In 2019 I presented a talk at SciPy where I showed that support for gun control has been declining in the U.S. since about 1999. And, contrary to what many people believe, it is lowest among millennials and Gen Z.
Those results were based on data from the General Social Survey up to 2018. Now that the data from 2021 is available, I’ve run the same analysis and I can report:
Support for gun control has continued to decline, and
Among young adults it has reached a new low.
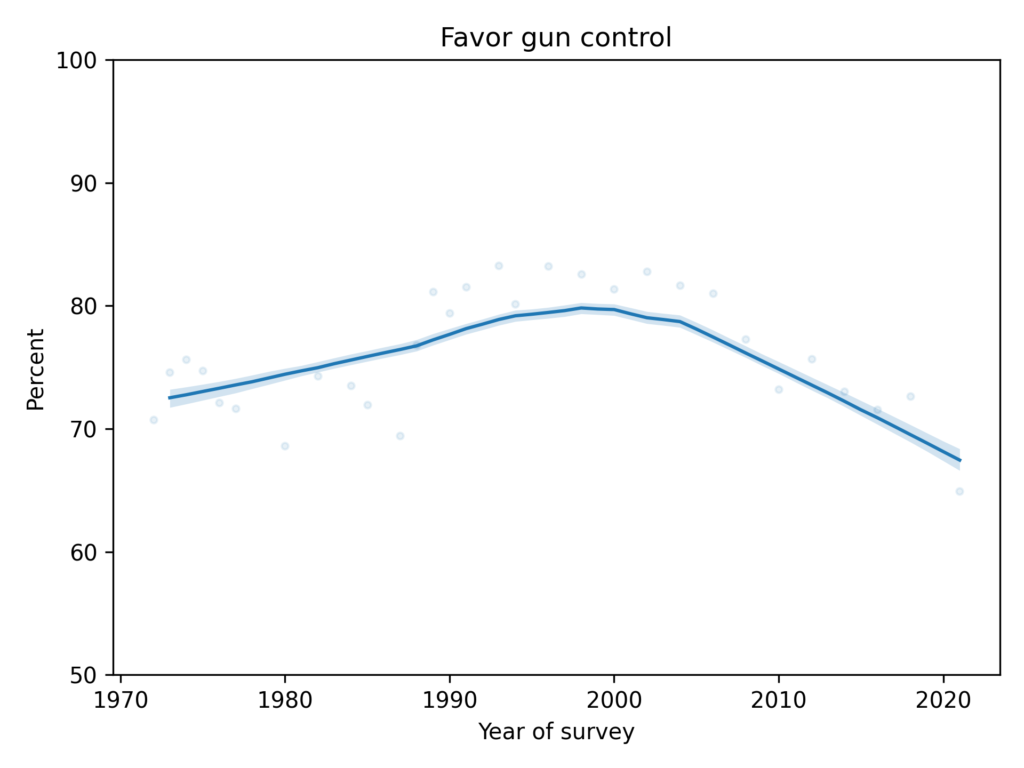
The following figure shows the fraction of GSS respondents who said that they would favor “a law which would require a person to obtain a police permit before he or she could buy a gun.”
Support for this form of gun control increased between 1972 and 1999, and has been decreasing ever since.
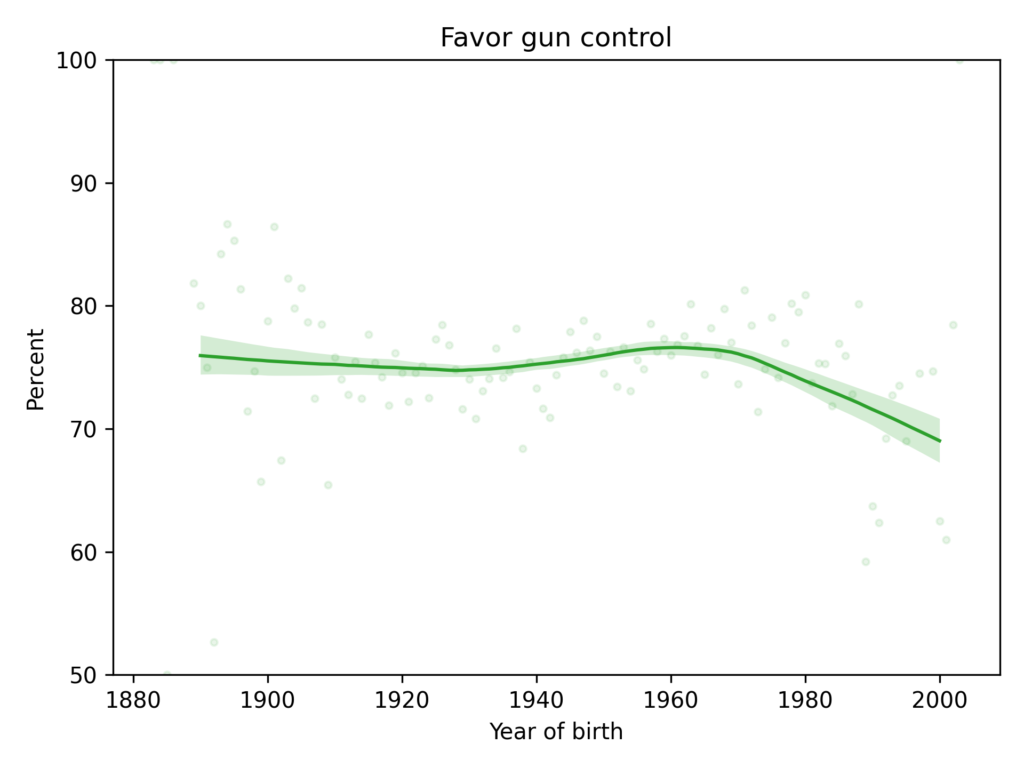
The following figure shows the results from the same question plotted over year of birth.
People born between 1890 and 1970 supported gun control at about the same level. More recent generations — including millennials and Gen Z — are substantially less likely to support gun control.
