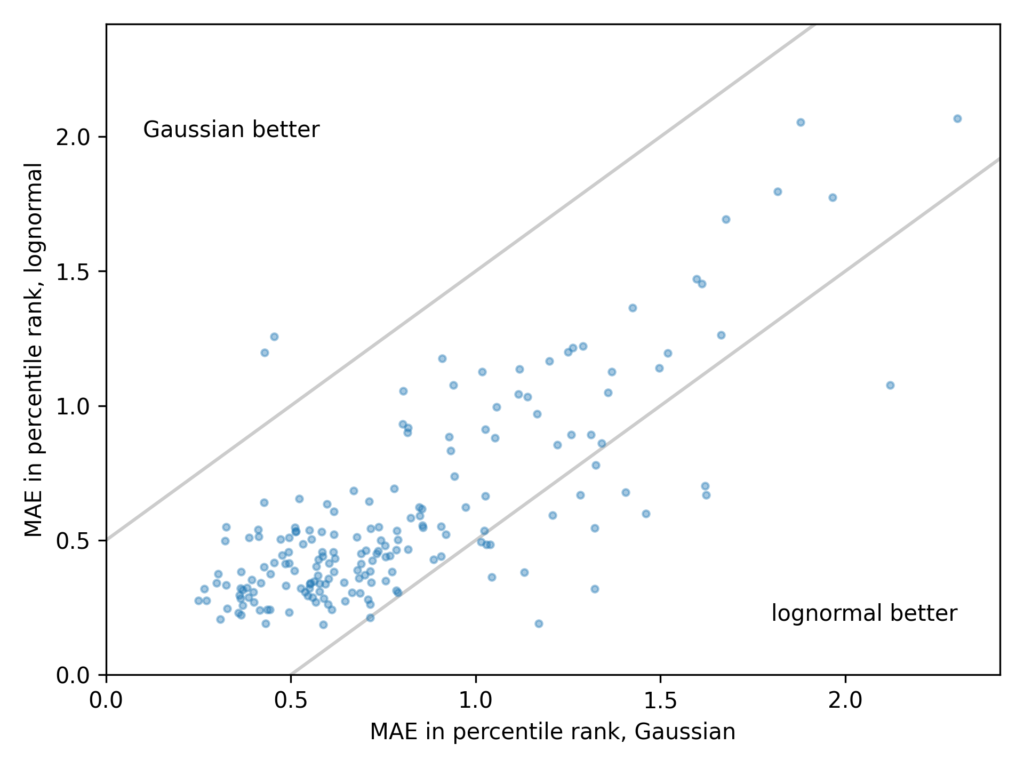
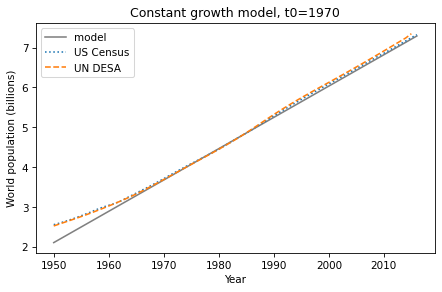
Smoking Causes Cancer
In the preface of Probably Overthinking It, I wrote:
Sometimes interpreting data is easy. For example, one of the reasons we know that smoking causes lung cancer is that when only 20% of the population smoked, 80% of people with lung cancer were smokers. If you are a doctor who treats patients with lung cancer, it does not take long to notice numbers like that.
