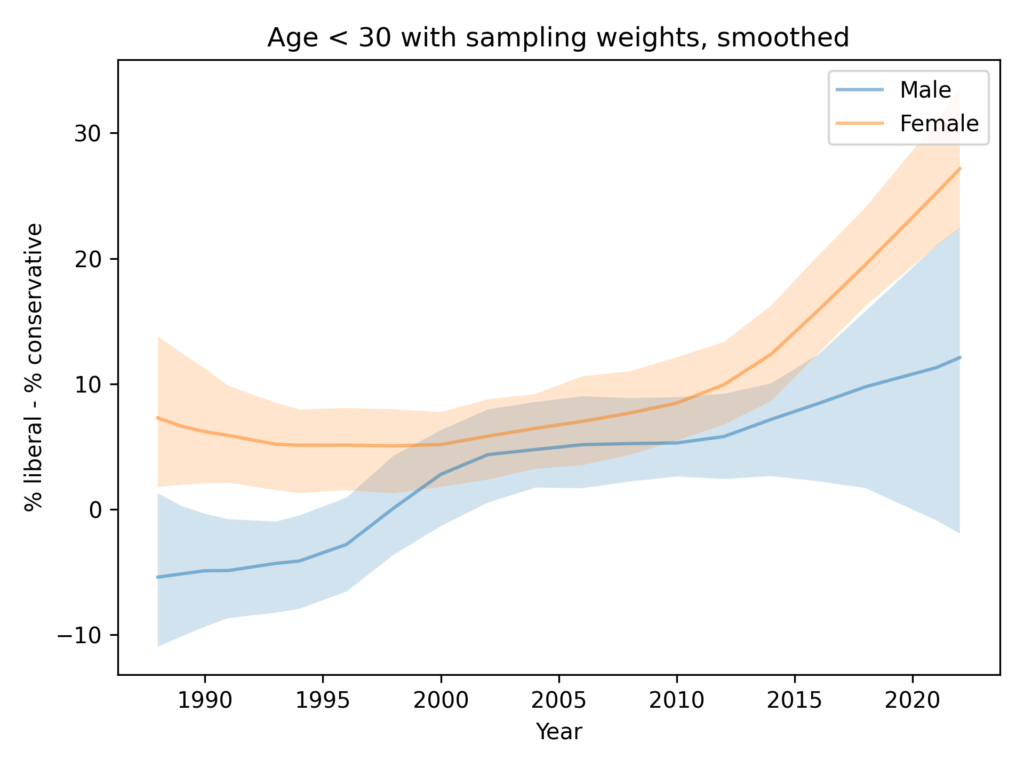
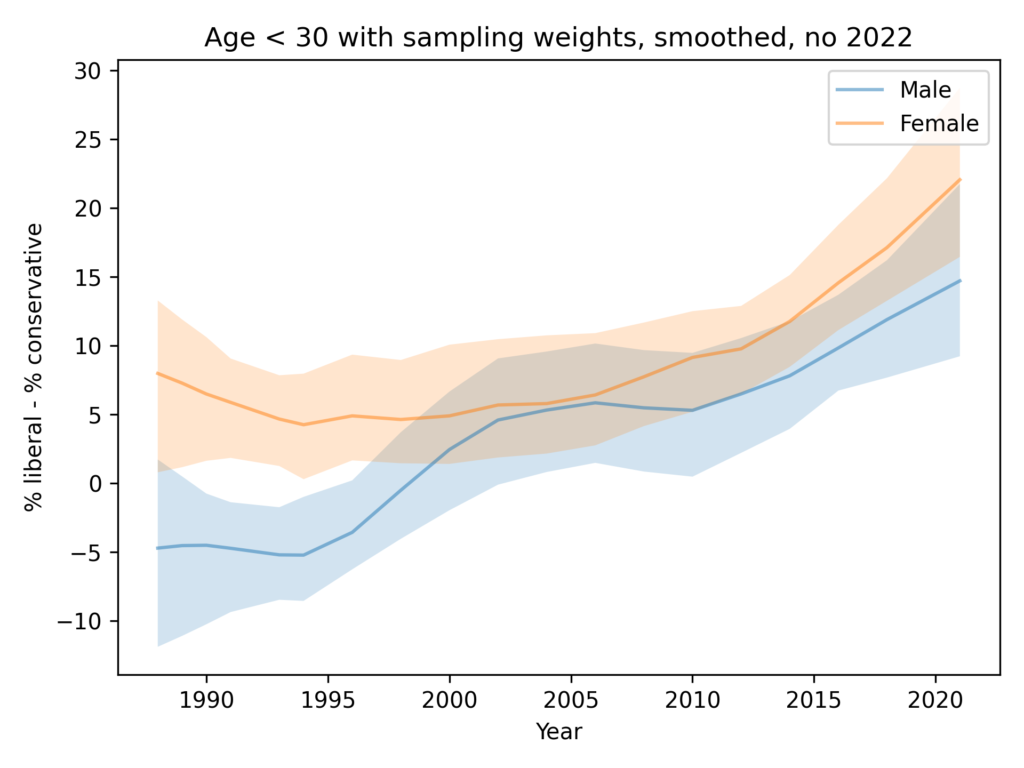
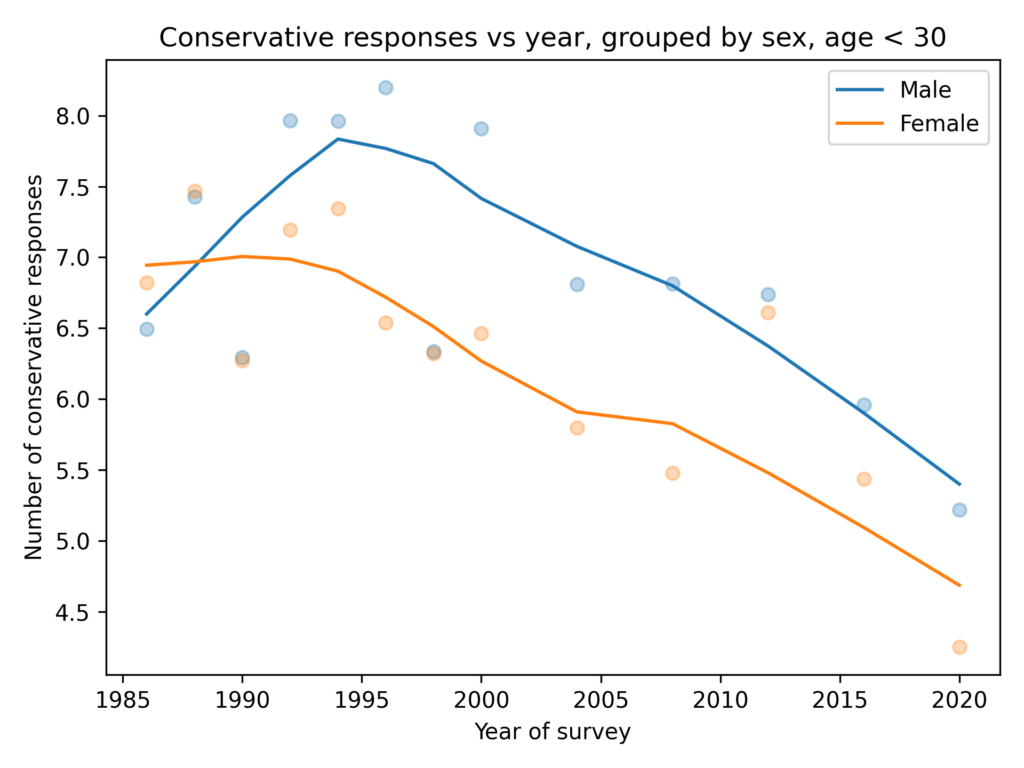
Among people younger than 30, the gap is closer to 1 question, on average. And it is not growing.
In summary:
- In the ANES, there is no evidence of a growing gender gap in political alignment, party affiliation, or policy preferences.
