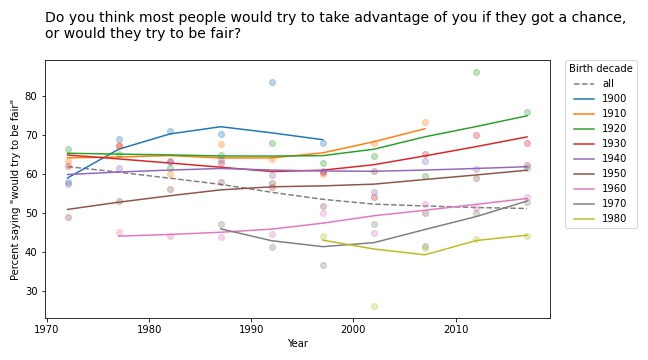
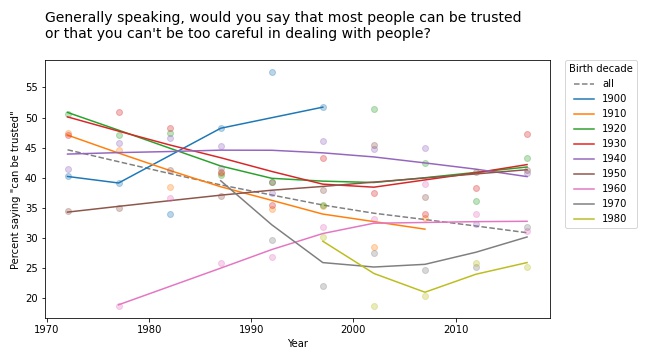
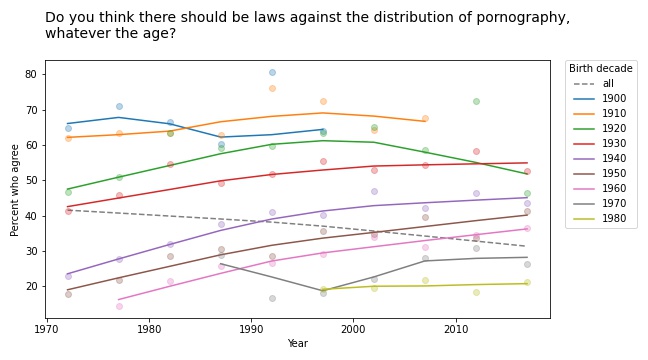
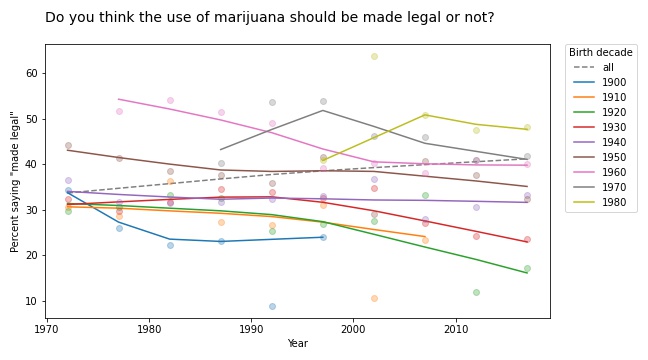
I like Simpson’s paradox so much I wrote three chapters about it in Probably Overthinking It. In fact, I like it so much I have a Google alert that notifies me when someone publishes a new example (or when the horse named Simpson’s Paradox wins a race).
The paper compares death rates due to multiple sclerosis (MS) and amyotrophic lateral sclerosis (ALS) across 50 states and the District of Columbia, and reports a strong correlation.
This result is contrary to all previous work on these diseases – which might be a warning sign. But the author explains that this correlation has not been detected in previous work because it is masked when the analysis combines male and female death rates.
This could make sense, because death rates due to MS are higher for women, and death rates due to ALS are higher for men. So if we compare different groups with different proportions of males and females, it’s possible we could see something like Simpson’s paradox.
But as far as I know, the proportions of men and women are the same in all 50 states, plus the District Columbia – or maybe a little higher in Alaska. So an essential element of Simpson’s paradox – different composition of the subgroups – is missing.
Annoyingly, the “Data Availability” section of the paper only identifies the public sources of the data – it does not provide the processed data. But we can use synthesized data to figure out what’s going on.
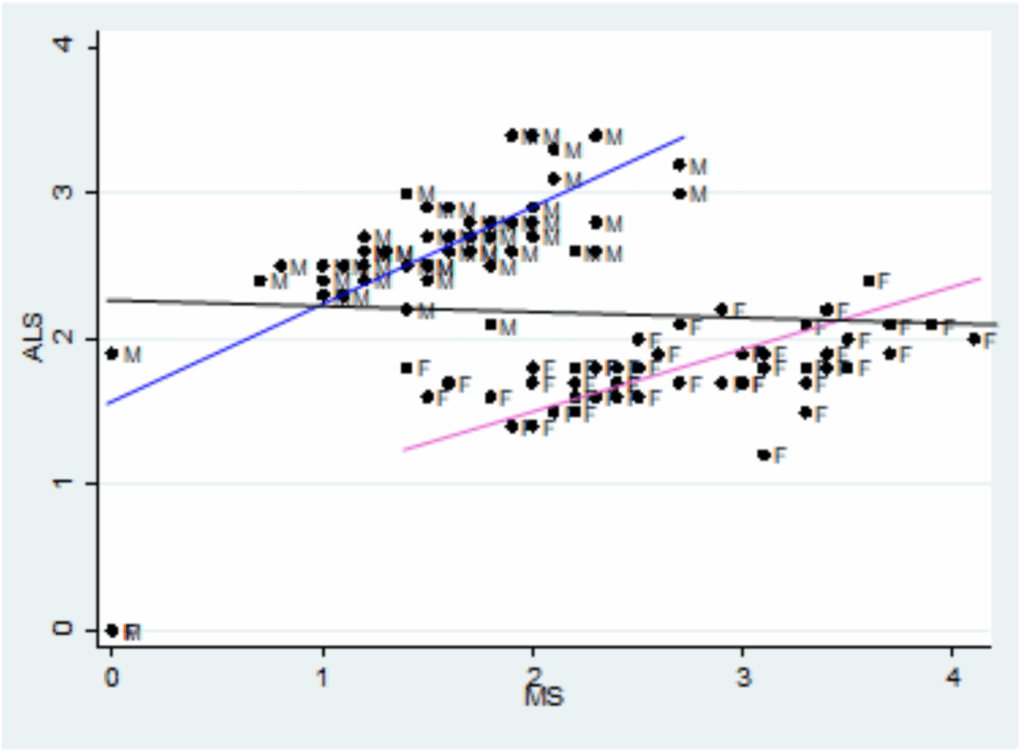
Specifically, let’s try to replicate this key figure from the paper:
The x-axis is age adjusted death rates from MS; the y-axis is age-adjusted death rates from ALS. Each dot corresponds to one gender group in one state. The blue line fits the male data, with correlation 0.7. The pink line fits the female data, with correlation 0.75.