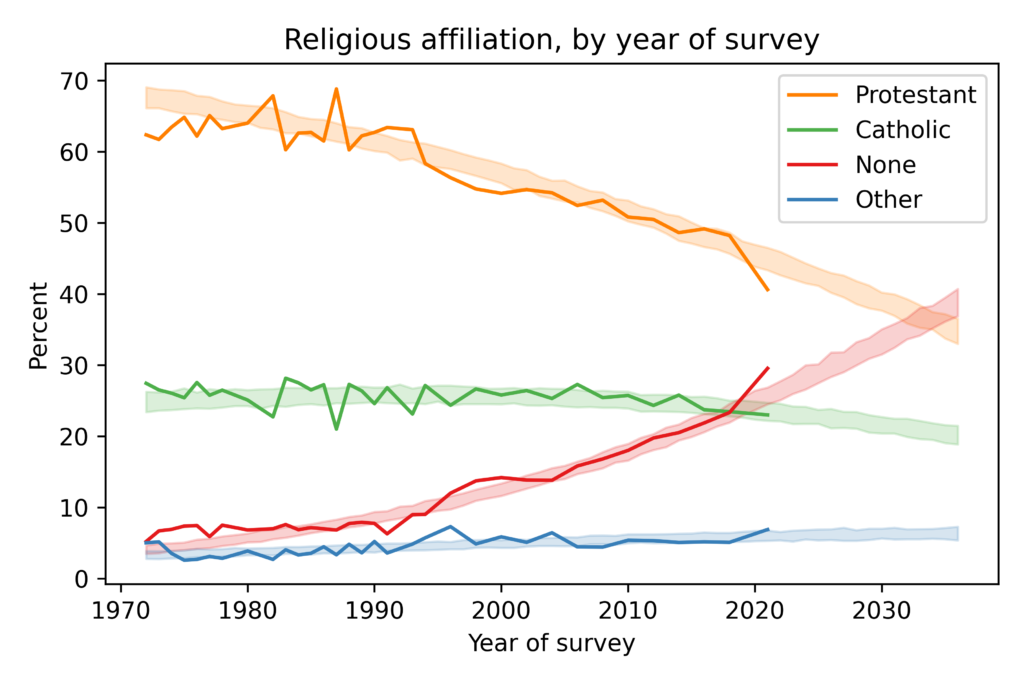
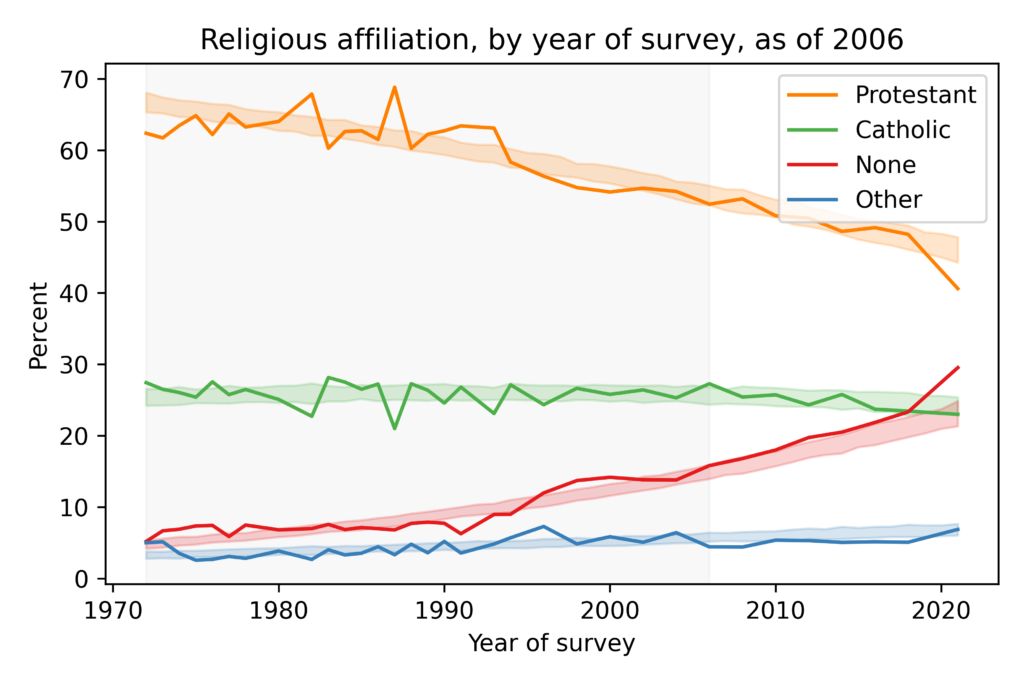
In this figure, the solid lines show estimated proportions of each religious affiliation from 1972 to 2021. Since the early 1990s, the proportion of Protestants has been declining and the proportion of people with no religious affiliation has been increasing. Catholicism has declined slightly and other religions have increased slightly.
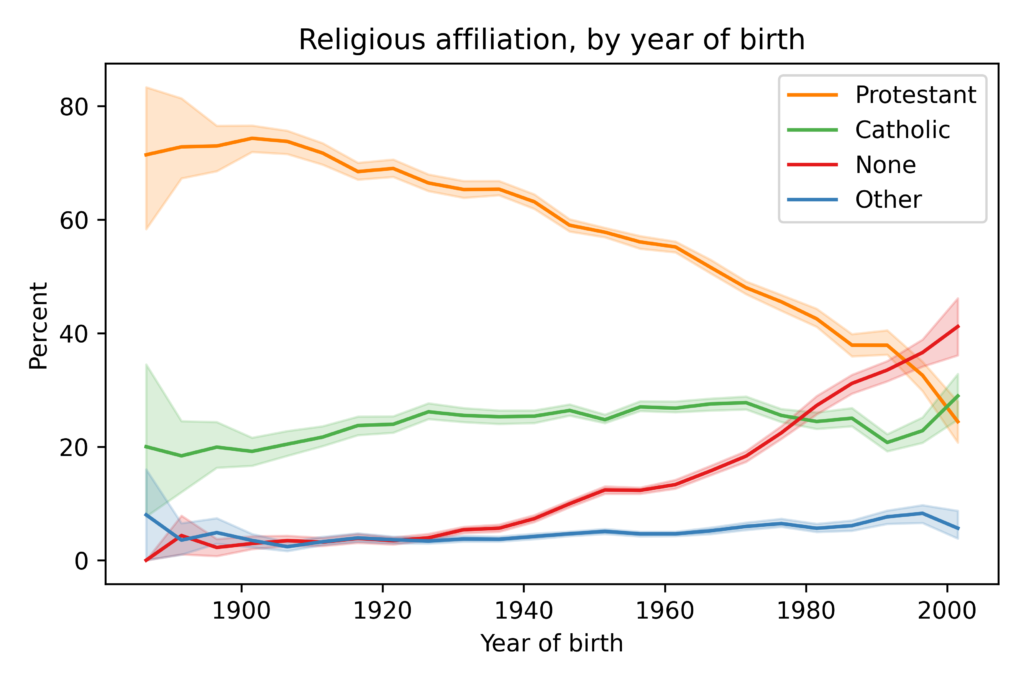
The shaded areas show results from a model I used to fit past data and forecast future changes. The model predicts that “Nones” will overtake Protestants in the 2030s. The primary cause of these changes is generational replacement: as older people die, they are replaced by young people who are less likely to be religious. The following figure shows the proportion of each religious tradition as a function of year of birth:
Among people born around 1900, nearly all were Protestant or Catholic; few belonged to another religion or none. Among people born around 2000, the plurality have no religious affiliation; Protestants and Catholics are statistically tied for second.
In general, forecasting social phenomena is hard because things change. However, generational replacement is relatively predictable. To see how predictable, let’s see what would have happened if we used the same method to generate predictions 15 years ago:
Predictions made in 2006 (using only the data in the shaded area) would have been pretty good. We would have underestimated the growth of the Nones, but the predictions for the other groups would have been accurate. So we have reason to think 15-year predictions based on current data are reliable.