- In both the GSS and the ANES the gap in policy preferences is small and not growing.
The details of this analysis are in this Jupyter notebook.
What about economics?
Many of the questions in the previous section are about social issues. On economic issues some of the patterns are different. Here are 15 questions I selected that are mostly about federal spending.
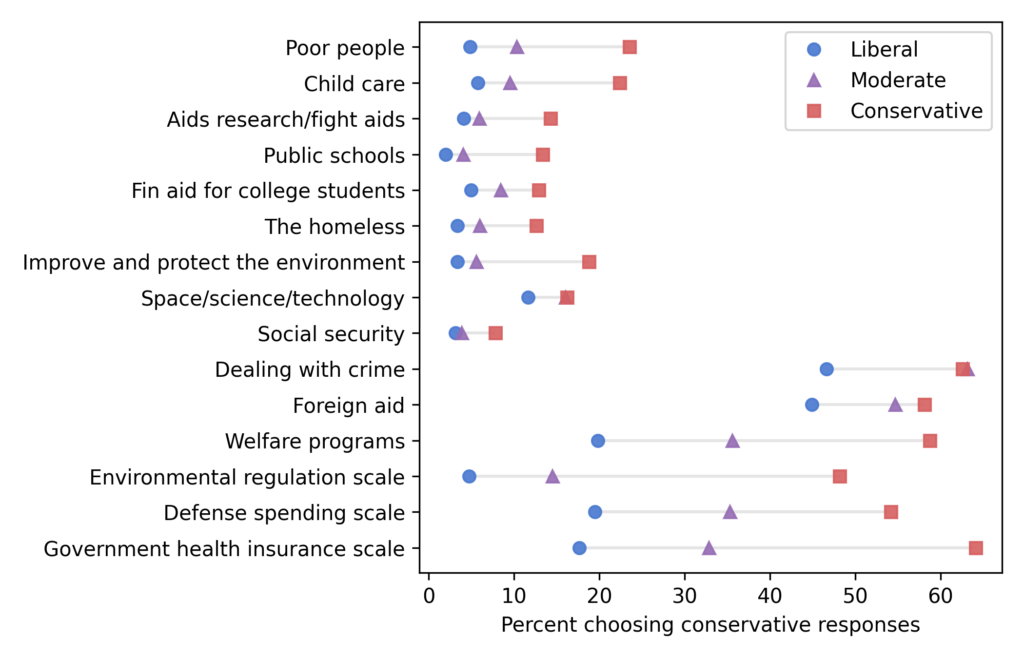