The black line is supposed to be a fit to all the data, showing the non-correlation we supposedly get if we combine the two groups. But I’m pretty sure that line is a mistake.
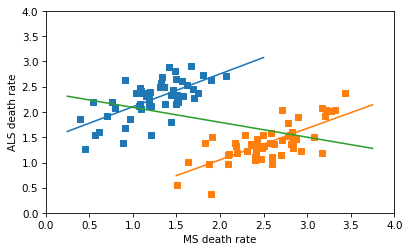
I used a random number generator to synthesize correlated data with the approximate distribution of the date in the figure. The following figure shows a linear regression for the male and female data separately, and a third line that is my attempt to replicate the black line in the original figure.
I thought the author might have combined the dots from the male and female groups into a collection of 102 points, and fit a line to that. That is a nonsensical thing to do, but it does yield a Simpson-like reversal in the slope of the line — and the sign of the correlation.
The line for the combined data has a non-negligible negative slope, and the correlation is about -0.4 – so this is not the line that appears in the original figure, which has a very small correlation. So, I don’t know where that line came from.
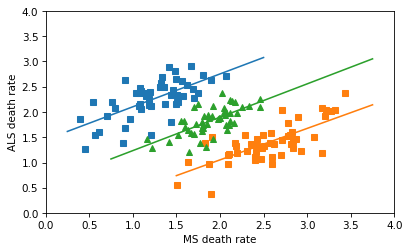
In any case, the correct way to combine the data is not to plot a line through 102 points in the scatter plot, but to fit a line to the combined death rates in the 51 states. Assuming that the gender ratios in the states are close to 50/50, the combined rates are just the means of the male and female rates. The following figure shows what we get if we combine the rates correctly.
So there’s no Simpson’s paradox here – there’s a positive correlation among the subgroups, and there’s a positive correlation when we combine them. I love a good Simpson’s paradox, but this isn’t one of them.
On a quick skim, I think the rest of the paper is also likely to be nonsensical, but I’ll leave that for other people to debunk. Also, peer review is dead.
It gets worse
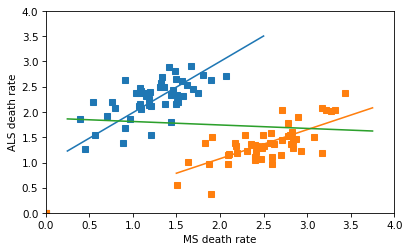
UPDATE: After I published the first draft of this article, I noticed that there are an unknown number of data points at (0, 0) in the original figure. They are probably states with missing data, but if they were included in the analysis as zeros — which they absolutely should not be — that would explain the flat line.
If we assume there are two states with missing data, that strengthens the effect in the subgroups, and weakens the effect in the combined groups. The result is a line with a small negative slope, as in the original paper.
This article is an excerpt from the manuscript of Probably Overthinking It, available from the University of Chicago Press and from Amazon and, if you want to support independent bookstores, from Bookshop.org.
[This excerpt is from a chapter on moral progress. Previous examples explored responses to survey questions related to race and gender.]
The General Social Survey includes four questions related to sexual orientation.
What about sexual relations between two adults of the same sex – do you think it is always wrong, almost always wrong, wrong only sometimes, or not wrong at all?
And what about a man who admits that he is a homosexual? Should such a person be allowed to teach in a college or university, or not?
If some people in your community suggested that a book he wrote in favor of homosexuality should be taken out of your public library, would you favor removing this book, or not?
Suppose this admitted homosexual wanted to make a speech in your community. Should he be allowed to speak, or not?
If the wording of these questions seems dated, remember that they were written around 1970, when one might “admit” to homosexuality, and a large majority thought it was wrong, wrong, or wrong. In general, the GSS avoids changing the wording of questions, because subtle word choices can influence the results. But the price of this consistency is that a phrasing that might have been neutral in 1970 seems loaded today.
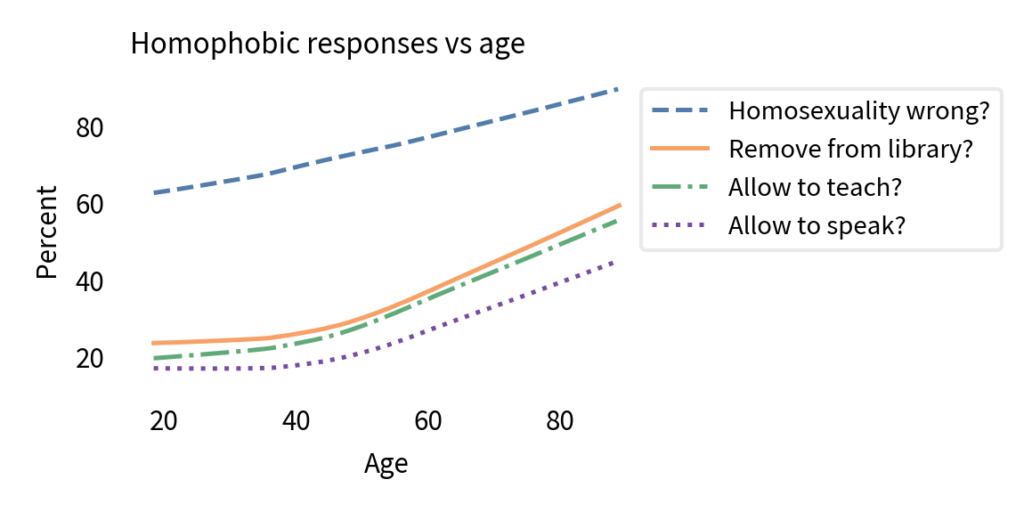
Nevertheless, let’s look at the results. The following figure shows the percentage of people who chose a homophobic response to these questions as a function of age.
It comes as no surprise that older people are more likely to hold homophobic beliefs. But that doesn’t mean people adopt these attitudes as they age. In fact, within every birth cohort, they become less homophobic with age.
The following figure show the results from the first question, showing the percentage of respondents who said homosexuality was wrong (with or without an adverb).