If you want details, the model is multinomial logistic regression using two features: year of birth and year of survey. It is based on the assumption that (1) the distribution of ages will not change substantially over the next 15 years, and (2) most people don’t change religious affiliation as adults, or if they do, the resulting net flow between affiliations is small.
I have news. I finished the last two chapters of Probably Overthinking It last week and sent a complete draft of the book off for technical review. Yay!
In the last chapter, I used some methodology I thought was worth reporting, but too technical for the book, which is intended for an intelligent general audience. So I’ve started a public site for the book, where I will post technical details from each chapter and maybe some of the material that I decided to cut.
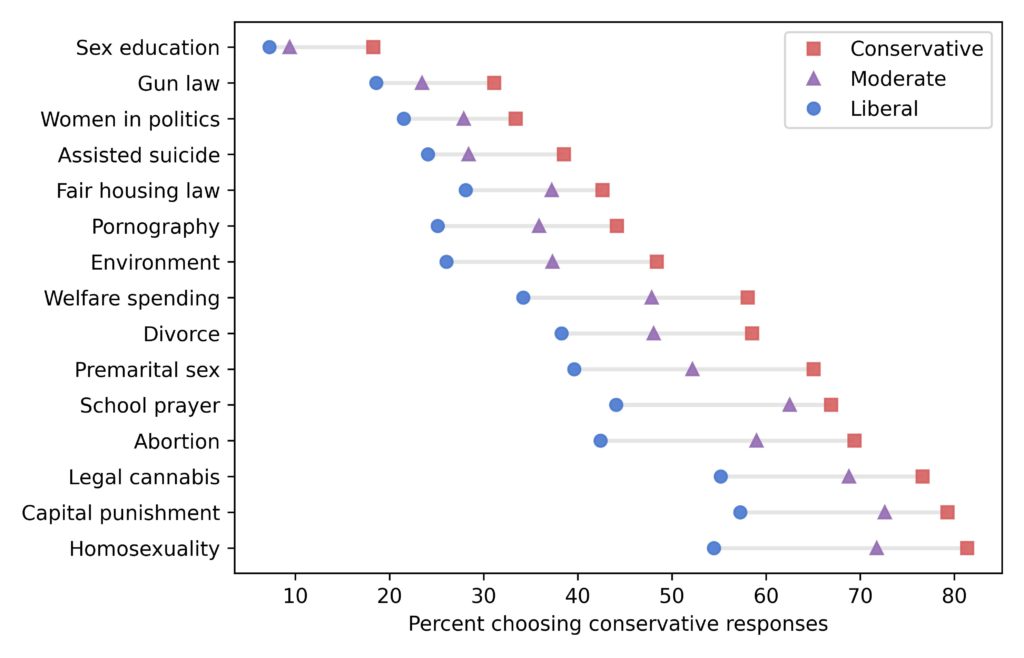
The last chapter is about changes in political beliefs over the last 50 years, particularly along the axis of liberal and conservative views. I found 15 questions in the General Social Survey (GSS) where liberals and conservatives give different answers by the widest margin. The following figure shows the topics, which will come as no surprise, and the differences between the groups.
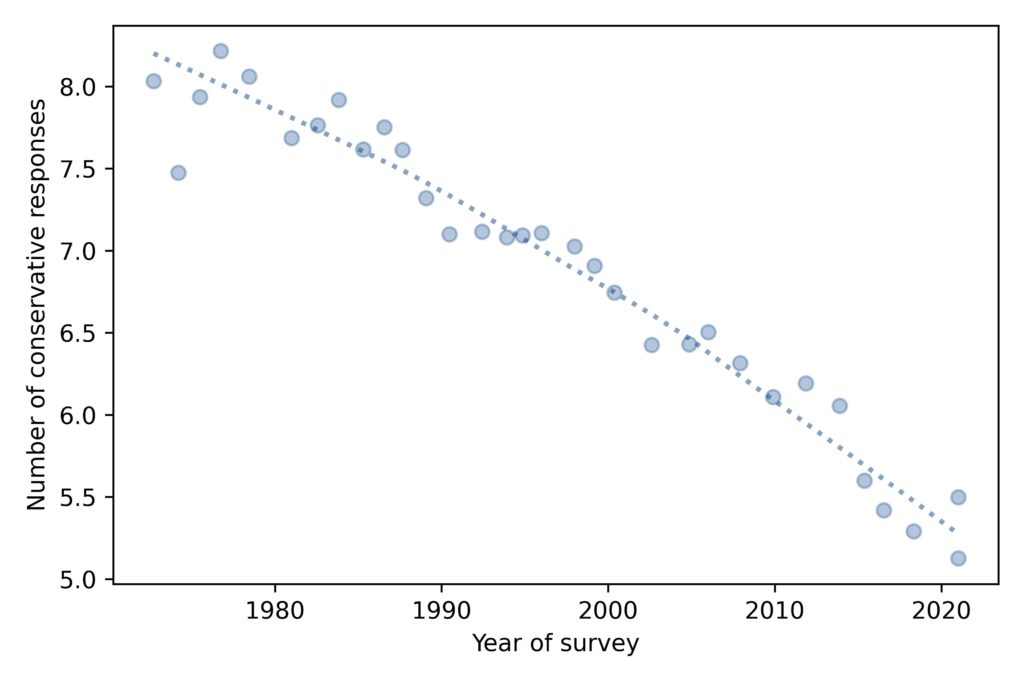
Based on the answers to these questions, I estimate a score for each respondent that quantifies how conservative their beliefs are. By this measure, people have been getting more liberal, pretty consistently, for the last 50 years:
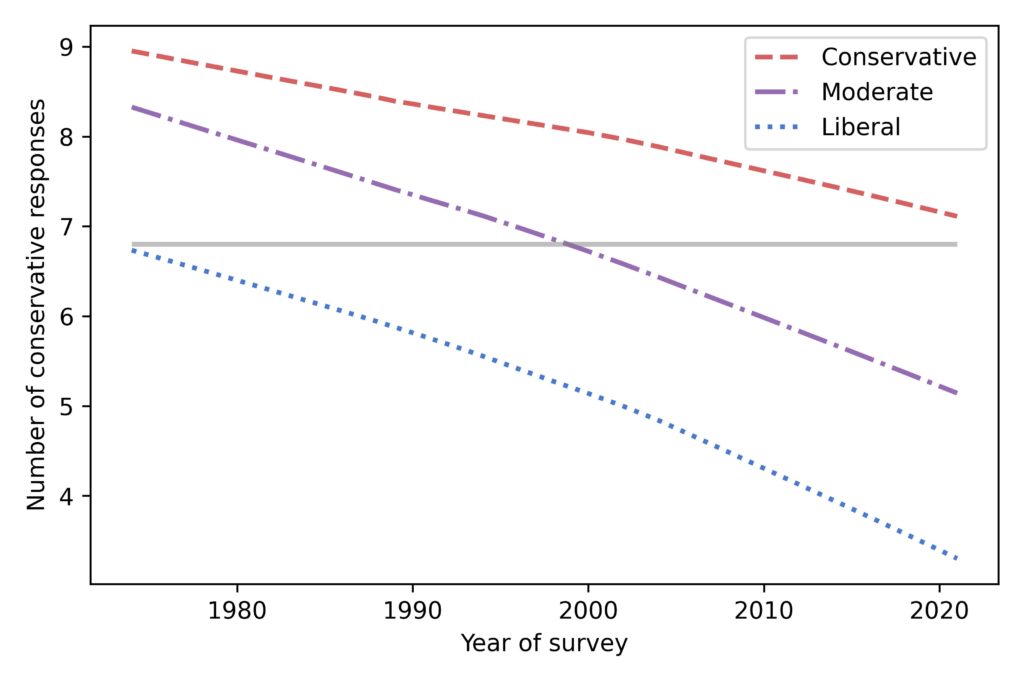
And it’s not just liberals becoming more liberal. People who consider themselves conservative are more liberal than they used to be, too.