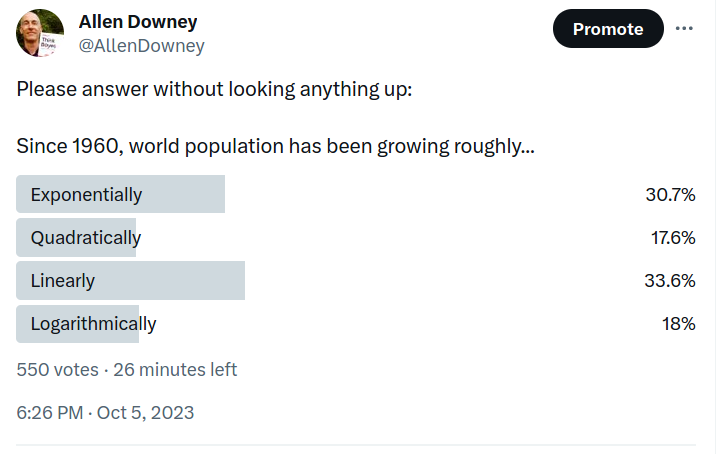
When I re-read that paragraph recently, it occurred to me that interpreting those number might not be as easy as I thought. To find out, I ran a Twitter poll. Here are the results:
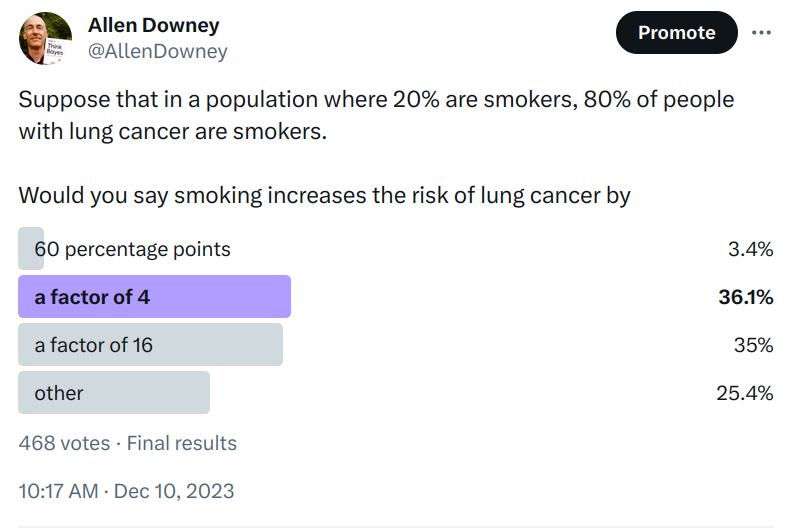
Some of the people who chose “other” said that there is not enough information — we need to know the absolute risk for one or both of the groups.
I think that’s not right — with just these two numbers, we can compute the relative risk of the two groups. There are a few ways to do it, but a good way to get started is to check each of the multiple choice responses.
Off the bat, “60 percentage points” is just wrong. If the lifetime risk of cancer was 20% in one group and 80% in the other, we could describe that difference in terms of percentage points. But those are not the numbers we were given, and the actual risks are much lower.
But “a factor of 4” is at least plausible, so let’s check it. Suppose that the actual lifetime risk of lung cancer for non-smokers is 1% — in that case the risk for smokers would be 4%. In a group of 1000 people, we would expect 800 non-smokers and 8 cases among them, and we would expect 200 smokers and 8 cases among them. Under these assumptions 50% of people with lung cancer would be smokers, but the question says it should be 80%, so this check fails.
Let’s try again with “a factor of 16”. If the risk for non-smokers is 1%, the risk for smokers would be 16%. Among 800 non-smokers, we expect 8 cases again, but among 200 smokers, now we expect 32. Under these assumptions, 80% of people with lung cancer are smokers, so 16 is the correct answer.
Here are the same numbers in a table.
| Number | Risk | Cases | Percent | |
| Non-smoker | 800 | 1% | 8 | 20% |
| Smoker | 200 | 16% | 32 | 80% |
Now, you might object that I chose 1% and 16% arbitrarily, but as it turns out it doesn’t matter. To see why, let’s assume that the risk is x for non-smokers and 16x for smokers. Here’s the table with these unknown risks.
| Number | Risk | Cases | Percent | |
| Non-smoker | 800 | x | 800x | 20% |
| Smoker | 200 | 16x | 3200x | 80% |
The percentage of cases among smokers is 80%, regardless of x.
Now suppose you are not satisfied with this guess-and-check method. We can solve the problem more generally using Bayes’s rule.
- We are given p(smoker) = 20%, which we can convert to odds(smoker) = 1/4.
- And we are given p(smoker | cancer) = 80%, which we can convert to odds(smoker | cancer) = 4.
Applying Bayes’s rule, we have
odds(smoker | cancer) = odds(smoker) * p(cancer | smoker) / p(cancer | non-smoker)
Rearranging terms, we can solve for the risk ratio:
p(cancer | smoker) / p(cancer | non-smoker) = odds(smoker | cancer) / odds(smoker) = 16
That’s the answer I had in mind, but let me address an objection raised by one poll respondent, who chose “Other” because, “You can’t draw casual inferences from observational data without certain assumptions which I’m unwilling to make.”
That’s true. Even if the risk is 16x higher for smokers, that’s not enough to conclude that the entire difference, or any of it, is caused by smoking. It is still possible either:
(1) that the supposed effect is really the cause, or in this case that incipient cancer, or a pre-cancerous condition with chronic inflammation, is a factor in inducing the smoking of cigarettes, or (2) that cigarette smoking and lung cancer, though not mutually causative, are both influenced by a common cause, in this
case the individual genotype.