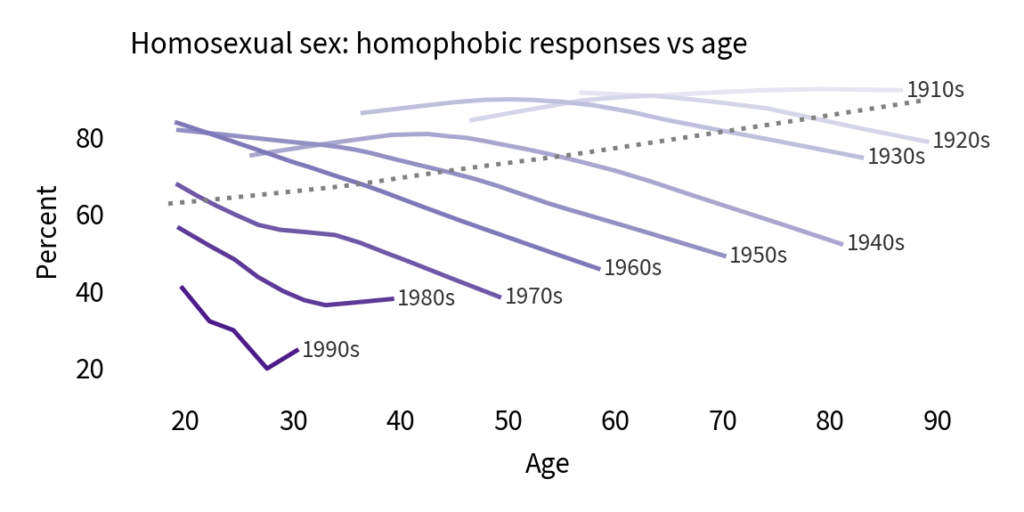
There is clearly a cohort effect: each generation is substantially less homophobic than the one before. And in almost every cohort, homophobia declines with age. But that doesn’t mean there is an age effect; if there were, we would expect to see a change in all cohorts at about the same age. And there’s no sign of that.
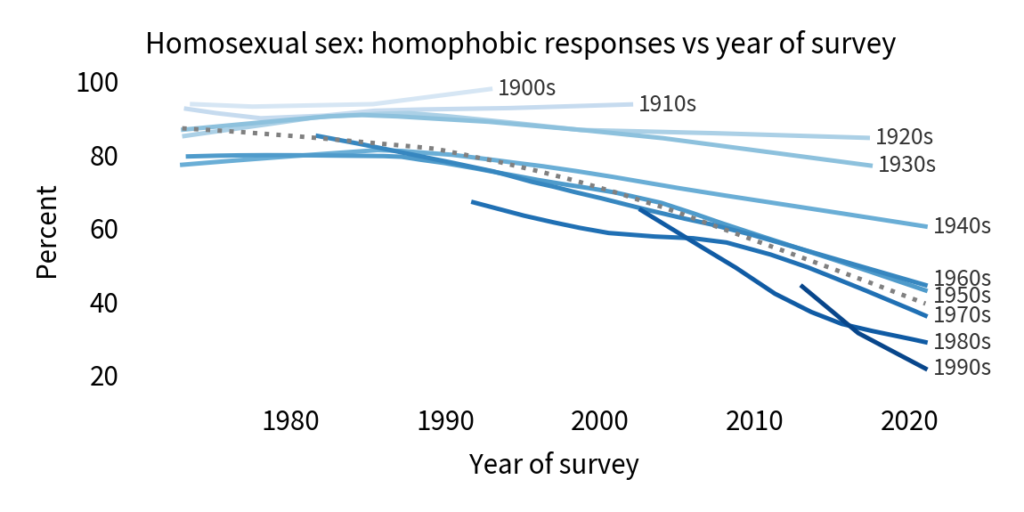
So let’s see if it might be a period effect. The following figure shows the same results plotted over time rather than age.
If there is a period effect, we expect to see an inflection point in all cohorts at the same point in time. And there is some evidence of that. Reading from top to bottom:
More than 90% of people born in the nineteen-oughts and the teens thought homosexuality was wrong, and they went to their graves without changing their minds.
People born in the 1920s and 1930s might have softened their views, slightly, starting around 1990.
Among people born in the 1940s and 1950s, there is a notable inflection point: before 1990, they were almost unchanged; after 1990, they became more tolerant over time.
In the last four cohorts, there is a clear trend over time, but we did not observe these groups sufficiently before 1990 to identify an inflection point.
On the whole, this looks like a period effect. Also, looking at the overall trend, it declined slowly before 1990 and much more quickly thereafter. So we might wonder what happened in 1990.
What happened in 1990?
In general, questions like this are hard to answer. Societal changes are the result of interactions between many causes and effects. But in this case, I think there is an explanation that is at least plausible: advocacy for acceptance of homosexuality has been successful at changing people’s minds.
In 1989, Marshall Kirk and Hunter Madsen published a book called After the Ball with the prophetic subtitle How America Will Conquer Its Fear and Hatred of Gays in the ’90s. The authors, with backgrounds in psychology and advertising, outlined a strategy for changing beliefs about homosexuality, which I will paraphrase in two parts: make homosexuality visible, and make it boring. Toward the first goal, they encouraged people to come out and acknowledge their sexual orientation publicly. Toward the second, they proposed a media campaign to depict homosexuality as ordinary.
Some conservative opponents of gay rights latched onto this book as a textbook of propaganda and the written form of the “gay agenda”. Of course reality was more complicated than that: social change is the result of many people in many places, not a centrally-organized conspiracy.
It’s not clear whether Kirk and Madsen’s book caused America to conquer its fear in the 1990s, but what they proposed turned out to be a remarkable prediction of what happened. Among many milestones, the first National Coming Out Day was celebrated in 1988; the first Gay Pride Day Parade was in 1994 (although previous similar events had used different names); and in 1999, President Bill Clinton proclaimed June as Gay and Lesbian Pride month.
During this time, the number of people who came out to their friends and family grew exponentially, along with the number of openly gay public figures and the representation of gay characters on television and in movies.
And as surveys by the Pew Research Center have shown repeatedly, “familiarity is closely linked to tolerance”. People who have a gay friend or family member – and know it – are substantially more likely to hold positive attitudes about homosexuality and to support gay rights.
All of this adds up to a large period effect that has changed hearts and minds, especially among the most recent birth cohorts.
Cohort or period effect?
Since 1990, attitudes about homosexuality have changed due to
A cohort effect: As old homophobes die, they are replaced by a more tolerant generation.
A period effect: Within most cohorts, people became more tolerant over time.
These effects are additive, so the overall trend is steeper than the trend within the cohorts – like Simpson’s paradox in reverse. But that raises a question: how much of the overall trend is due to the cohort effect, and how much to the period effect?