That gray line is at 6.8 conservative responses, which was the expected level in 1974 among people who called themselves liberal.
Now, suppose you take a time machine back to 1974, find an average liberal, and bring them to the turn of the millennium. Based on their survey responses, they would be indistinguishable from the average moderate in 2000.
And if you bring them to 2021, their quaint 1970s liberalism would be almost as far to the right as the average conservative.
I thought I would be done this week, but it looks like there will be one more chapter. If you don’t know, I am working on a book that includes updated articles from this blog, plus new examples, and pulls the whole thing together. So far, it’s going well. I have consistently finished one chapter per month and I am almost done.
The problem is that several times a chapter has mitosed (it’s a word) into multiple chapters. In the most extreme case, the material I thought would be one chapter turned into four, and I think I’m going to cut one of them.
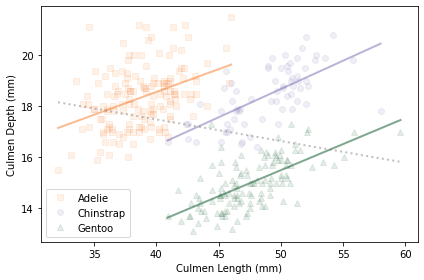
Most recently, what I thought was the last chapter has turned into two. The first is about Simpson’s paradox, including this mandatory example from the ubiquitous penguin dataset:
The new chapter is about Overton’s window. Fortunately, before the mitosis, I had written a substantial chunk of it, so I think I can finish it in less than a month.
Until then, if you would like to get infrequent email announcements about the book, please sign up below. I’ll let you know about milestones, promotions, and other news, but not more than one email per month. I will not share your email or use this list for any other purpose.
This article is an excerpt from my book Probably Overthinking It, to be published by the University of Chicago Press in early 2023. This book is intended for a general audience, so I explain some things that might be familiar to readers of this blog – and I leave out the Python code. After the book is published, I will post the Jupyter notebooks with all of the details! If you would like to receive infrequent notifications about the book (and possibly a discount), please sign up for this mailing list.
Suppose you are the ruler of a small country where the population is growing quickly. Your advisers warn you that unless growth slows down, the population will exceed the capacity of the farms and the peasants will starve.
The Royal Demographer informs you that the average family size is currently 3; that is, each woman in the kingdom bears three children, on average. He explains that the replacement level is close to 2, so if family sizes decrease by one, the population will stabilize at a sustainable size.
One of your advisors asks: “What if we make a new law that says every woman has to have fewer children than her mother?”
It sounds promising. As a benevolent despot, you are reluctant to restrict your subjects’ reproductive freedom, but it seems like such a policy could be effective at reducing family size with minimal imposition.
“Make it so,” you say.
Twenty-five years later, you summon the Royal Demographer to find out how things are going.
“Your Highness,” they say, “I have good news and bad news. The good news is that adherence to the new law has been perfect. Since it was put into effect, every woman in the kingdom has had fewer children than her mother.”
“That’s amazing,” you say. “What’s the bad news?”
“The bad news is that the average family size has increased from 3.0 to 3.3, so the population is growing faster than before, and we are running out of food.”
“How is that possible?” you ask. “If every woman has fewer children than her mother, family sizes have to get smaller, and population growth has to slow down.”
Actually, that’s not true.
In 1976, Samuel Preston, a demographer at the University of Washington, published a description of this apparent paradox: “A major intergenerational change at the individual level is required in order to maintain intergenerational stability at the aggregate level.”
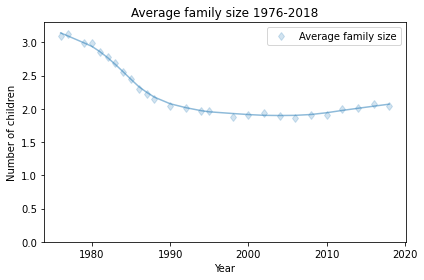
To make sense of this, I’ll use the distribution of fertility in the United States (rather than your imaginary island). Every other year, the Census Bureau surveys a representative sample women in the United States and asks, among other things, how many children they have ever born. To measure completed family sizes, they select women aged 40-44 (of course, some women have children in their forties, so these estimates might be a little low).
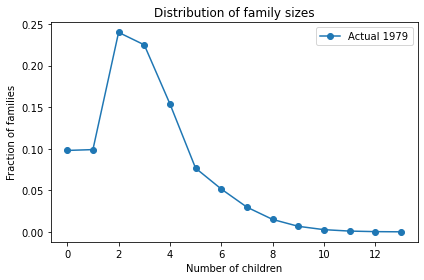
I used the data from 1979 to estimate the distribution of family sizes at the time of Preston’s paper. Here’s what it looks like.
The average total fertility was close to 3. Starting from this distribution, what would happen if every woman had the same number of children as her mother? A woman with 1 child would have only one grandchild; a woman with 2 children would have 4 grandchildren; a woman with 3 children would have 9 grandchildren, and so on. In the next generation, there would be more big families and fewer small families.
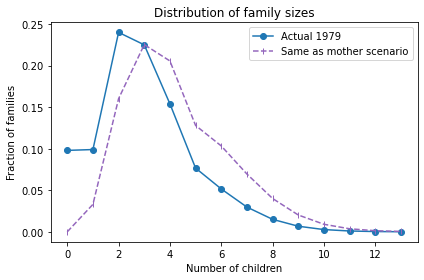
Here’s what the distribution would look like in this “Same as mother” scenario.
The net effect is to shift the distribution to the right. If this continues, family sizes would increase quickly and population growth would explode.