If you think that’s the stupidest thing you’ve ever heard, you can take it up with Sir Ronald Fisher, who actually made this argument with apparent sincerity in a 1957 letter to the British Medical Journal. I mention this in case you didn’t already know what an ass he was.
However, if we are willing to accept that smoking causes lung cancer, and is in fact responsible for all or nearly all of the increased risk, then we can use the data we have to answer a related question: if a smoker is diagnosed with lung cancer, what is the probability that it was caused by smoking?
To answer that, let’s assume that smokers are exposed at the same rate as non-smokers to causes of cancer other than smoking. In that case, their 16x risk would consist of 15x risk due to smoking and 1x risk due to other causes. So 15/16 cancers among smokers would be due to smoking, which is about 94%.
Some actual numbers
I rounded off the numbers in my example to make the math easy, so let’s see what the actual numbers are. “Smoking and Cancer“, one of the fact sheets published along with “The Health Consequences of Smoking—50 Years of Progress: A Report of the Surgeon General” includes this figure.
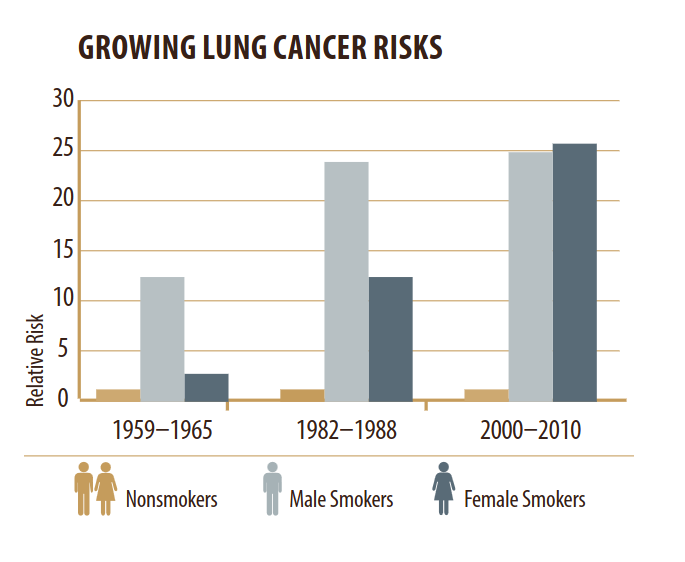
In the most recent interval, the relative risk was about 25x, and at that time about 20% of the U.S. population smoked. The lifetime risk of lung cancer is about 6%, including both smokers and non-smokers, so to find the lifetime risk for non-smokers, we can solve this equation for x:
p(smoker) x + p(non-smoker) (25 x) = 6%
0.8x + 0.2(25x) = 0.06
Which means the lifetime risk is about 1% for non-smokers and 25% for smokers. If we update the table with these numbers, we have
| | Number | Risk | Cases | Percent |
| Non-smoker | 800 | 1% | 8 | 14% |
| Smoker | 200 | 25% | 50 | 86% |
And with that, we can address another point raised by a Twitter friend:
By “smoking increases the risk of lung cancer” you could either mean relative to being a non-smoker or relative to the overall base rate of cancer (including a weighted average of smokers and non-smokers).
I meant the first (which is more common in epidemiology), but if we want the second, it’s about 25 / 6, which is a little more than 4.
Finally, looking at that figure you might wonder why the relative risk of smoking has increased so much. Based on my first pass through the literature, it seems like no one knows. There are at least three possibilities:
- Over this period, cigarettes have been reformulated in ways that might make them more dangerous.
- As the prevalence of smoking has decreased, it’s possible that the number of casual smokers has decreased more quickly, leaving a higher percentage of heavy smokers.
- Or maybe the denominator of the ratio — the risk for non-smokers — has decreased.
In what I’ve read so far, the first explanation seems to get the most attention, but there doesn’t seem to be a clear causal path for it.The second and third explanations seem plausible to me, but I haven’t found the data to support them.
Causes of lung cancer in non-smokers include radon, second-hand smoke, asbestos, heavy metals, diesel exhaust, and air pollution. I would guess that exposure to all of them has decreased substantially since the 1960s. But it seems like we don’t have good evidence that the risk for non-smokers has decreased. That’s surprising, and a possible topic for a future post.