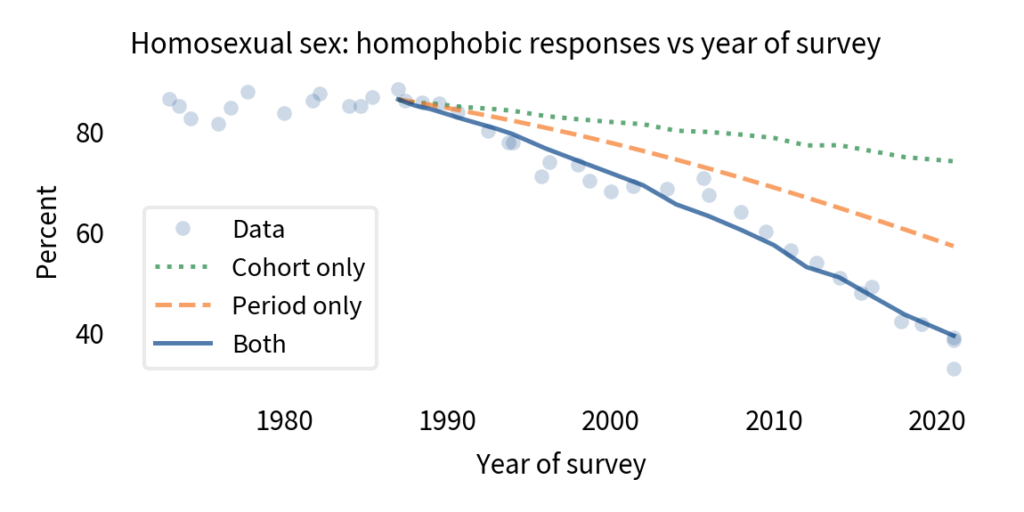
To answer that, I used a model that estimates the contributions of the two effects separately (a logistic regression model, if you want the details). Then I used the model to generate predictions for two counterfactual scenarios: what if there had been no cohort effect, and what if there had been no period effect? The following figure shows the results.
The circles show the actual data. The solid line shows the results from the model from 1987 to 2018, including both effects. The model plots a smooth course through the data, which confirms that it captures the overall trend during this interval. The total change is about 46 percentage points.
The dotted line shows what would have happened, according to the model, if there had been no period effect; the total change due to the cohort effect alone would have been about 12 percentage points.
The dashed line shows what would have happened if there had been no cohort effect; the total change due to the period effect alone would have been about 29 percentage points.
You might notice that the sum of 12 and 29 is only 41, not 46. That’s not an error; in a model like this, we don’t expect percentage points to add up (because it’s linear on a logistic scale, not a percentage scale).
Nevertheless, we can conclude that the magnitude of the period effect is about twice the magnitude of the cohort effect. In other words, most of the change we’ve seen since 1987 has been due to changed minds, with the smaller part due to generational replacement.
No one knows that better than the San Francisco Gay Men’s Chorus. In July 2021, they performed a song by Tim Rosser and Charlie Sohne with the title, “A Message From the Gay Community”. It begins:
To those of you out there who are still working against equal rights, we have a message for you […] You think that we’ll corrupt your kids, if our agenda goes unchecked. Funny, just this once, you’re correct. We’ll convert your children, happens bit by bit; Quietly and subtly, and you will barely notice it.
Of course, the reference to the “gay agenda” is tongue-in-cheek, and the threat to “convert your children” is only scary to someone who thinks (wrongly) that gay people can convert straight people to homosexuality, and believes (wrongly) that having a gay child is bad. For everyone else, it is clearly a joke.
Then the refrain delivers the punchline:
We’ll convert your children; we’ll make them tolerant and fair.
For anyone who still doesn’t get it, later verses explain:
Turning your children into accepting, caring people; We’ll convert your children; someone’s gotta teach them not to hate. Your children will care about fairness and justice for others.
And finally,
Your kids will start converting you; the gay agenda is coming home. We’ll convert your children; and make an ally of you yet.
The thesis of the song is that advocacy can change minds, especially among young people. Those changed minds create an environment where the next generation is more likely to be “tolerant and fair”, and where some older people change their minds, too.
The data show that this thesis is, “just this once, correct”.
Sources
The General Social Survey (GSS) is a project of the independent research organization NORC at the University of Chicago, with principal funding from the National Science Foundation. The data is available from the GSS website.
Is Simpson’s Paradox just a mathematical curiosity, or does it happen in real life? And if it happens, what does it mean? To answer these questions, I’ve been searching for natural examples in data from the General Social Survey (GSS).
A few weeks ago I posted this article, where I group GSS respondents by their decade of birth and plot changes in their opinions over time. Among questions related to faith in humanity, I found several instances of Simpson’s paradox; for example, in every generation, people have become more optimistic over time, but the overall average is going down over time. The reason for this apparent contradiction is generational replacement: as old optimists die, they are being replaced by young pessimists.
In this followup article, I group people by level of education and plot their opinions over time, and again I found several instances of Simpson’s paradox. For example, at every level of education, support for legal abortion has gone down over time (at least under some conditions). But the overall level of support has increased, because over the same period, more people have achieved higher levels of education.
In the most recent article, I group people by decade of birth again, and plot their opinions as a function of age rather than time. I found some of the clearest instances of Simpson’s paradox so far. For example, if we plot support for interracial marriage as a function of age, the trend is downward; older people are less likely to approve. But within every birth cohort, support for interracial marriage increases as a function of age.
With so many examples, we are starting to see a pattern:
Examples of Simpson’s paradox are confusing at first because they violate our expectation that if a trend goes in the same direction in every group, it must go in the same direction when we put the groups together.
But now we realize that this expectation is naive: mathematically, it does not have to be true, and in practice, there are several reasons it can happen, including generational replacement and period effects.
Once explained, the examples we’ve seen so far have turned out not to be very informative. Rather than revealing useful information about the world, it seems like Simpson’s paradox is most often a sign that we are not looking at the data in the most effective way,
But before I give up, I want to give it one more try.
A more systematic search
Each example of Simpson’s paradox involves three variables:
On the x-axis, I’ve put time, age, and a few other continuous variables.
On the y-axis, I’ve put the fraction of people giving the most common response to questions about opinions, attitudes, and world view.
And I have grouped respondents by decade of birth, age, sex, race, religion, and several other demographic variables.
At this point I have tried a few thousand combinations and found about ten clear-cut instances of Simpson’s paradox. So I’ve decided to make a more systematic search. From the GSS data I selected 119 opinion questions that were asked repeatedly over more than a decade, and 12 demographic questions I could sensibly use to group respondents.
With 119 possible variables on the x-axis, the same 119 possibilities on the y-axis, and 12 groupings, there are a 84,118 sensible combinations. When I tested them, 594 produced computational errors of some kind, in most cases because some variables have logical dependencies on others. Among the remaining combinations, I found 19 instances of Simpson’s paradox.
So one conclusion we can reach immediately is that Simpson’s paradox is rare in the wild, at least with data of this kind. But let’s look more closely at the 19 examples.