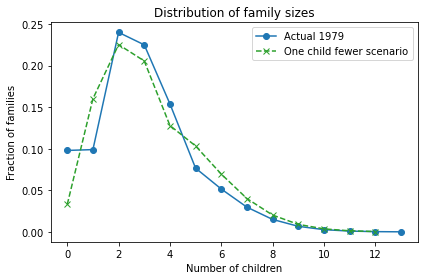
So what happens in the “One child fewer” scenario? Here’s what the distribution looks like:
Bigger families are still overrepresented, but not as much as in the “Same as mother” scenario. The net effect is an increase is average fertility from 3 to 3.3.
As Preston explained, “under current [1976] patterns a woman would have to bear an average of almost two children fewer than … her mother merely to keep population fertility rates constant from generation to generation”. One child fewer was not enough!
As it turned out, the next generation in the U.S. had 2.3 fewer children than their mothers, on average, which caused a steep decline in average fertility:
Average fertility in the U.S. has been close to 2 since about 1990, although it might have increased in the last few years (keeping in mind that the women interviewed in 2018 had most of their children 10-20 years earlier).
Preston concludes, “Those who exhibit the most traditional behavior with respect to marriage and women’s roles will always be overrepresented as parents of the next generation, and a perpetual disaffiliation from their model by offspring is required in order to avert an increase in traditionalism for the population as a whole.”
So, if you have fewer children than your parents, don’t let anyone say you are selfish; you are doing your part to avert population explosion!
My thanks to Prof. Preston for comments on a previous version of this article.
If you would like to get infrequent email announcements about my book, please sign up below. I’ll let you know about milestones, promotions, and other news, but not more than one email per month. I will not share your email or use this list for any other purpose.
As I’ve mentioned, I’m working on a book called Probably Overthinking It, to be published in early 2023. It’s intended for a general audience, so I’m not trying to do research, but I might have found something novel while working on a chapter about power law distributions.
If you are familiar with the topic, you know that there are a bunch of distributions in natural and engineered systems that seem to follow a power law. But ever since people have claimed to find power law distributions, other people have said, “Not so fast”. There are two persistent problems with power law distributions:
They generally don’t fit the left part of the distribution, only the tail.
They don’t fit the whole tail; in the extreme, the data usually drop off faster than a real power law.
On the other hand, a lognormal distribution often fits the left part of these distributions, but it’s not always good model for the tail.
Well, what if there was another simple, well-known model that fits the entire distribution? I think there is, at least for some datasets: the Student-t distribution.
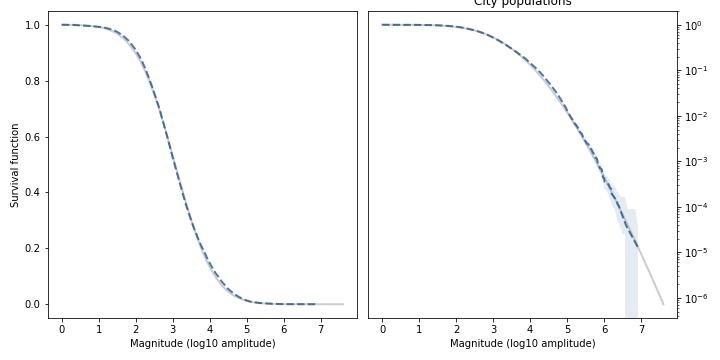
For example, here’s the distribution of city sizes in the U.S. from the 2020 Census. On the left is the survival function (complementary CDF), with city size on a log scale. On the right is the survival function again, with the y-axis also on a log scale.
The dashed line is the data; the shaded area is a 90% CI based on the data; and the gray line is the model, with parameters chosen to match the data. On the left, the Student-t model fits the data over the entire range; on the right, it also fits the tail over five orders of magnitude.
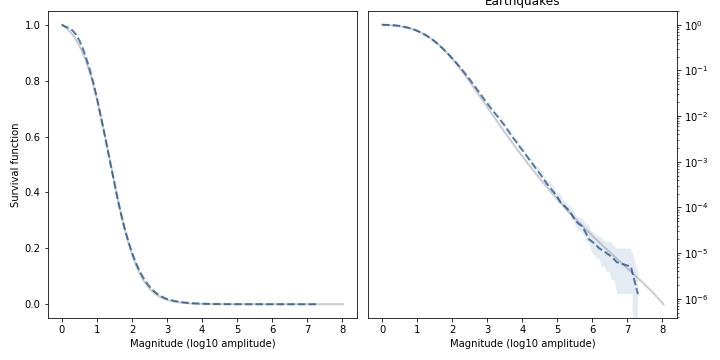
Here’s the distribution of earthquake magnitudes in California (the Richter scale is already logarithmic, so no need to transform).
Again, the model fits the survival function well over the entire range, and also fits the tail over almost six orders of magnitude.
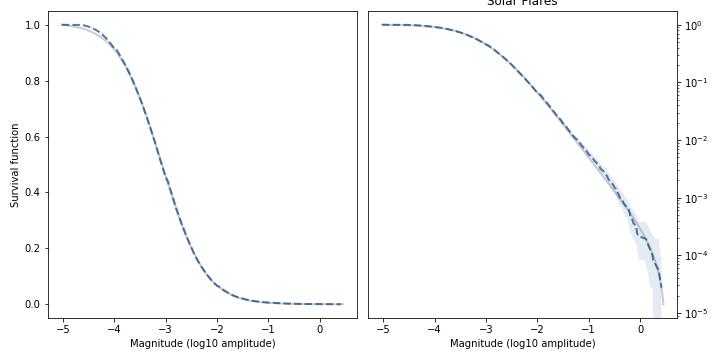
As another example, here’s the distribution of magnitudes for solar flares (logarithms of integrated flux in J/m²):
Again, the model fits the data well in the body and the tail of the distribution. At the top of the left figure, we can see that there are not as many small-magnitude flares as the model expects, but that might be because we don’t detect all of them.
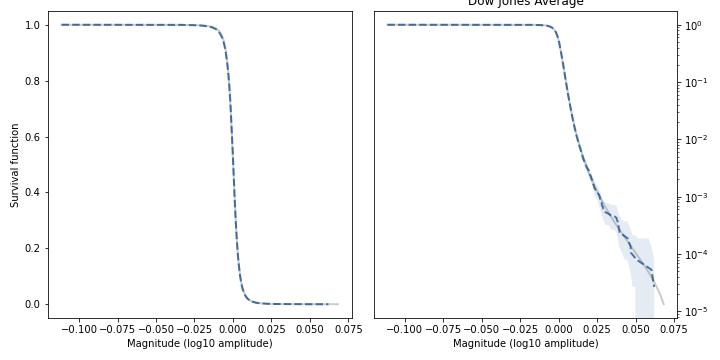
Finally, here are the relative changes in the daily closing price of the Dow Jones Industrial Average (thanks to Samuel H. Williamson), going all the way back to 1896.
The Student-t model is a remarkably good fit for the data.
Notably, the model is capable of matching tail curves with different shapes:
The tail of the city size distribution drops off with increasing curvature.