Unlike the social issues, which trend liberal over time, responses to these questions are almost unchanged.
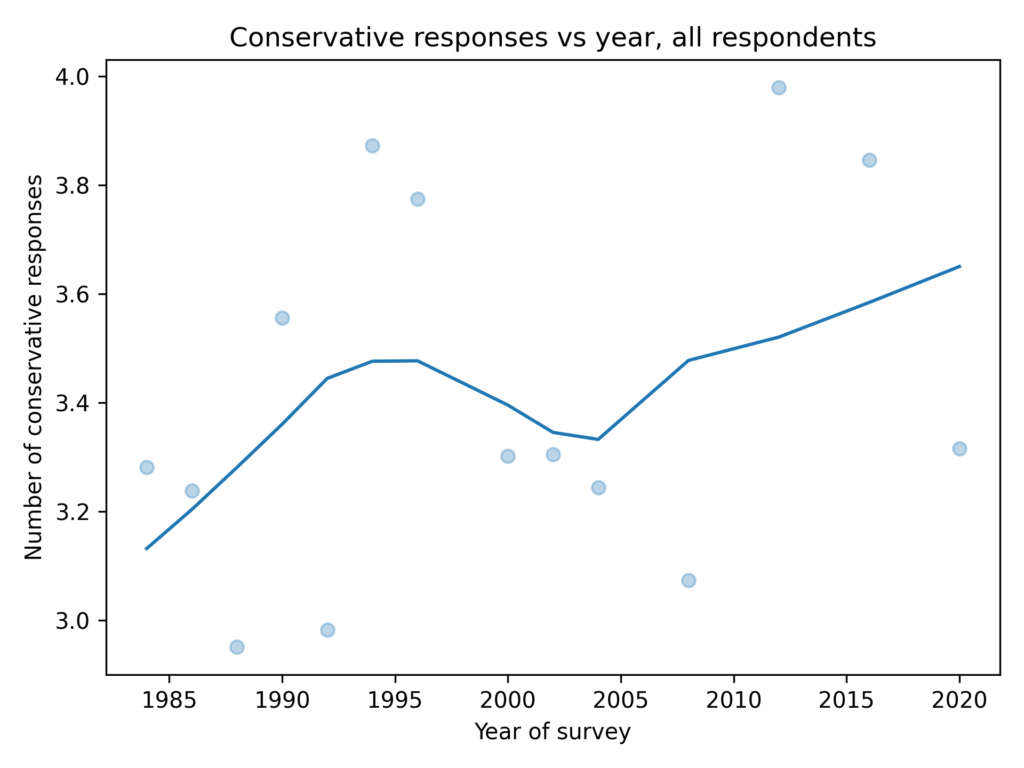
In the general population, the gender gap is about 0.5 questions and not growing.
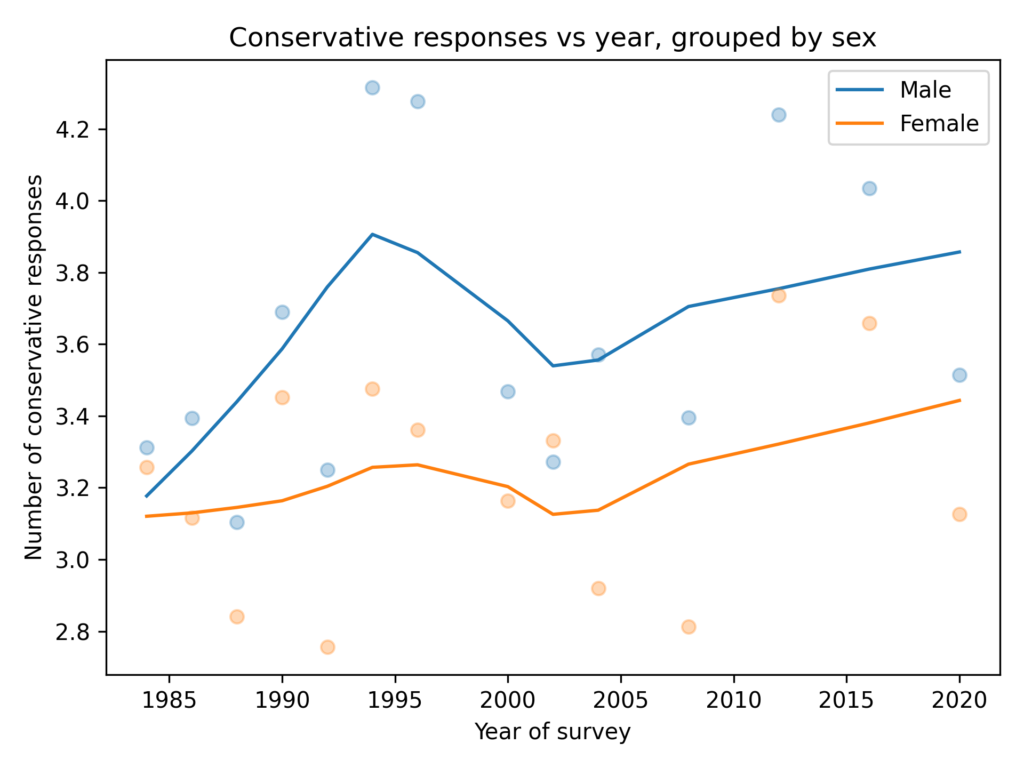
Among young adults, the gender gap is smaller, and not growing.

On a total of 30 questions where conservatives and liberal disagree, men and women provide similar responses.