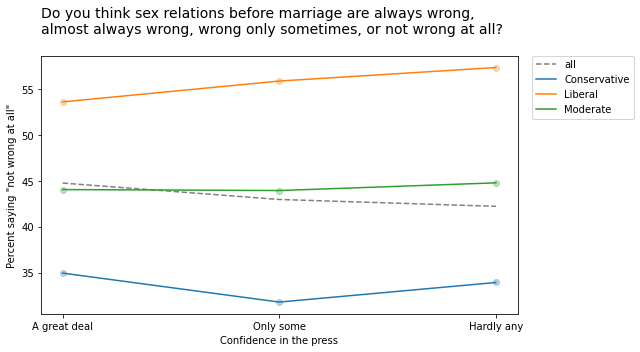
Many of them turn out to be statistical noise. For example, the following figure shows responses to a question about premarital sex on the y-axis, responses to a question about confidence in the press on the x-axis, with respondents grouped by political alignment.
As confidence in the press declines from left to right, the overall fraction of people who think premarital sex is “not wrong at all” declines slightly. But within each political group, there is a slight increase.
Although this example meets the requirements for Simpson’s paradox, it is unlikely to mean much. Most of these relationships are not statistically significant, which means that if the GSS had randomly sampled a different group of people, it is plausible that these trends might have gone the other way.
And this should not be surprising. If there is no relationship between two variables in reality, the actual trend is zero and the trend we see in a random sample is equally likely to be positive or negative. Under this assumption, we can estimate the probability of seeing a Simpson paradox by chance:
If the overall trend is positive, the trend in all three groups has to be negative, which happens one time in eight.
If the overall trend is negative, the trend in all three groups has to be positive, which also happens one time in eight.
When there are more groups, Simpson’s paradox is less likely to happen by chance. Even so, since we tried so many combinations, it is only surprising that we did find more.
A few good examples
Most of the examples I found are like the previous one. The relationships are so weak that the trends we see are mostly random, which means we don’t need a special explanation for Simpson’s paradox. But I found a few examples where the Simpsonian reversal is probably not random and, even better, it makes sense.
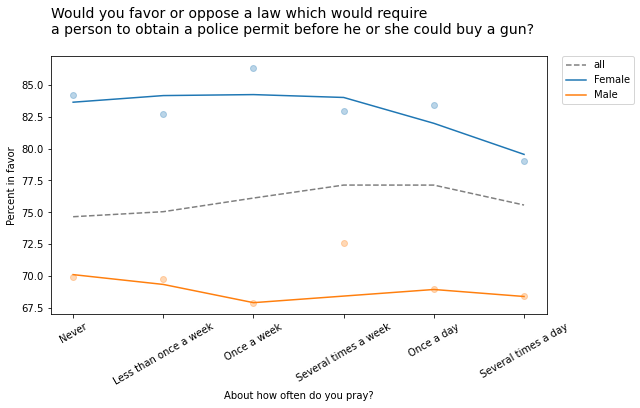
For example, the following figure shows the fraction of people who would support a gun law as a function of how often they pray, grouped by sex.
Within each group, the overall trend is downward: the more you pray, the less likely you are to favor gun control. But the overall trend goes the other way: people who pray more are more likely to support gun control. Before you proceed, see if you can figure out what’s going on.
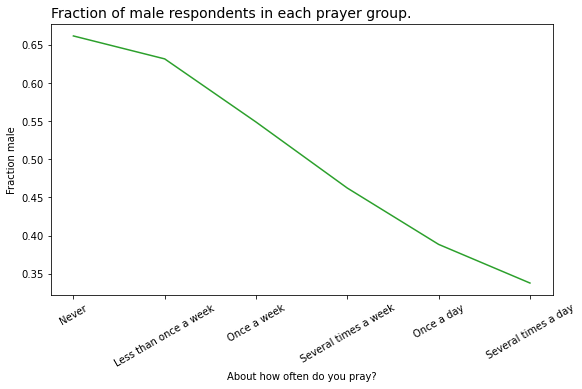
At this point you might guess that there is a correlation of some kind between the variable on the x-axis and the groups. In this example, there is a substantial difference in how much men and women pray. The following figure shows how much:
And that’s why average support for gun control increases as a function of prayer:
The low-prayer groups are mostly male, so average support for gun control is closer to the male response, which is lower.
The high-prayer groups are mostly female, so the overall average is closer to the female response, which is higher.
On one hand, this result is satisfying because we were able to explain something surprising. But having made the effort, I’m not sure we have learned much. Let’s look at one more example.
The GSS includes the following question about a hypothetical open housing law:
Suppose there is a community-wide vote on the general housing issue. There are two possible laws to vote on. One law says that a homeowner can decide for himself whom to sell his house to, even if he prefers not to sell to [someone because of their race or color]. The second law says that a homeowner cannot refuse to sell to someone because of their race or color. Which law would you vote for?
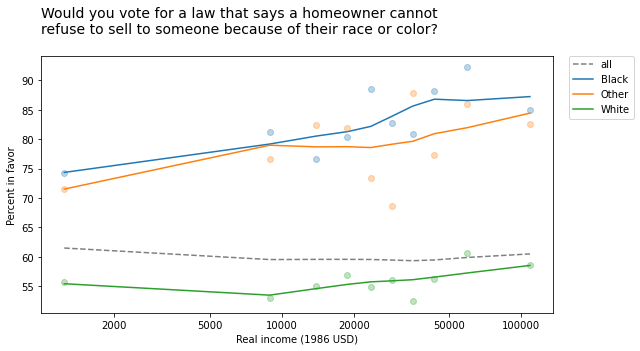
The following figure shows the fraction of people who would vote for the second law, grouped by race and plotted as a function of income (on a log scale).
In every group, support for open housing increases as a function of income, but the overall trend goes the other way: people who make more money are less likely to support open housing.
At this point, you can probably figure out why:
White respondents are less likely to support this law than Black respondents and people of other races, and
People in the higher income groups are more likely to be white.
So the overall average in the lower income groups is closer to the non-white response; the overall average in the higher income groups is closer to the white response.
Summary
Is Simpson’s paradox a mathematical curiosity, or does it happen in real life?
Based on my exploration (and a similar search in a different dataset), if you go looking for Simpson’s paradox in real data, you will find it. But it is rare: I tried almost 100,000 combinations, and found only about 100 examples. And a large majority of the examples I found were just statistical noise.
What does Simpson’s paradox tell us about the data, and about the world?
In the examples I found, Simpson’s paradox doesn’t reveal anything about the world that is useful to know. Mostly it creates confusion, especially for people who have not encountered it before. Sometimes it is satisfying to figure out what’s going on, but if you create confusion and then resolve it, I am not sure you have made net progress. If Simpson’s paradox is useful, it is as a warning that the question you are asking and the way you are looking at the data don’t quite go together.