The tail of the earthquake distribution is initially curved and then straight.
The tail of the solar flare distribution is initially curved, then straight, then drops off again.
The tail of the changes in stock prices curves upward over a large part of the range.
You might think it would take a lot of parameters to track these different shapes, but the Student-t model has only three: location, scale, and tail thickness. It’s a bit of a pain to fit the model to data — I had to break out some optimization tools from SciPy. But at least I didn’t have to fit it by hand.
I’m not sure how much of this discussion will end up in the book, but if you would like to receive infrequent notifications about Probably Overthinking It (and possibly a discount), please sign up for this mailing list.
This article is an excerpt from the current draft of my book Probably Overthinking It, to be published by the University of Chicago Press in early 2023.
If you would like to receive infrequent notifications about the book (and possibly a discount), please sign up for this mailing list.
This book is intended for a general audience, so I explain some things that might be familiar to readers of this blog – and I leave out the Python code. After the book is published, I will post the Jupyter notebooks with all of the details!
How tall are you? How long are your arms? How far it is from the radiale landmark on your right elbow to the stylion landmark on your right wrist?
You might not know that last one, but the U.S. Army does. Or rather, they know the answer for the 6068 members of the armed forces they measured at the Natick Soldier Center (just a few miles from my house) as part of the Anthropometric Surveys of 2010-2011, abbreviated army-style as ANSUR-II.
In addition to the radiale-stylion length of each participant, the ANSUR dataset includes 93 other measurements “chosen as the most useful ones for meeting current and anticipated Army and [Marine Corps] needs.” The results were declassified in 2017 and are available to download from the Open Design Lab at Penn State.
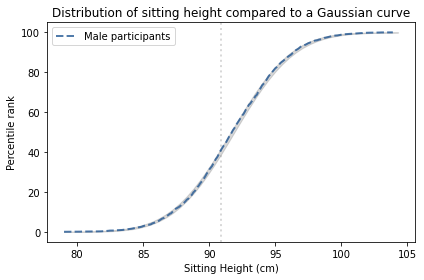
Measurements like the ones in the ANSUR dataset tend to follow a Gaussian distribution. As an example, let’s look at the sitting height of the male participants, which is the “vertical distance between a sitting surface and the top of the head.” The following figure shows the distribution of these measurements as a dashed line and the Gaussian model as a shaded area.
The width of the shaded area shows the variability we would expect from a Gaussian distribution with this sample size. The distribution falls entirely within the shaded area, which indicates that the model is consistent with the data.
To quantify how well the model fits the data, I computed the maximum vertical distance between them; in this example, it is 0.26 percentile ranks, at the location indicated by the vertical dotted line. The deviation is barely visible.
Why should measurements like this follow a Gaussian distribution? The answer comes in three parts:
Physical characteristics like height depend on many factors, both genetic and environmental.
The contribution of these factors tends to be additive; that is, the measurement is the sum of many contributions.
In a randomly-chosen individual, the set of factors they have inherited or experienced is effectively random.
According to the Central Limit Theorem, the sum of a large number of random values follows a Gaussian distribution. Mathematically, the theorem is only true if the random values come from the same distribution and they are not correlated with each other.
Of course, genetic and environmental factors are more complicated than that. In reality, some contributions are bigger than others, so they don’t all come from the same distribution. And they are likely to be correlated with each other. And their effects are not purely additive; they can interact with each other in more complicated ways.
However, even when the requirements of the Central Limit Theorem are not met exactly, the combined effect of many factors will be approximately Gaussian as long as:
None of the contributions are much bigger than the others,
The correlations between them are not too strong,
The total effect is not too far from the sum of the parts.
Many natural systems satisfy these requirements, which is why so many distributions in the world are approximately Gaussian.
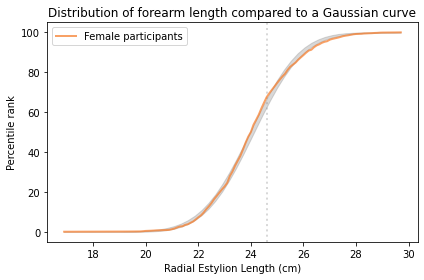
However, there are exceptions. In the ANSUR dataset, the measurement that is the worst match to the Gaussian model is the forearm length of the female participants, which is the distance I mentioned earlier between the radiale landmark on the right elbow and the stylion landmark on the right wrist.
The following figure shows the distribution of these measurements and a Gaussian model.
The maximum vertical distance between them is 4.2 percentile ranks, at the location indicated by the vertical dotted line; it looks like there are more measurements between 24 and 25 cm than we would expect in a Gaussian distribution.
There are two ways to think about this difference between the data and the model. One, which is widespread in the history of statistics and natural philosophy, is that the model represents some kind of ideal, and if the world fails to meet this ideal, the fault lies in the world, not the model.
In my opinion, this is nonsense. The world is complicated. Sometimes we can describe it with simple models, and it is often useful when we can. Sometimes, as in this case, a simple model fits the data surprisingly well. And when that happens, sometimes we find a reason the model works so well, which helps to explain why the world is as it is. But when the world deviates from the model, that’s a problem for the model, not a deficiency of the world.
Differences and Mixtures
I have cut the following section from the book. I still think it’s interesting, but it was in the way of more important things. Sometimes you have to kill your darlings.
So far I have analyzed measurements from male and female participants separately, and you might have wondered why. For some of these measurements, the distributions for men and women are similar, and if we combine them, the mixture is approximately Gaussian. But for some of them the distributions are substantially different; if we combine them, the result is not very Gaussian at all.
To show what that looks like, I computed the distance between the male and female distributions for each measurement and identified the distributions that are most similar and most different.
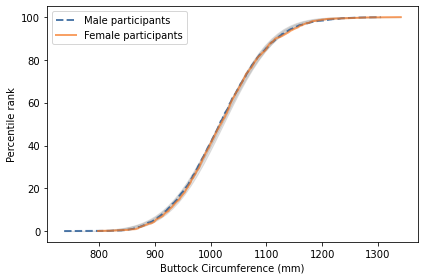
The measurement with the smallest difference between men and women is “buttock circumference”, which is “the horizontal circumference of the trunk at the level of the maximum protrusion of the right buttock”. The following figure shows the distribution of this measurement for men and women.
The two distributions are nearly identical, and both are well-modeled by a Gaussian distribution. As a result, if we combine measurements from men and women into a single distribution, the result is approximately Gaussian.
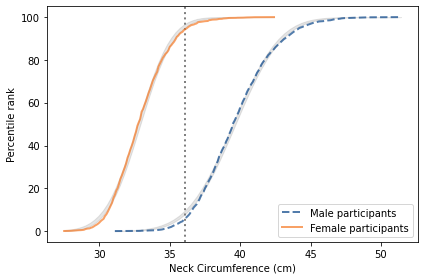
The measurement with the biggest difference between men and women is “neck circumference”, which is the circumference of the neck at the point of the thyroid cartilage. The following figure shows the distributions of this measurement for the male and female participants.