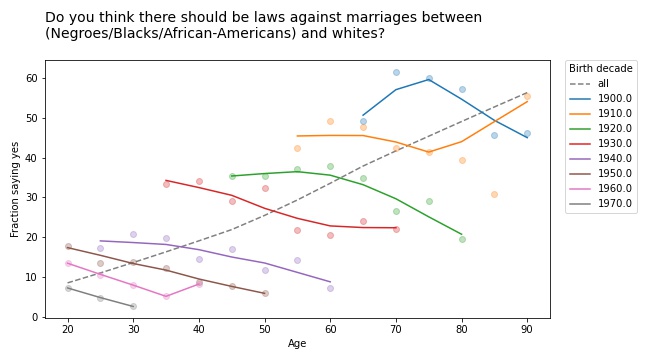
As people get older, do they become more racist, sexist, and homophobic? To find out, you could use data from the General Social Survey (GSS), which asks questions like:
Do you think there should be laws against marriages between Blacks/African-Americans and whites?
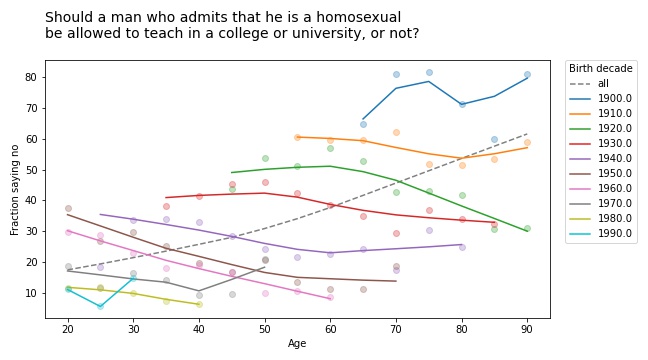
Should a man who admits[mfn]If you find the wording of this question problematic, remember that it was written in 1970 and reflects mainstream views at the time. It persists because, in order to support time series analysis, the GSS generally avoids changing the wording of questions.[/mfn] that he is a homosexual be allowed to teach in a college or university, or not?
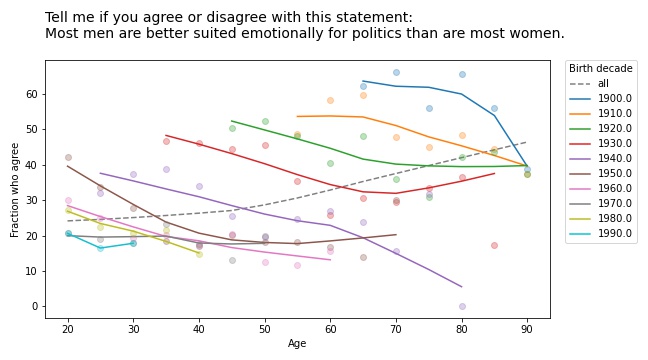
Tell me if you agree or disagree with this statement: Most men are better suited emotionally for politics than are most women.
If you plot the answers to these questions as a function of age, you find that older people are, in fact, more racist, sexist, and homophobic than younger people. But that’s not because they are old; it’s because they were born, raised, and educated during a time when large fractions of the population were racist, sexist homophobes.
In other words, it’s primarily a cohort effect, not an age effect. We can see that if we group respondents by birth cohort and plot their responses by age. Here are the results for the first question:
The circle markers show the proportion of respondents who got this question wrong (no other way to put it); the lines show local regressions through the markers.
The dashed gray line shows the overall trend, if we don’t group by cohort. Sure enough, when this question was asked between 1972 and 2002, older respondents were substantially more likely to support laws against marriage between people of difference races.
But when we group by decade of birth, we see:
A cohort effect: people born later are less racist.
A period effect: within every cohort, people get less racist over time.
The results are similar for the second question:
If you thought the racism was bad, get a load of the homophobia!
But again, all birth cohorts became more tolerant over time (even the people born in the 19-aughts, though it doesn’t look it). And again, there is no age effect; people do not become homophobic as they age.
They don’t get more sexist, either:
Simpson’s Paradox
These are all examples of Simpson’s paradox, where the trend in every group goes in one direction, and the overall trend goes in the other direction. It’s called a paradox because many people find it counterintuitive at first. But once you have seen a few examples, like the ones I wrote about this, this, and this previous article, it gets to be less of a surprise.
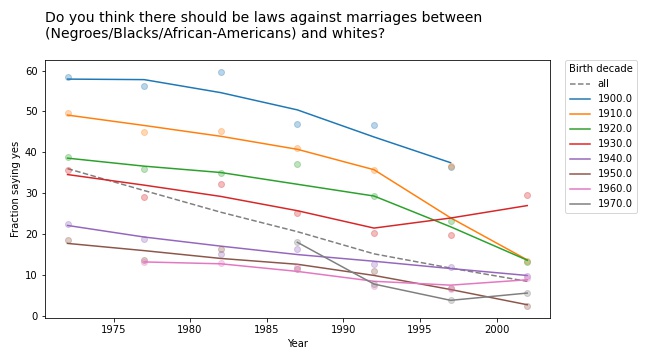
And if you pay attention, it can be a hint that there is something wrong with your model. In this case, it is a symptom that we are looking at the data the wrong way. If we suspect that the changes we see are due to cohort and period, rather than age, we can check by plotting over time, rather than age, like this:
Every cohort is less racist than its predecessor, every cohort gets less racist over time, and the overall trend goes in the same direction, so Simpson’s paradox is resolved.
Or maybe it persists in a weaker form: the overall trend is steeper than the trend in any of the cohorts, because in addition to the cohort effect and the period effect, we also see the effect of generational replacement.
This article is part of a series where I search the GSS for examples of Simpson’s paradox. More coming soon!
Is Simpson’s paradox a mathematical curiosity or something that matters in practice? To answer this question, I’m searching the General Social Survey (GSS) for examples. Last week I published the first batch, examples where we group people by decade of birth and plot their opinions over time. In this article I present the next batch, grouping by education and plotting over time.
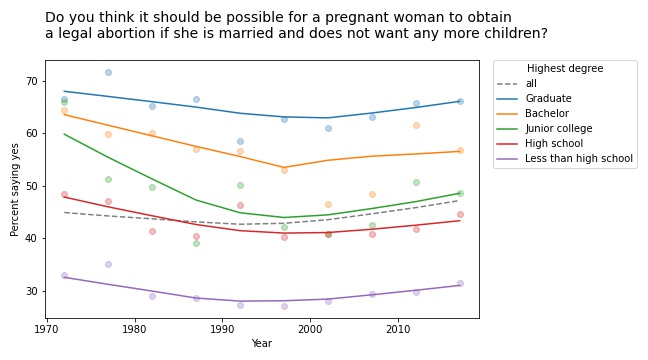
The first example I found is in the responses to this question: “Please tell me whether or not you think it should be possible for a pregnant woman to obtain a legal abortion if she is married and does not want any more children?”
If we group respondents by the highest degree they have earned and compute the fraction who answer “yes” over time, the results meet the criteria for Simpson’s paradox: in every group, the trend over time is downward, but if we put the groups together, the overall trend is upward.
However, if we plot the data, we see that this example is not entirely satisfying.
The markers show the fraction of respondents in each group who answered “yes”; the lines show local regressions through the markers.
In all groups, support for legal abortion (under the specified condition) was decreasing until the 1990s, then started to increase. If we fit a straight line to these curves, the estimated slope is negative. And if we fit a straight line to the overall curve, the estimated slope is positive.
But in both cases, the result doesn’t mean very much because we’re fitting a line to a curve. This is one of many examples I have seen where Simpson’s paradox doesn’t happen because anything interesting is happening in the world; it is just an artifact of a bad model.
This example would have been more interesting in 2002. If we run the same analysis using data from 2002 or earlier, we see a substantial decrease in all groups, and almost no change overall. In that case, the paradox is explained by changes in educational level. Between 1972 and 2002, the fraction of people with a college degree increased substantially. Support for abortion was decreasing in all groups, but more and more people were in the high-support groups.
Free speech
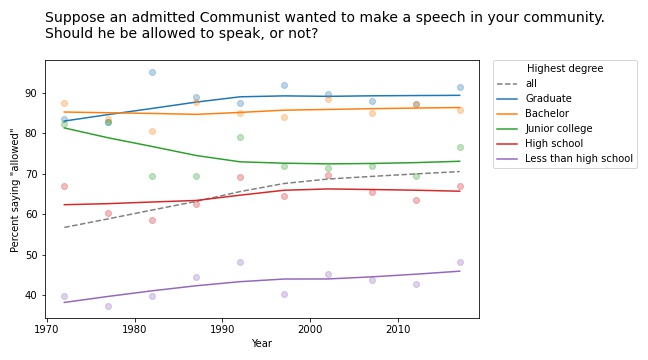
We see a similar pattern in many of the questions related to free speech. For example, the GSS asks, “Suppose an admitted Communist wanted to make a speech in your community. Should he be allowed to speak, or not?” The following figure shows the fraction of respondents at each education level who say “allowed to speak”, plotted over time.
The differences between the groups are big: among people with a bachelor’s or advanced degree, almost 90% would allow an “admitted” Communist to speak; among people without a high school diploma it’s less than 50%. (If you are curious about the wording of questions like this, remember that many GSS questions were written in the 1970s and, for purposes of comparison over time, they avoid changing the text.)
The responses have changed only slightly since 1973: in most groups, support has increased a little; among people with a junior college degree, it has decreased a little.
But overall support has increased substantially, for the same reason as in the previous example: the number of people at higher levels of education increased during this interval.
Whether this is an example of Simpson’s paradox depends on the definition. But it is certainly an example where we see one story if we look at the overall trend and another story if we look at the subgroups.
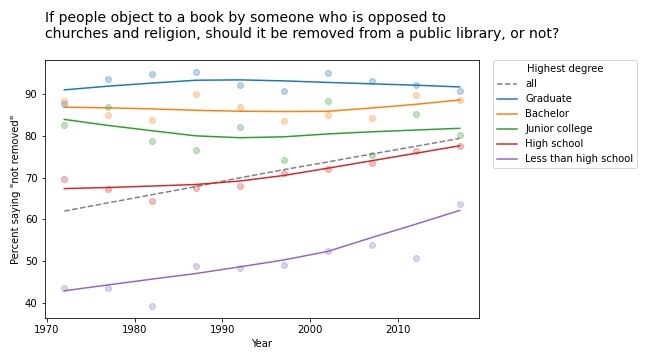
Other questions related to free speech show similar trends. For example, the GSS asks: “There are always some people whose ideas are considered bad or dangerous by other people. For instance, somebody who is against all churches and religion. If some people in your community suggested that a book he wrote against churches and religion should be taken out of your public library, would you favor removing this book, or not?”
The following figure shows the fraction of respondents who say the book should not be removed:
Again, respondents with more education are more likely to support free speech (and probably less hostile to the non-religious, as well). But in this case support is increasing among people with less education. So the overall trend we see is really the sum of two trends: increases within some groups in addition to shifts between groups.
In this example, the overall slope is steeper than the estimated slope in any group. That would be surprising if you expected the overall slope to be like a weighted average of the group slopes. But as all of these examples show, it’s not.
This article presents examples of Simpson’s paradox, and related patterns, when we group people by education level and plot their responses over time. In the next article we’ll see what happens when we groups people by age.
Years ago I told one of my colleagues about my Data Science class and he asked if I taught Simpson’s paradox. I said I didn’t spend much time on it because, I opined, it is a mathematical curiosity unlikely to come up in practice. My colleague was shocked and dismayed because, he said, it comes up all the time in his field (psychology).
And that got me thinking about my old friend, the General Social Survey (GSS). So I’ve started searching the GSS for instances of Simpson’s paradox. I’ll report what I find, and maybe we can get a sense of (1) how often it happens, (2) whether it matters, and (3) what to do about it.
I’ll start with examples where the x-variable is time. For y-variables, I use about 120 questions from the GSS. And for subgroups, I use race, sex, political alignment (liberal-conservative), political party (Democrat-Republican), religion, age, birth cohort, social class, and education level. That’s about 1000 combinations.
Of these, about 10 meet the strict criteria for Simpson’s paradox, where the trend in all subgroups goes in the same direction and the overall trend goes in the other direction. On examination, most of them are not very interesting. In most cases, the actual trend is nonlinear, so the parameters of the linear model don’t mean very much.
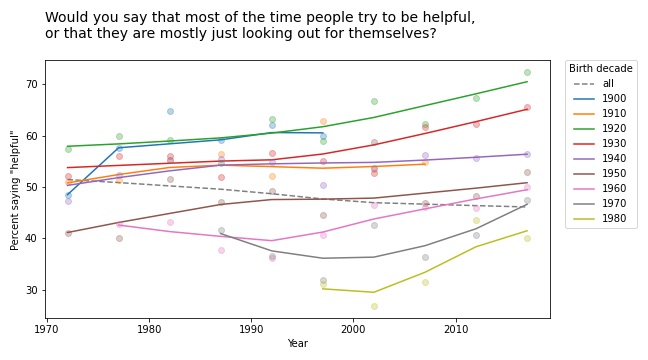
But a few of them turn out to be interesting, at least to me. For example, the following figure shows the fraction of respondents who think “most of the time people try to be helpful”, plotted over time, grouped by decade of birth. The markers show the percentage in each group during each interval; the lines show local regressions.