The difference is substantial. The average for women is 33 cm; for men it is 40 cm. The protrusion of the thyroid cartilage has been known since at least the 1600s as an “Adam’s apple”, named for the masculine archetype of the Genesis creation narrative. The origin of the term suggests that we are not the first to notice this difference.
There is some overlap between the distributions; that is, some women have thicker necks than some men. Nevertheless, if we choose a threshold between the two means, shown as a vertical line in the figure, we find fewer than 6% of women above the threshold, and fewer than 6% of men below it.
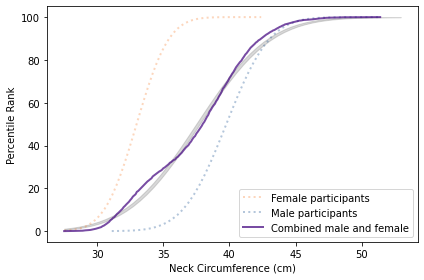
The following figure shows the distribution of neck size if we combine the male and female participants into a single sample.
The result is a distribution that deviates substantially from the Gaussian model. This example shows one of several reasons we find non-Gaussian distributions in nature: mixtures of populations with different means. That’s why Gaussian distributions are generally found within a species. If we combine measurements from different species, we should not expect Gaussian distributions.
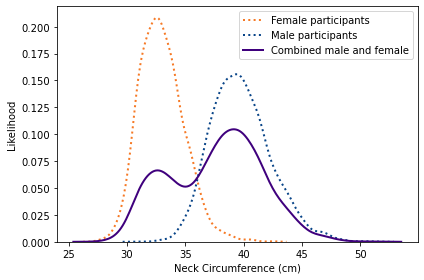
Although I generally recommend CDFs as the best ways to visualize distributions, mixtures like this might be an exception. As an alternative, here is a KDE plot of the combined male and female measurements.
This view shows more clearly that the combined distribution is a mixture of distributions with different means; as a result, the mixture has two distinct peaks, known as modes.
In subsequent chapters we’ll see other distributions that deviate from the Gaussian model and develop models to explain where they come from.
If you would like to get infrequent email announcements about my book, please sign up below. I’ll let you know about milestones, promotions, and other news, but not more than one email per month. I will not share your email or use this list for any other purpose.
I have not posted a new article for a few months, and I am now happy to announce the reason: I am working on a book! The working title is, of all things, Probably Overthinking It. If things go according to plan, it will be published by the University of Chicago Press in early 2023.
When I started, I thought it would be a collection of articles from this blog, but I ended up writing more new material than I expected. But it’s going well; out of 12 chapters, I have a solid draft of 10 and a pretty good idea what will go in the other two.
Over the next few months, I will publish excerpts here, but for now I am working at maximum speed to get a complete first draft to the technical reviewers.
So, sorry for going quiet, but it will be worth the wait!
If you would like to get infrequent email announcements about my book, please sign up below. I’ll let you know about milestones, promotions, and other news, but not more than one email per month. I will not share your email or use this list for any other purpose.
Data Structures and Information Retrieval in Python
I am happy to announce the first release of a new book, Data Structures and Information Retrieval in Python, which is an introduction to data structures organized around a motivating example: building a search engine.
The elements of the search engine are the Crawler, which downloads web pages and follows links to other pages, the Indexer, which builds a map from each word to the pages where it appears, and the Retriever, which looks up search terms and finds pages that maximize relevance and quality.
The index is stored in Redis, which is a NoSQL database that provides data structures like sets, lists, and hashmaps. The book presents each data structure first in Python, then in Redis, which should help readers see which features are essential and which are implementation details.
The book is loosely based on Think Data Structures, which uses Java. When I started, I thought it would be a translation, but the changes were so pervasive, I ended up writing it from scratch.
As I did with Think Bayes, I wrote this book entirely in Jupyter notebooks, and used JupyterBook to translate them to HTML. The notebooks run on Colab, which is a service provided by Google that runs notebooks in a browser. So you can read the book, run the code, and work on exercises without installing anything.
Why?
I have mixed feelings about data structures. In the computer science curriculum, it is often used as a weed-out class, and in the technical interview process, it is used as a gatekeeper. In both cases, it plays a disproportionate role in determining who studies computer science and who gets jobs in the field.
And it tends to be a bad class. The material is presented theoretically, without context or application, organized in a way that seems designed to maximize tedium, and often taught badly. The goals of the course are ambiguous — is it about theoretical foundations or programming proficiency? — and the result is often a hybrid that does nothing well.
Also, it has not kept up with changes in the software landscape. When people were learning to program in C, it might have been appropriate to focus on the implementation of data structures. But for people learning Python, it’s probably better to learn how to use them first, and see how they are implemented when (and if) necessary.
Despite my misgivings about the material, in 2016 I found myself designing a data structures curriculum for the Flatiron School, on behalf of a large software company. In 2017 I updated the curriculum and published Think Data Structures. But the software curriculum at Olin uses more Python than Java, so I have not used the Java version in a class.
Since I was scheduled to teach Data Structures this fall, I decided to write a Python version. I started last August with an outline and about 10 notebooks in various stages of completion. I developed the rest of the material during the semester, staying about a week ahead of the students.
Now there are 29 notebooks including 22 that present the material and 7 quizzes that include practice questions. I hope people will find it useful!
In the first edition of Think Bayes, I presented what I called the Geiger counter problem, which is based on an example in Jaynes, Probability Theory. But I was not satisfied with my solution or the way I explained it, so I cut it from the second edition.
I am re-reading Jaynes now, following the excellent series of videos by Aubrey Clayton, and this problem came back to haunt me. On my second attempt, I have a solution that is much clearer, and I think I can explain it better.
We have a radioactive source … which is emitting particles of some sort … There is a rate p, in particles per second, at which a radioactive nucleus sends particles through our counter; and each particle passing through produces counts at the rate θ. From measuring the number {c1 , c2 , …} of counts in different seconds, what can we say about the numbers {n1 , n2 , …} actually passing through the counter in each second, and what can we say about the strength of the source?
As a model of the source, Jaynes suggests we imagine “N nuclei, each of which has independently the probability r of sending a particle through our counter in any one second”. If N is large and r is small, the number of particles emitted in a given second is well modeled by a Poisson distribution with parameter s=Nr, where s is the strength of the source.
As a model of the sensor, we’ll assume that “each particle passing through the counter has independently the probability ϕ of making a count”. So if we know the actual number of particles, n, and the efficiency of the sensor, ϕ, the distribution of the count is Binomial(n,ϕ).
With that, we are ready to solve the problem. Following Jaynes, I’ll start with a uniform prior for s, over a range of values wide enough to cover the region where the likelihood of the data is non-negligible. To represent distributions, I’ll use the Pmf class from empiricaldist.
ss = np.linspace(0, 350, 101)
prior_s = Pmf(1, ss)
For each value of s, the distribution of n is Poisson, so we can form the joint prior of s and n using the poisson function from SciPy. The following function creates a Pandas DataFrame that represents the joint prior.