Within each group, the trend is positive: apparently, people get more optimistic about human nature as they age. But overall the trend is negative. Why? Because of generational replacement. People born before 1940 are substantially more optimistic than people born later; as old optimists die, they are being replaced by young pessimists.
Based on this example, we can go looking for similar patterns in other variables. For example, here are the results from a related question about fairness.
Again, old optimists are being replaced by young pessimists.
For a similar question about trust, the results are a little more chaotic:
Some groups are going up and others down, so this example doesn’t meet the criteria for Simpson’s paradox. But it shows the same pattern of generational replacement.
Old conservatives, young liberals
Questions related to prohibition show similar patterns. For example, here are the responses to a question about whether pornography should be illegal.
In almost every group, support for banning pornography has increased over time. But recent generations are substantially more tolerant on this point, so overall support for prohibition is decreasing.
The results for legalizing marijuana are similar.
In most groups, support for legalization has gone down over time; nevertheless, through the power of generational replacement, overall support is increasing.
So far, I think this is more interesting than Derek Jeter’s batting average. More examples coming soon!
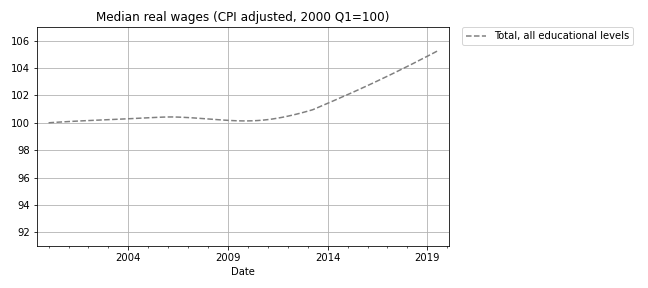
I have good news and bad news. First the good news: after a decade of stagnation, real wages have been rising since 2010. The following figure shows weekly wages for full-time employees (source), which I adjusted for inflation and indexed so the series starts at 100.
Real wages in 2019 Q3 were about 5% higher than in 2010.
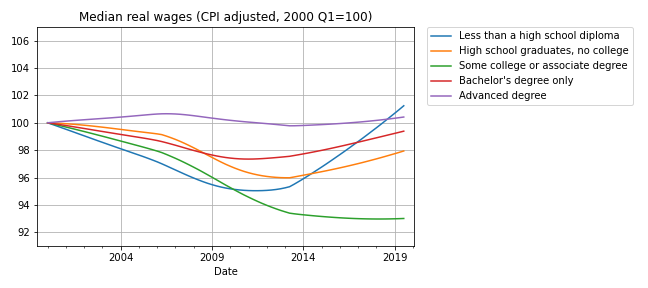
Now here’s the bad news: at every level of education, real wages are lower now than in 2000, or practically the same. The following figure shows real weekly wages grouped by educational attainment:
For people with some college or an associate degree, real wages have fallen by about 5% since 2000 Q1. People with a high school diploma or a bachelor’s degree are making less money, too. People with advanced degrees are making about the same, and high school dropouts are doing slightly better.
But the net change for every group is substantially less than the 5% increase we see if we put the groups together. How is that even possible?
The answer is Simpson’s paradox, which is when a trend appears in every subgroup, but “disappears or reverses when these groups are combined”. In this case, real wages are declining or stagnant in every subgroup, but when we put the groups together, wages are increasing.
In general, Simpson’s paradox can happen when there is a confounding variable that interacts with the variables you are looking at. In this example, the variables we’re looking at are real wages, education level, and time. So here’s my question: what is the confounding variable that explains these seemingly impossible results?
Before you read the next section, give yourself time to think about it.
Credit: I got this example from a 2013 article by Floyd Norris, who was the chief financial correspondent of The New York Times at the time. He responded very helpfully to my request for help replicating his analysis.
The answer
The key (as Norris explained) is that the fraction of people in each educational level has changed. I don’t have the number from the BLS, but we can approximate them with data from the General Social Survey (GSS). It’s not exactly the same because:
The GSS represents the adult residents of the U.S.; the BLS sample includes only people employed full time.
The GSS data includes number of years of school, so I used that to approximate the educational levels in the BLS dataset. For example, I assume that someone with 12 years of school has a high school diploma, someone with 16 years of school has a bachelor’s degree, etc.
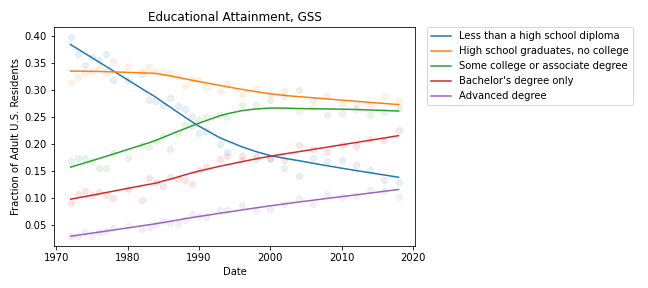
With those caveats, the following figure shows the fraction of GSS respondents in each educational level, from 1973 to 2018:
During the relevant period (from 2000 to 2018), the fraction of people with bachelor’s and advanced degrees increased substantially, and the fraction of high school dropouts declined.
These changes are the primary reason for the increase in median real wages when we put all educational levels together. Here’s one way to think about it:
If you compare two people with the same educational level, one in 2000 and one in 2018, the one in 2018 is probably making less money, in real terms.
But if you compare two people, chosen at random, one in 2000 and one in 2018, the one in 2018 is probably making more money, because the one in 2018 probably has more education.
These changes in educational attainment might explain the paradox, but the explanation raises another question: The same changes were happening between 2000 and 2010, so why were real wages flat during that interval?
I’m not sure I know the answer, but it looks like wages at each level were falling more steeply between 2000 and 2010; after that, some of them started to recover. So maybe the decreases within educational levels were canceled out by the shifts between levels, with a net change close to zero.
And there’s one more question that nags me: Why are real wages increasing for people with less than a high school diploma? With all the news stories about automation and the gig economy, I expected people in this group to see decreasing wages.
The resolution of this puzzle might be yet another statistical pitfall: survivorship bias. The BLS dataset reports median wages for people who are employed full-time. So if people in the bottom half of the wage distribution lose their jobs, or shift to part-time work, the median of the survivors goes up.
And that raises one final question: Are real wages going up or not?