The result is a DataFrame with one row for each value of n and one column for each value of s.
To update the prior, we need to compute the likelihood of the data for each pair of parameters. However, in this problem the likelihood of a given count depends only on n, regardless of s, so we only have to compute it once for each value of n. Then we multiply each column in the prior by this array of likelihoods. The following function encapsulates this computation, normalizes the result, and returns the posterior distribution.
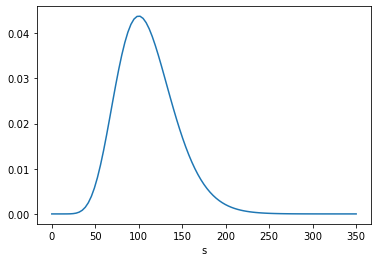
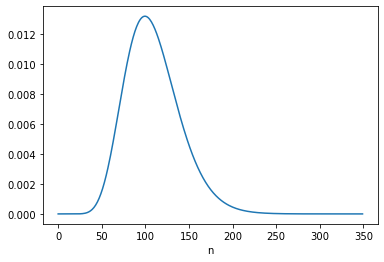
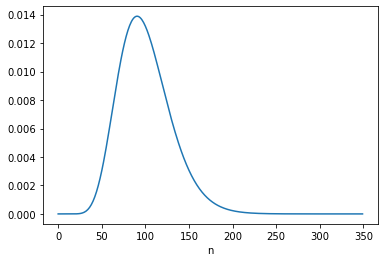
The following figures show the posterior marginal distributions of s and n.
posterior_s = marginal(posterior, 0)
posterior_n = marginal(posterior, 1)
The posterior mean of n is close to 109, which is consistent with Equation 6.116. The MAP is 99, which is one less than the analytic result in Equation 6.113, which is 100. It looks like the posterior probabilities for 99 and 100 are the same, but the floating-point results differ slightly.
Jeffreys prior
Instead of a uniform prior for s, we can use a Jeffreys prior, in which the prior probability for each value of s is proportional to 1/s. This has the advantage of “invariance under certain changes of parameters”, which is “the only correct way to express complete ignorance of a scale parameter.” However, Jaynes suggests that it is not clear “whether s can properly be regarded as a scale parameter in this problem.” Nevertheless, he suggests we try it and see what happens. Here’s the Jeffreys prior for s.
prior_jeff = Pmf(1/ss[1:], ss[1:])
We can use it to compute the joint prior of s and n, and update it with c1.
The posterior mean is close to 100 and the MAP is 91; both are consistent with the results in Equation 6.122.
Robot A
Now we get to what I think is the most interesting part of this example, which is to take into account a second observation under two models of the scenario:
Two robots, [A and B], have different prior information about the source of the particles. The source is hidden in another room which A and B are not allowed to enter. A has no knowledge at all about the source of particles; for all [it] knows, … the other room might be full of little [people] who run back and forth, holding first one radioactive source, then another, up to the exit window. B has one additional qualitative fact: [it] knows that the source is a radioactive sample of long lifetime, in a fixed position.
In other words, B has reason to believe that the source strength s is constant from one interval to the next, while A admits the possibility that s is different for each interval. The following figure, from Jaynes, represents these models graphically.
For A, the “different intervals are logically independent”, so the update with c2 = 16 starts with the same prior.
c2 = 16
posterior2 = update(joint, phi, c2)
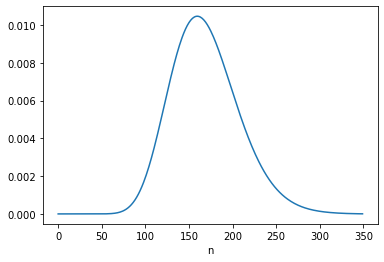
Here’s the posterior marginal distribution of n2.
The posterior mean is close to 169, which is consistent with the result in Equation 6.124. The MAP is 160, which is consistent with Equation 6.123.
Robot B
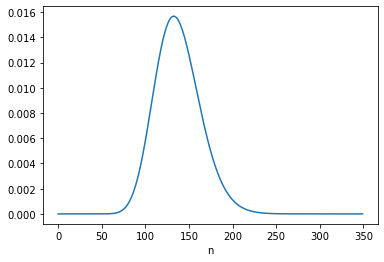
For B, the “logical situation” is different. If we consider s to be constant, we can – and should! – take the information from the first update into account when we perform the second update. We can do that by using the posterior distribution of s from the first update to form the joint prior for the second update, like this:
The posterior mean of n is close to 137.5, which is consistent with Equation 6.134. The MAP is 132, which is one less than the analytic result, 133. But again, there are two values with the same probability except for floating-point errors.
Under B’s model, the data from the first interval updates our belief about s, which influences what we believe about n2.
Going the other way
That might not seem surprising, but there is an additional point Jaynes makes with this example, which is that it also works the other way around: Having seen c2, we have more information about s, which means we can – and should! – go back and reconsider what we concluded about n1.
We can do that by imagining we did the experiments in the opposite order, so
We’ll start again with a joint prior based on a uniform distribution for s
Update it based on c2,
Use the posterior distribution of s to form a new joint prior,
The posterior mean is close to 131.5, which is consistent with Equation 6.133. And the MAP is 126, which is one less than the result in Equation 6.132, again due to floating-point error.
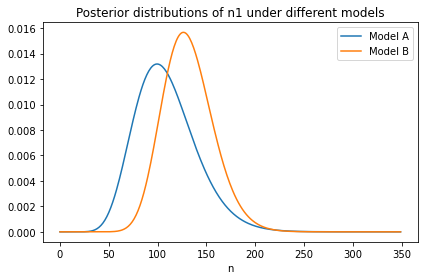
Here’s what the new distribution of n1 looks like compared to the original, which was based on c1 only.
With the additional information from c2:
We give higher probability to large values of s, so we also give higher probability to large values of n1, and
The width of the distribution is narrower, which shows that with more information about s, we have more information about n1.
Discussion
This is one of several examples Jaynes uses to distinguish between “logical and causal dependence.” In this example, causal dependence only goes in the forward direction: “s is the physical cause which partially determines n; and then n in turn is the physical cause which partially determines c”.
Therefore, c1 and c2 are causally independent: if the number of particles counted in one interval is unusually high (or low), that does not cause the number of particles during any other interval to be higher or lower.
But if s is unknown, they are not logically independent. For example, if c1 is lower than expected, that implies that lower values of s are more likely, which implies that lower values of n2 are more likely, which implies that lower values of c2 are more likely.
And, as we’ve seen, it works the other way, too. For example, if c2 is higher than expected, that implies that higher values of s, n1, and c1 are more likely.
If you find the second result more surprising – that is, if you think it’s weird that c2 changes what we believe about n1 – that implies that you are not (yet) distinguishing between logical and causal dependence.